






这里写自定义目录标题
ES学习
由于项目种经常会用到ES和solr,因此此文章记录学习相关知识以及实操。

关于搜索引擎
1.什么是全文搜索引擎?
全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
2.为什么要用全文搜索搜索引擎?
所有数据在数据库里面都有,而且 Oracle、SQL Server 等数据库里也能提供查询检索或者聚类分析功能,直接通过数据库查询不就可以了吗?
确实,我们大部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过建数据库索引,优化SQL等方式进行提升效率,甚至通过引入缓存来加快数据的返回速度。如果数据量更大,就可以分库分表来分担查询压力。
| 数据类型 | 索引的维护 | ||
|---|---|---|---|
| 全文索引搜索支持非结构化数据的搜索,可以更好地快速搜索大量存在的任何单词或单词组的非结构化文本。例如 Google,百度类的网站搜索,它们都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。 | 一般传统数据库,全文检索都实现得很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。 |
3.什么时候使用全文搜索引擎
搜索的数据对象是大量的非结构化的文本数据。
文件记录量达到数十万或数百万个甚至更多。
支持大量基于交互式文本的查询。
需求非常灵活的全文搜索查询。
对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。
Lucene
现在主流的搜索引擎大概就是:Lucene,Solr,ElasticSearch。
它们的索引建立都是根据倒排索引的方式生成索引,何谓倒排索引?
维基百科:
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
Lucene是一个Java全文搜索引擎,完全用Java编写。Lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能。
Lucene通过简单的API提供强大的功能:
| 可扩展的高性能索引 | 强大,准确,高效的搜索算法 | ||
|---|---|---|---|
| 在现代硬件上超过150GB /小时 小RAM要求 - 只有1MB堆增量索引与批量索引一样快 索引大小约为索引文本大小的20-30% | 排名搜索 - 首先返回最佳结果 许多强大的查询类型:短语查询,通配符查询,邻近查询,范围查询等 现场搜索(例如标题,作者,内容) 按任何字段排序 使用合并结果进行多索引搜索 允许同时更新和搜索 灵活的分面,突出显示,连接和结果分组 快速,内存效率和错误容忍的建议 可插拔排名模型,包括矢量空间模型和Okapi BM25 可配置存储引擎(编解码器) | ||
ES
Elasticsearch是一个开源(Apache 2许可证),是一个基于Apache Lucene库构建的RESTful搜索引擎。
它提供了一个分布式,多租户能力的全文搜索引擎,具有HTTP Web界面(REST)和无架构JSON文档。分布式搜索引擎包括可以划分为分片的索引,并且每个分片可以具有多个副本。每个Elasticsearch节点都可以有一个或多个分片,其引擎也可以充当协调器,将操作委派给正确的分片。
solr
Apache Solr是一个基于名为Lucene的Java库构建的开源搜索平台。它以用户友好的方式提供Apache Lucene的搜索功能。是一个成熟的产品,拥有强大而广泛的用户社区。它提供分布式索引,复制,负载平衡查询以及自动故障转移和恢复。如果它被正确部署然后管理得好,它就能够成为一个高度可靠,可扩展且容错的搜索引擎。
比较
1、搜索速度
当单纯的对已有数据进行搜索时,Solr查询更快,更新索引时慢(即插入删除慢),用于电商等查询多的应用;;
ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
Solr缺点:当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后的平均查询速度有了50倍的提升。
2、分布式协调管理
Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
3、支持的数据格式
Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
4、搜索类型
Solr仍然更加面向文本搜索。另一方面,Elasticsearch 通常用于过滤和分组 - 分析查询工作负载 - 而不一定是文本搜索。Elasticsearch 开发人员在 Lucene 和 Elasticsearch 级别上投入了大量精力使此类查询更高效(降低内存占用和CPU使用)。
因此,对于不仅需要进行文本搜索,而且需要复杂的搜索时间聚合的应用程序,Elasticsearch是一个更好的选择。
实操
1、下载es-head插件
Head 插件,全称为 elasticsearch-head,是一个界面化的集群操作和管理工具,可以对集群进行“傻瓜式”操作。
既可以把 Head 插件集成到 Elasticsearch 中,也可以把 Head 插件当成-个独立服务。
主要功能:
显示es集群的拓扑结构,能够执行索引和节点级别的操作。
在搜索接口能够查询es集群中原始JSON 或表格格式的数据。
能够快速访问并显示es集群的状态。
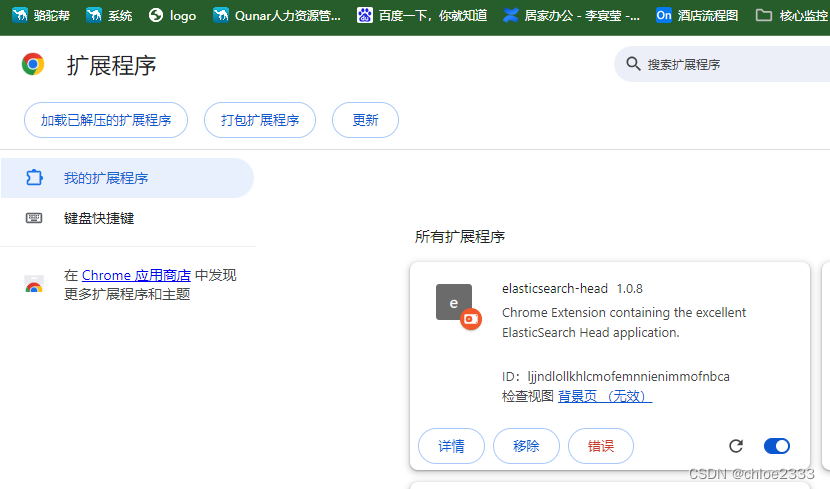
2、加入到浏览器插件扩展程序
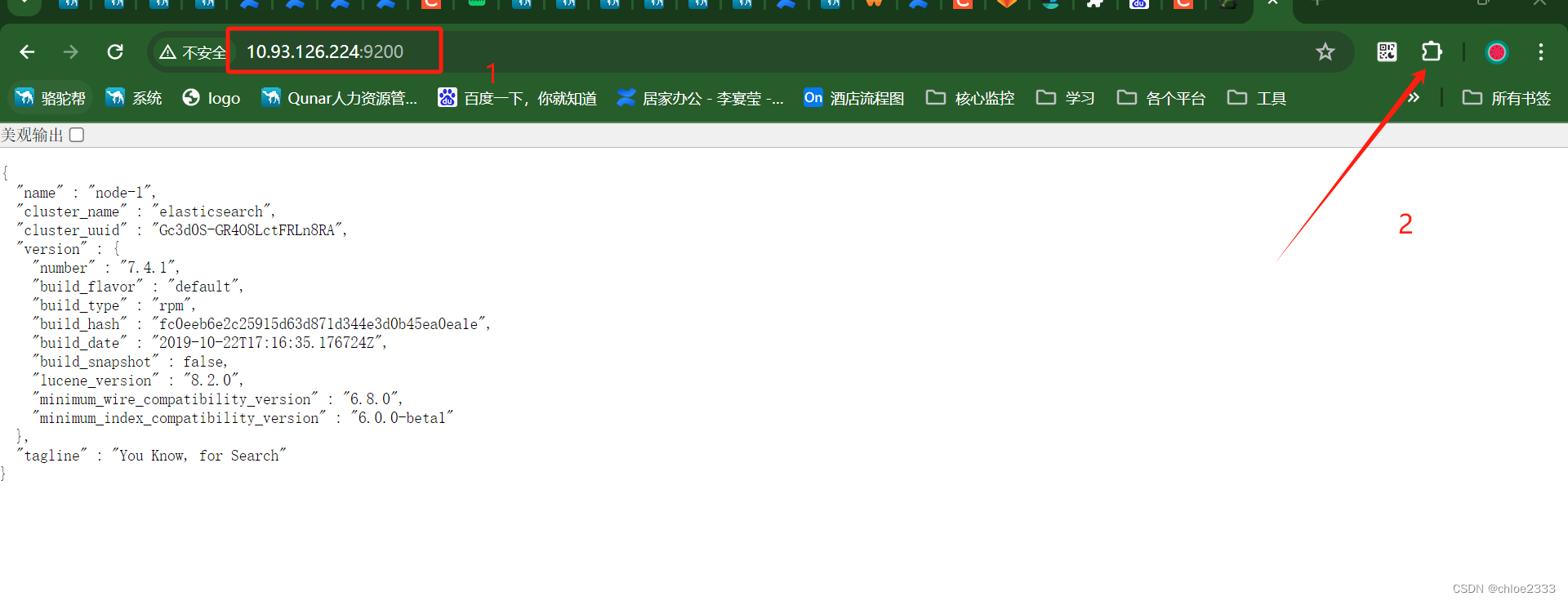
3、访问地址
3.2.1 概览页
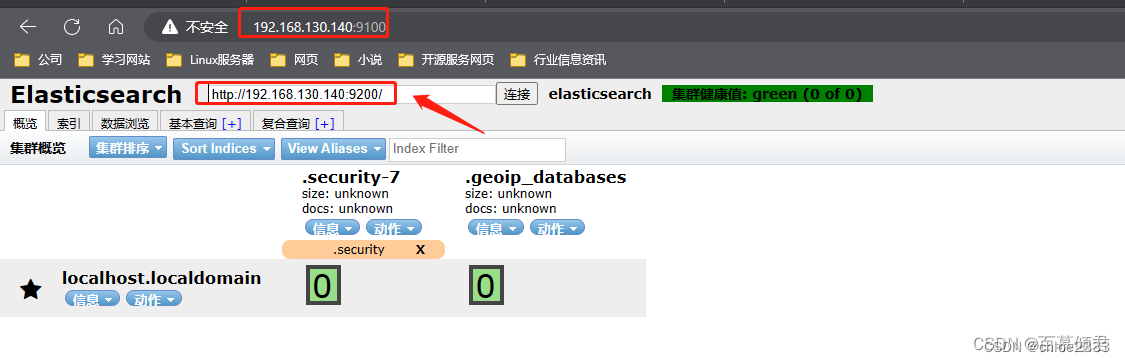
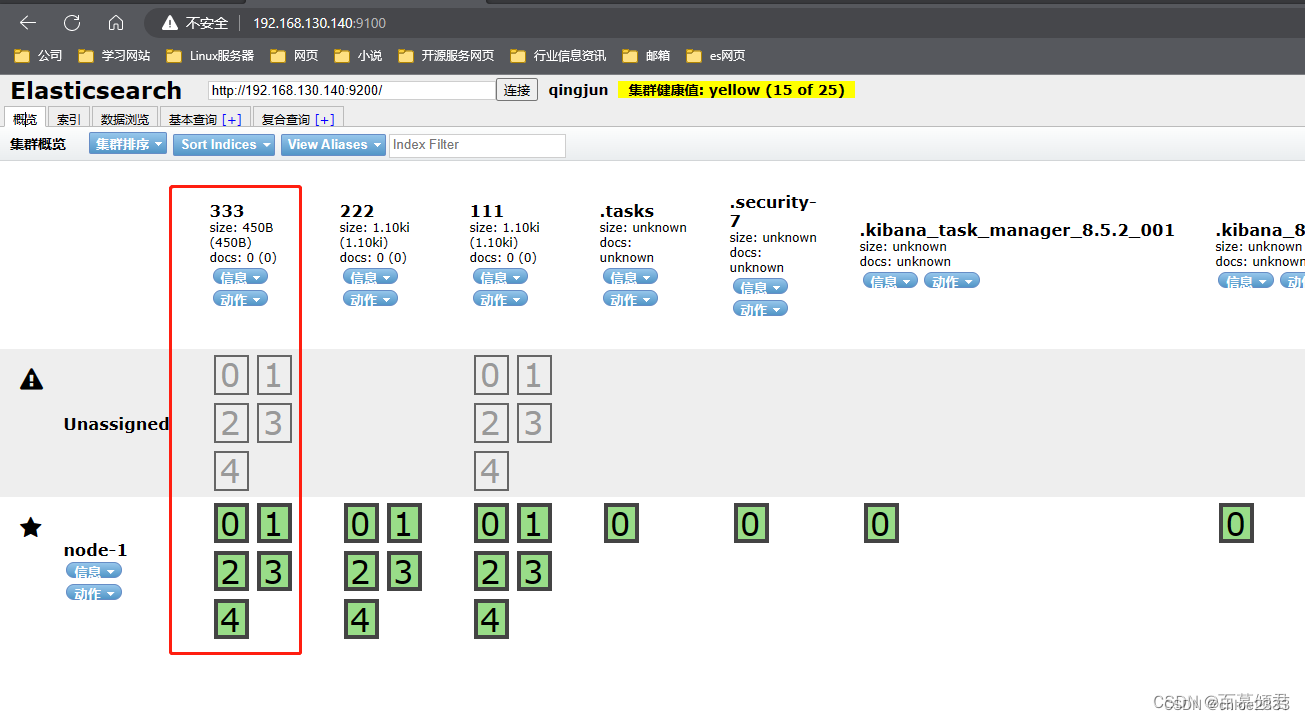
第一部分:节点地址输入区域。这里输入es集群任意一个节点IP就可以查看集群所有状态和数据。
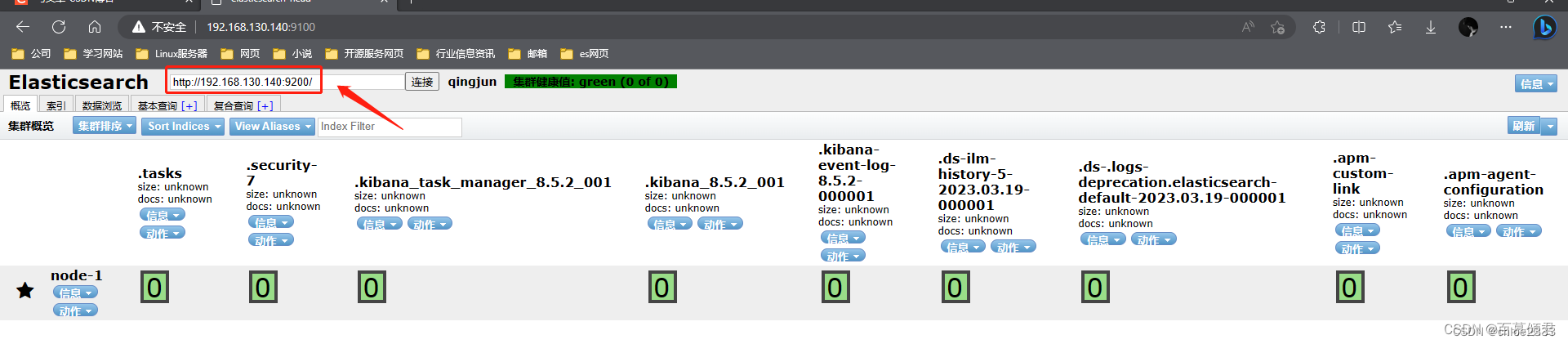
第二部分:信息刷新区域。
刷新区域可以查看es相关的信息和刷新插件的信息。
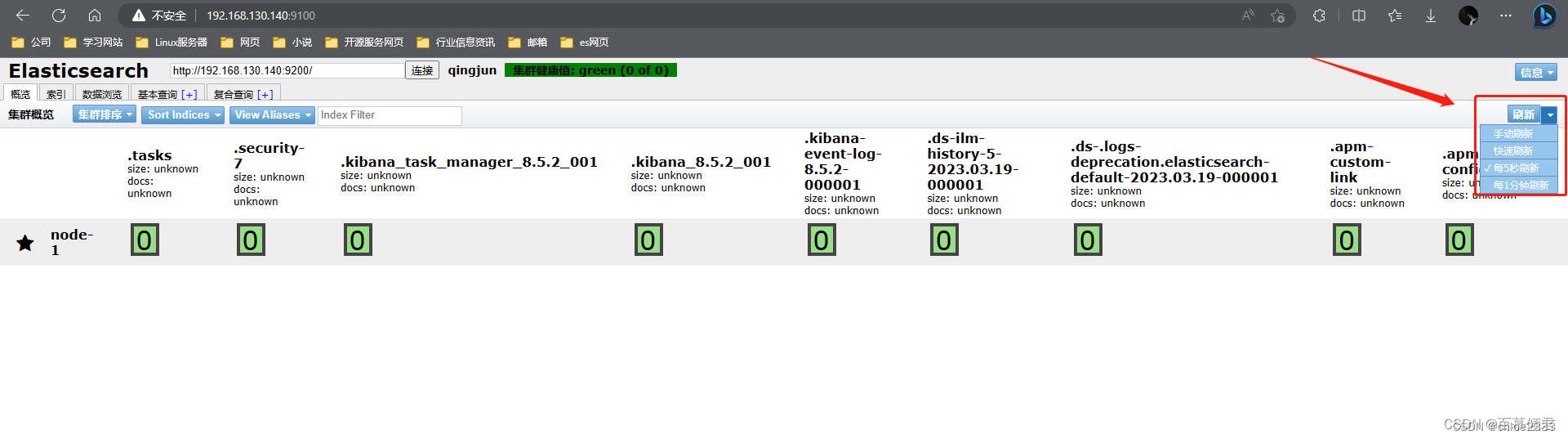
- 信息区域可以看到es相关的信息,包括集群节点信息、节点状态、集群状态集群信息、集群健康值等内容。单击对应的按钮,即可查看对应的信息。
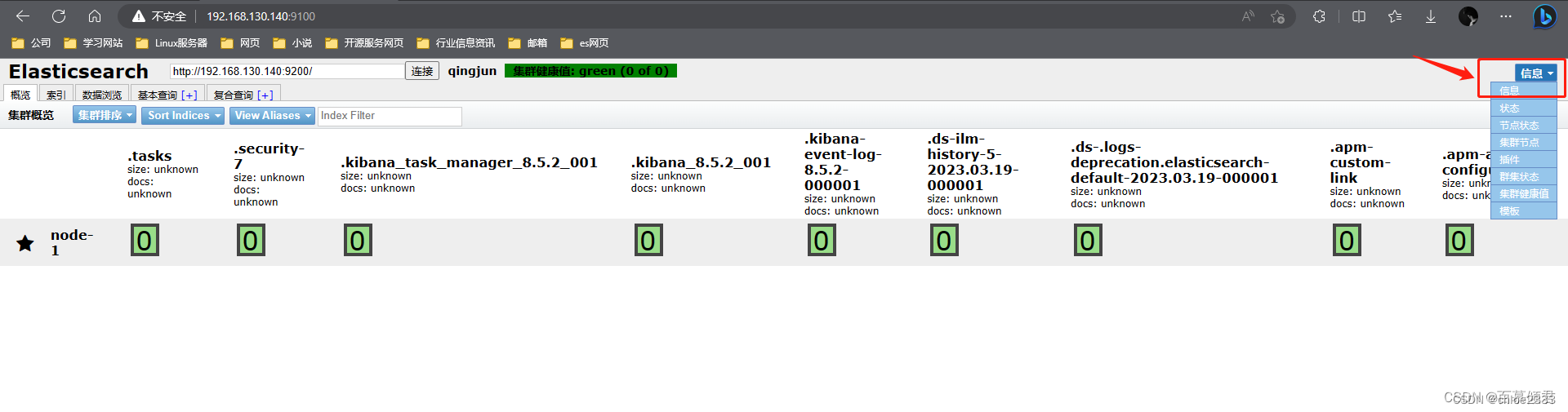
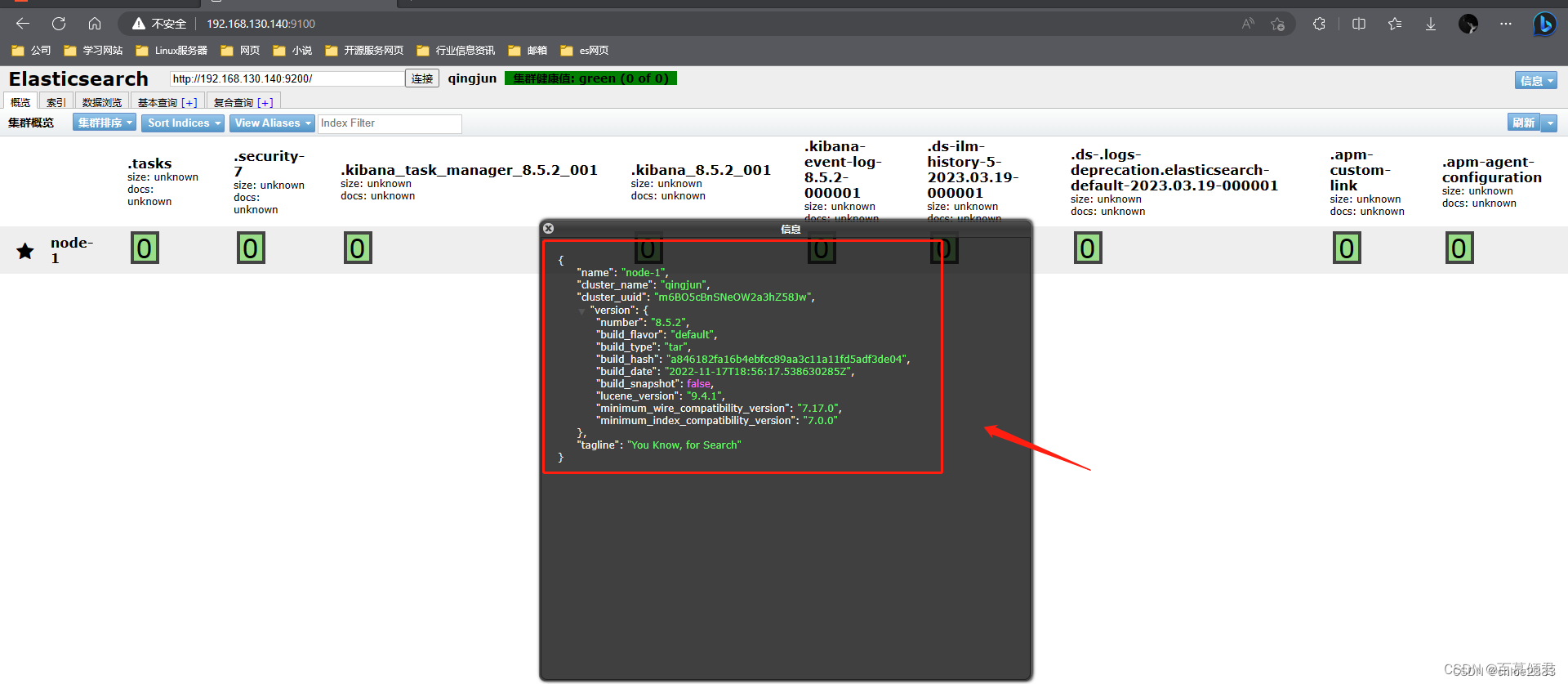
第三部分:导航条。看到概览、索引、数据浏览、基本查询和复合查询五个 Tab 导航,默认为概览。

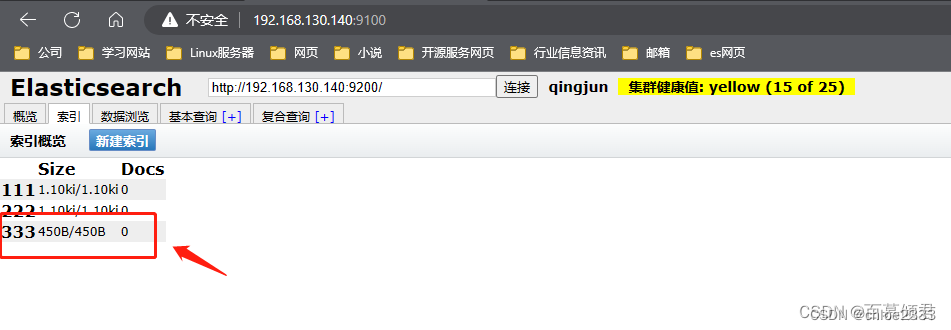
第四部分:概览中的集群信息汇总。可以看到es已经创建的索引,这些索引信息包含了索引的名称、索引的大小和索引的数据量,并且通过“信息”和“动作”两个按钮可以查看索引信息,或者给索引创建别名。
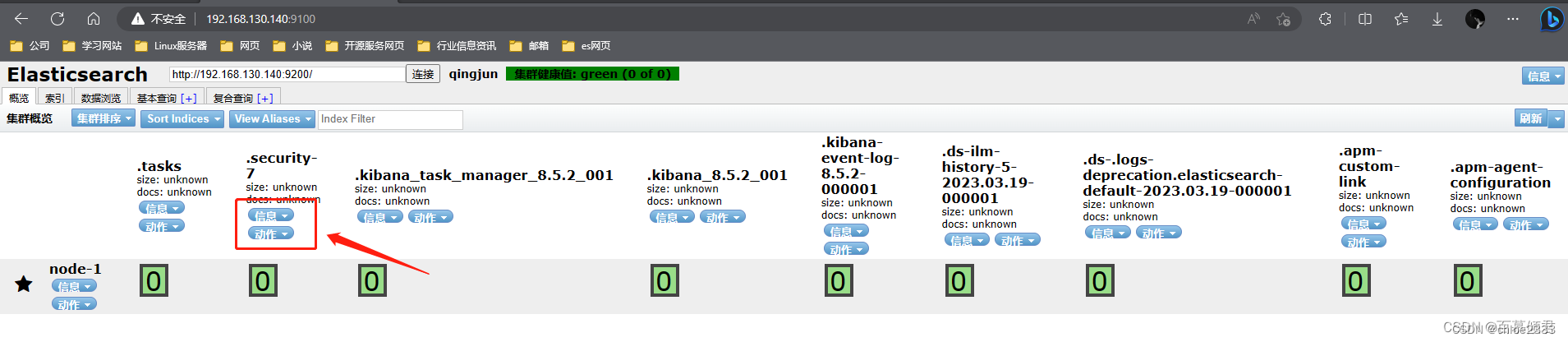
第五部分:集群健康值。es中有专门的衡量索引健康状况的标志,分为三个等级:
green,绿色。代表所有的主分片和副本分片都已分配,集群是 100% 可用的。
yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的,不会有数据丢失,所以搜索结果依然是完整的。不过高可用性在某种程度上会被弱化。如果更多的分片消失,就会丢数据了。可以把 yellow 想象成一个需要及时调查的警告。
red,红色。至少一个主分片以及它的全部副本都在缺失中。意味缺少数据,搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
当只有一台主机时,索引的健康状况是 yellow。因为一台主机,集群没有其他的主机可以做副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。
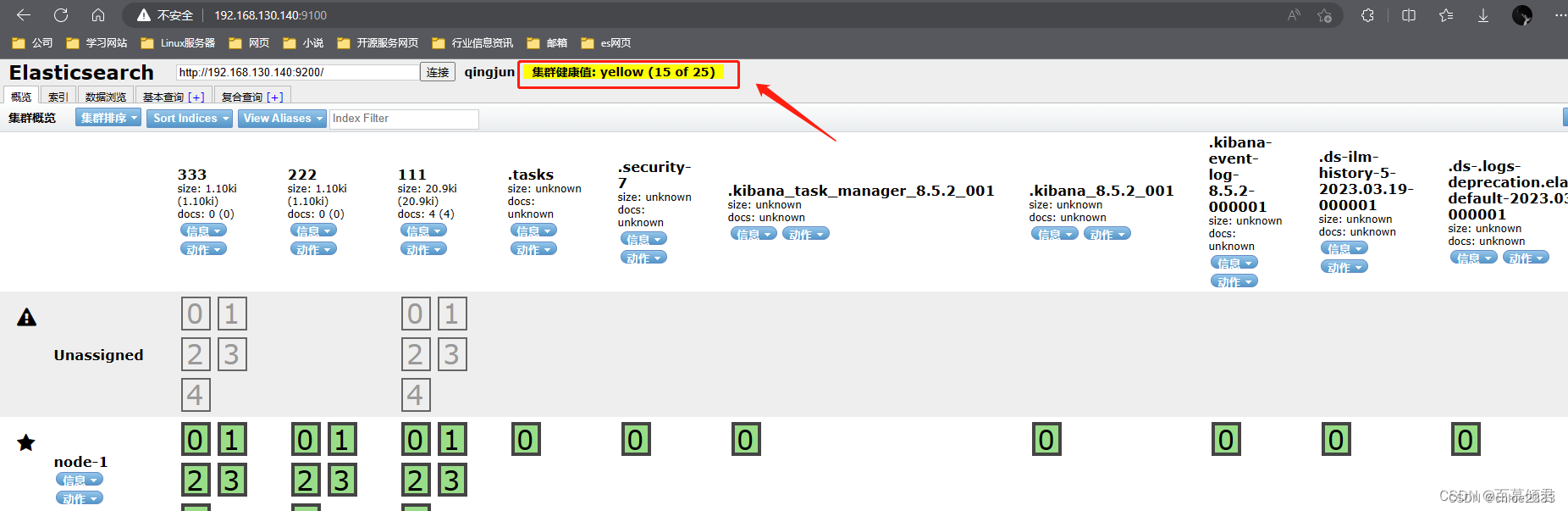
第六部分:索引分片。Elasticsearch数据就存储在这些分片中。每一个方框就是elasticsearch的分片,粗线方框是es的主分片,主分片旁边细线方框是es的备份分片,对应关系,粗线方框0的备份分片是细线方框0,以此类推。
3.2.1 索引页
可以查看当前es集群中的索引情况。
新建索引。
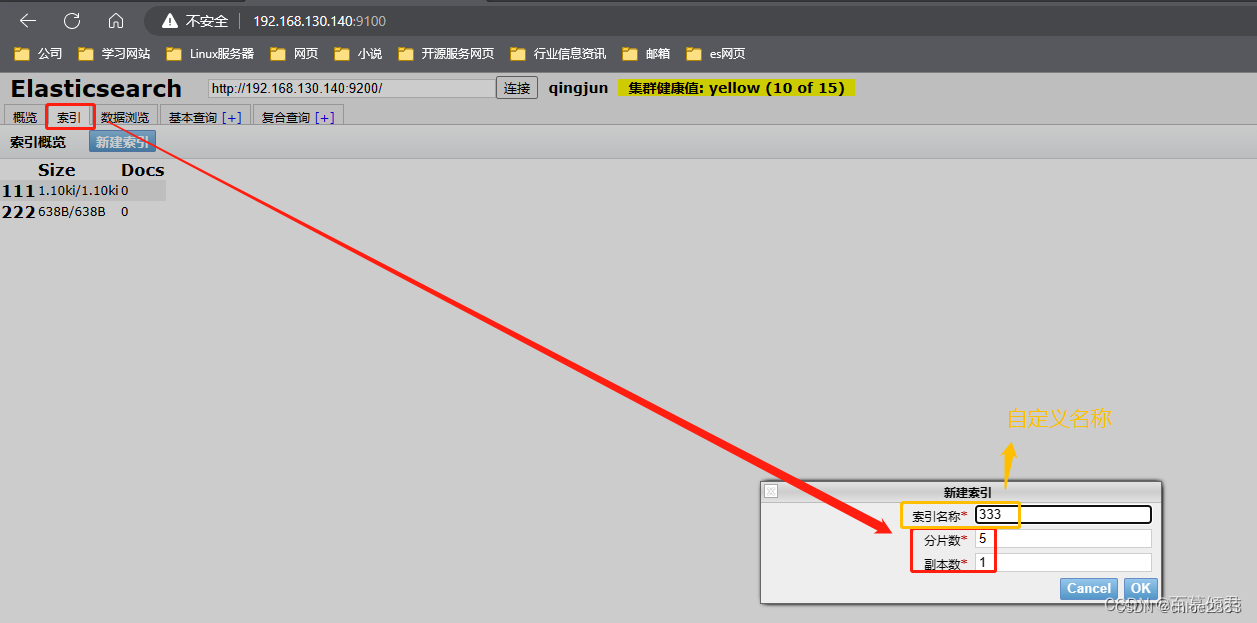
查看。
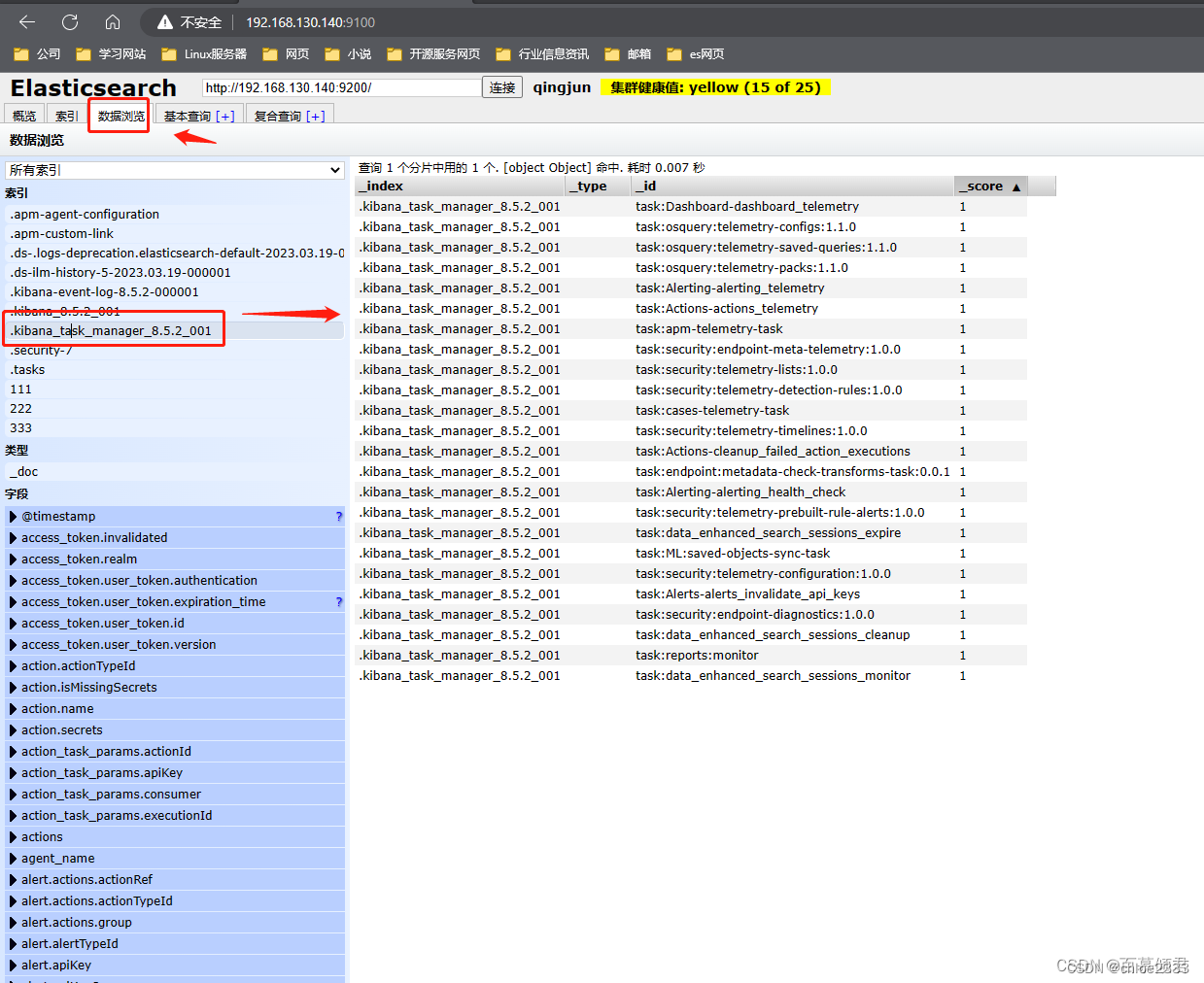
3.2.3 数据浏览页
可以查看特定索引下的数据。
##### 3.2.4 基本查询页
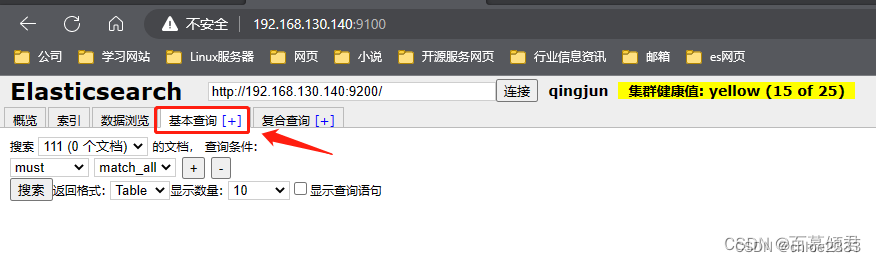
匹配方式:
must子句:文档必须匹配 must 查询条件,相当于“=”。
should子句:文档应该匹配 should 子查询的一个或多个条件。
must_not子句:文档不能匹配该查询条件,相当于“!=”。
term:表示的是精确匹配。
wildcard:表示的是通配符匹配。
prefix:表示的是前缀匹配。
range:表示的是区间查询
注意事项:
1、当用多个查询条件进行搜索或查询时,需要注意多个查询条件间的匹配方式。
2、匹配方式主要有3种,即must、should 和mus_not。
3、“+”“_”按用于增加查询条件或减少查询条件。
4、在查询结果展示区域中,用户可以设置数据的呈现形式,如 table、JSON、CVS 表格等还可以勾选“显示查询语句”选项,呈现通过表单内容拼接的搜索语句。
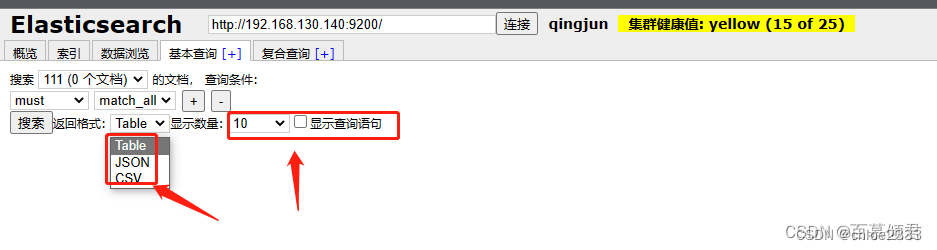
3.2.4.1 term指定查询
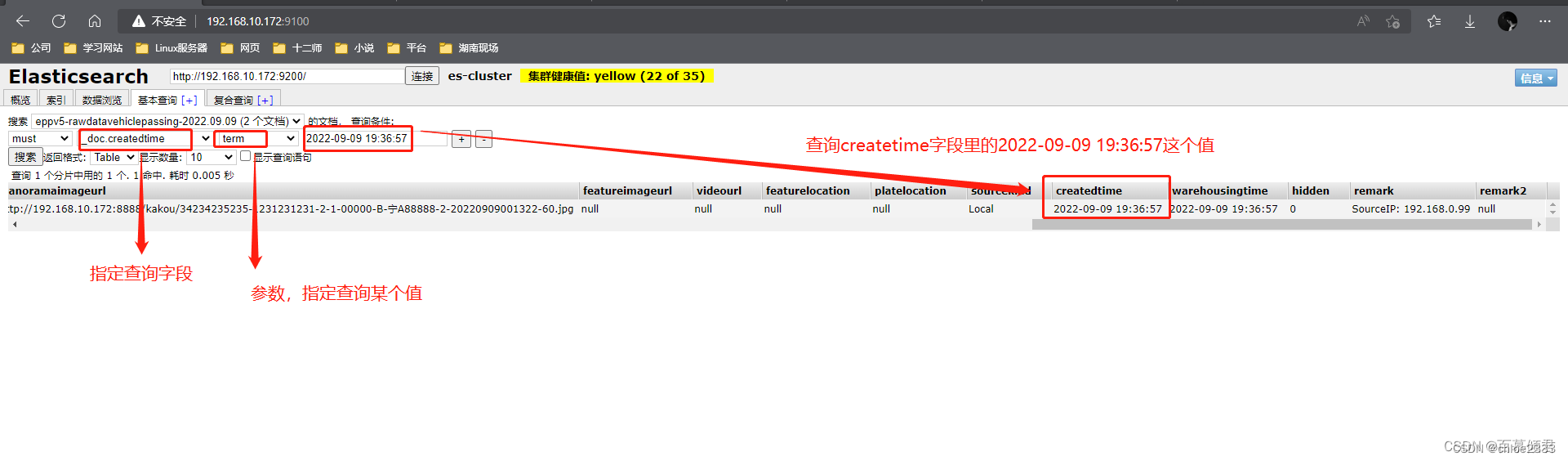
3.2.4.2 range范围查询
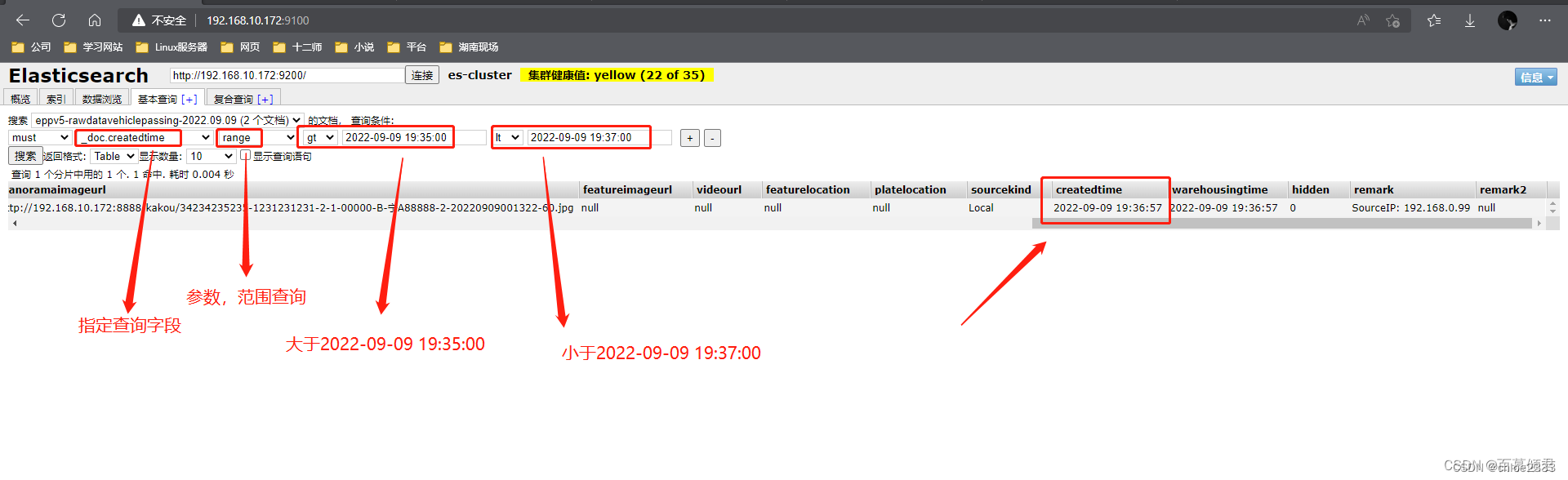
3.2.4.3 多条件查询
3.2.5 复合查询页
基本了解:
“复合查询”标签页可以自由拼接条件,进行复杂的数据查询。
“复合查询”标签页为用户提供了编写 RESTful接口风格的请求(http://ip:port/索引/类型/文档ID),用户可以使用JSON 进行复杂的查询,比如发送 PUT 请求新增及更新索引,使用 delete 请求删除索引等。
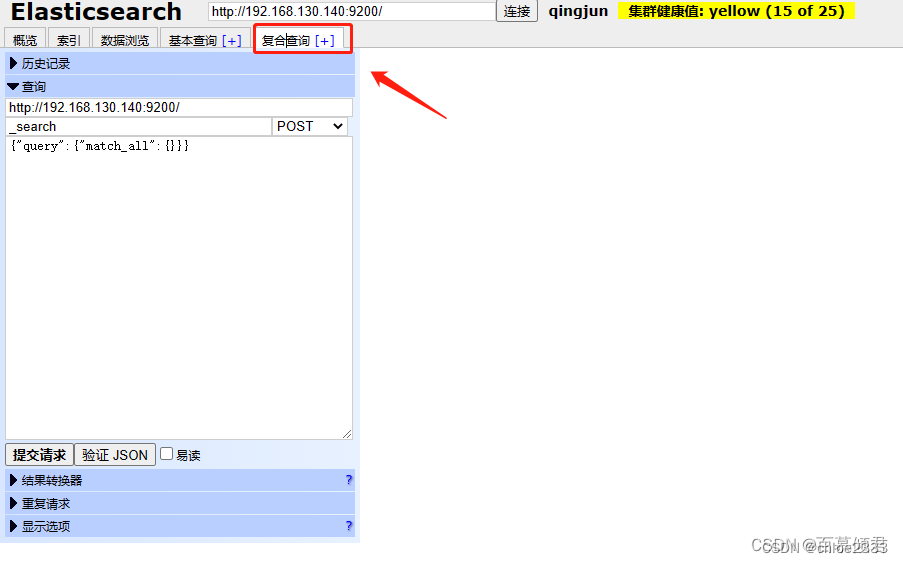
配置接口的四个选项:
1、在es中,以POST 方法自动生成ID,而 PUT 方法需要指明ID。
请求方法与HTTP 的请求方法相同,如 GET、PUT、POST、DELETE 等。
还可以配置查询JSON 请求数据、请求对应的es节点和请求路径。
2、支持配置JSON验证器对用户输入的JSON 请求数据进行JSON 格式校验。
3、支持重复请求计时器配置重复请求的频率和时间。
4、在结果转换器中支持使用 JavaScript 表达式变换结果。
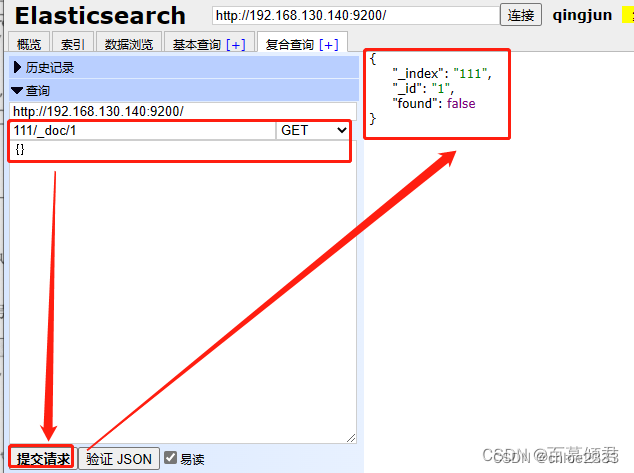
3.2.5.1 查询数据
查询。查询索引111中编号为1的文档。
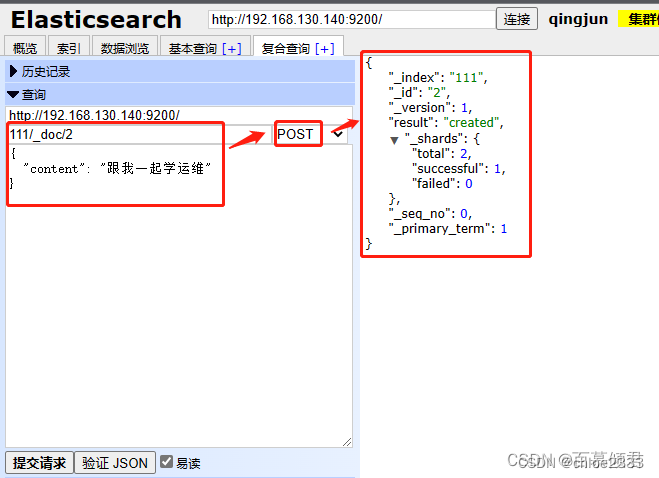
3.2.5.1 插入数据
新增数据有两种方式,POST和PUT,两者的区别就是POST自动生成文档编号,也可以指定,而PUT需要指定文档编号生成。
3.2.5.3 查询所有文档
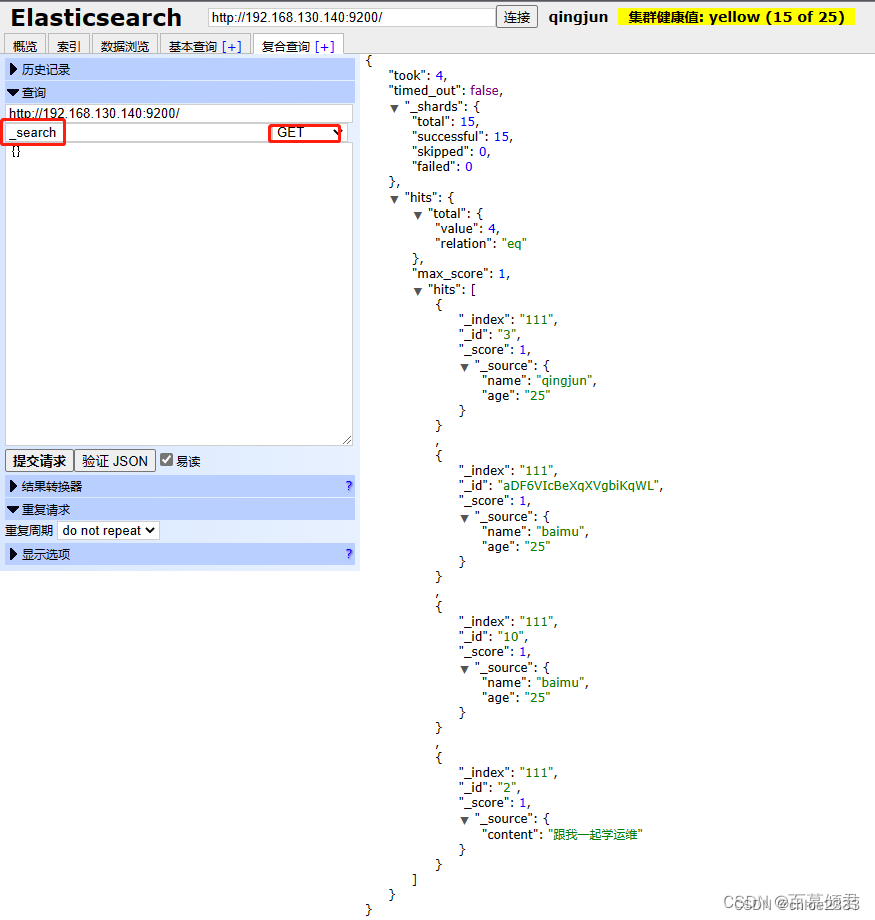
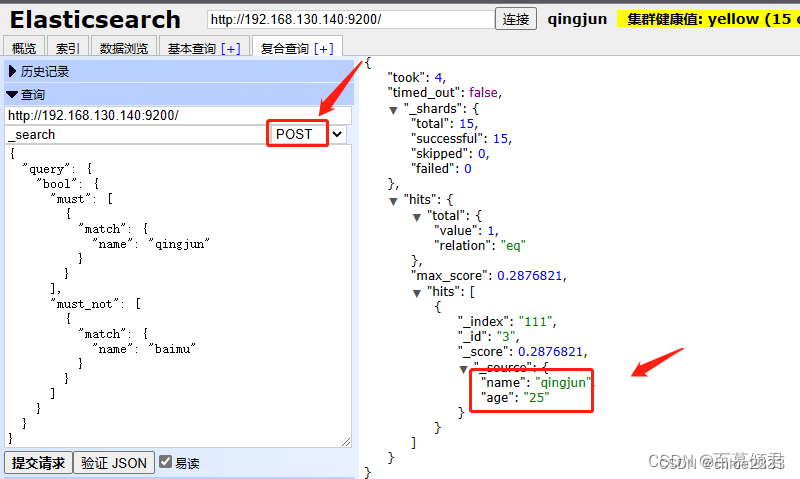
3.2.5.4 布尔查询
must:文档必须匹配这些条件才能被搜索出来。
must_not:文档必须不匹配这些条件才能被搜索出来。
should:如果满足这些语句中的任意语句,则将增加搜索排名结果 score; 否则,对查询结果无任何影响。其主要作用是修正每个文档的相关性得分。
filter:表示必须匹配,但它是以不评分的过滤模式进行的。这些语句对评分没有贡献只是根据过滤标准排除或包含文档。
注意事项:
如果没有 must 语句,那么需要至少匹配其中的一条 should 语句。但如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
查看匹配”qingjun“,且不匹配”baimu“的文档。
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "qingjun"
}
}
],
"must_not": [
{
"match": {
"name": "baimu"
}
}
]
}
}
}
原文链接:https://blog.csdn.net/yi_qingjun/article/details/129656671
原文链接:https://blog.csdn.net/2401_84166896/article/details/138328434
参考文章:
https://www.sohu.com/a/711889282_411876
https://blog.csdn.net/yi_qingjun/article/details/129656671
















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









