






方法和函数
处理数字
area = round(math.pi * (r**2), 2) # 方法round(number, 位数) 可以保留数字number的几位数
for number in range(begin, end+1): #方法range(a, b)从a到b-1,是不包含b的
开根号的三种方式:math.sqrt(数字)、 pow(数字,次方)、cmath.sqrt(数字):该方法多用于复数、负数的开方运算
——————————————————————————————————————————————————————————————
列表、字典的处理
列表解析的使用可以更简洁:
def remove_listb_from_lista(list1, list2):
for item in listb:
if item in lista:
lista.remove(item)
return lista
lista = [1, 2, 3, 4, 5]
listb = [1, 3, 5]
print(f"from {lista} remove {listb} result is ", remove_listb_from_lista(lista, listb))
# 或者用列表解析:
new_list = [item for item in lista if item not in listb]
print(f"from {lista} remove {listb} result is ", new_list)
————————————————————————————————————————————————————————
利用set()函数对列表进行去重:set()是一种无序不重复的元素集
def list_unique(lista):
result = []
for item in list1:
if item not in result:
result.append(item)
return result
list1 = [1, 1, 2, 2, 3, 3, 4, 5]
print(f"after delete same number the {list1} became : ", list_unique(list1))
# 或者用set()函数去重
print(f"after delete same number the {list1} became : ", list(set(list1)))
——————————————————————————————————————————————————————————
sort()、sorted()排序:
sorted 用于对集合进行排序(集合可以是列表、字典、set、甚至是字符串)
1、默认情况,sorted 函数将按列表升序进行排序,并返回一个新列表对象,原列表保持不变,最简单的排序
nums = [3,4,5,2,1]>>> sorted(nums)[1, 2, 3, 4, 5]
2、降序排序,如果要按照降序排列,只需指定参数 reverse=True 即可
sorted(nums, reverse=True)[5, 4, 3, 2, 1]
3、如果要按照某个规则排序,则需指定参数 key, key 是一个函数对象,例如字符串构成的列表,我想按照字符串的长度来排序
chars = ['Andrew', 'This', 'a', 'from', 'is', 'string', 'test']
sorted(chars, key=len)
>>> ['a', 'is', 'from', 'test', 'This', 'Andrew', 'string']
len 是内建函数,sorted 函数在排序的时候会用len去获取每个字符串的长度来排序。 也可以使用匿名函数 key=lambda x: len(x) 。
4、如果是一个复合的列表结构,例如由元组构成的列表,要按照元组中的第二个元素排序,那么可以用 lambda 定义一个匿名函数
students = [('zhang', 'A'), ('li', 'D'), ('wang', 'C')]
sorted(students, key=lambda x: x[1])
>>> [('zhang', 'A'), ('wang', 'C'), ('li', 'D')]
这里将按照字母 A-C-D 的顺序排列。
————————————————
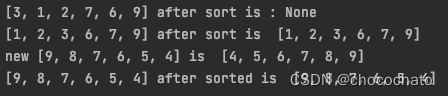
list1 = [3, 1, 2, 7, 6, 9]
list2 = [9, 8, 7, 6, 5, 4]
# sort()是在原列表上进行排序,不返回任何值,y = list.sort(),y为none。
print(f"{list1} after sort is :", list1.sort()) # 输出是none
list1.sort()
print(f"{list1} after sort is ", list1)
# 用sorted()时,不改变原list2,返回一个排好序的新list,y = list2.sorted(),输出为排好序的list2
print(f"new {list2} is ", sorted(list2))
print(f"{list2} after sorted is ", list2)
字典排序:
student = {'a': 20, 'c': 10, 'b': 5}
y = sorted(student.items(), key=lambda x: x[0]) # x.items() 返回键值对元组列表
z = sorted(student.items(), key=lambda x: x[1]) # key=...,以...为排序基准,这里用了匿名函数
print(f"after sorted by key, {student} become :", y)
print(f"after sorted by values, {student} become :", z)
x.items()方法以元组为内容返回列表,student.items() 返回为[(‘a’, 20), (‘c’, 10,), (‘b’, 5)]
这里的lambda匿名函数:lambda 参数 : 返回值表达式,上面的lambda x: x[1],以元组为参数,返回元组的第二个
key=lambda x: x[1], 即以元组第二个内容为排序基准

————————————————————————————
匿名函数lambda:
lambda函数特性:
1、匿名:匿名函数,就是没有名字的函数。lambda函数没有名字。
lambda函数有输入和输出:输入是传入到参数列表argument_list的值,输出是根据表达式expression计算得到的值。
lambda函数一般功能简单:lambda x: 表达式,表达式内容通常很简单
lambda函数示例:
lambda x, y: xy;函数输入是x和y,输出是xy
lambda:None;函数没有输入参数,输出是None
lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和
lambda **kwargs: 1;输入是任意键值对参数,输出是1
常见的lambda用法:
1、将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数。
add=lambda x, y: x+y,定义了加法函数lambda x, y: x+y,并将其赋值给变量add,这样变量add便成为具有加法功能的函数。例如,执行add(1,2),输出为3。
2、将lambda函数赋值给其他函数,将其他函数可以用该lambda函数替换。
3. 将lambda函数作为其他函数的返回值,返回给调用者。
函数的返回值也可以是函数。例如return lambda x, y: x+y返回一个加法函数。这时,lambda函数实际上是定义在某个函数内部的函数,称之为嵌套函数。
4. 将lambda函数作为参数传递给其他函数。
filter函数。此时lambda函数用于指定过滤列表元素的条件。
例如filter(lambda x: x % 3 == 0, [1, 2, 3])指定将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是[3]。
sorted函数。此时lambda函数用于指定对列表中所有元素进行排序的准则。例如sorted([1, 2, 3, 4, 5, 6, 7, 8, 9], key=lambda x: abs(5-x))将列表[1, 2, 3, 4, 5, 6, 7, 8, 9]按照元素与5距离从小到大进行排序,其结果是[5, 4, 6, 3, 7, 2, 8, 1, 9]。
map函数。此时lambda函数用于指定对列表中每一个元素的共同操作。例如map(lambda x: x+1, [1, 2,3])将列表[1, 2, 3]中的元素分别加1,其结果[2, 3, 4]。
reduce函数。此时lambda函数用于指定列表中两两相邻元素的结合条件。例如reduce(lambda a, b: ‘{}, {}’.format(a, b), [1, 2, 3, 4, 5, 6, 7, 8, 9])将列表 [1, 2, 3, 4, 5, 6, 7, 8, 9]中的元素从左往右两两以逗号分隔的字符的形式依次结合起来,其结果是’1, 2, 3, 4, 5, 6, 7, 8, 9’。
————————————————————————————
逐行读文件去除每行末端空白的几种方式:
def read_txt():
result = []
file_name = 'student_grade_input.txt'
with open(file_name) as obj_file:
for line in obj_file: # 逐行读取文件 for line in obj:
result.append(line) # 不经过处理时,文件的每行末端都自带一个换行符
return result
datas = read_txt() # 读取文件生成列表
print(datas)

for line in obj_file:
result.append(line(:-1)) # 或者result.append(line.rstrip())

strip()删两端空白、lstrip()删首位空白、rstrip()删末端空白并生成副本,如果没有用变量接住x.strip()或直接输出x.strip(),直接输出x结果仍然是没有删除空白的x
———————————————————————————
**对字符串进行拆解:**split()方法:对字符串进行切片,返回值为字符串切片后的列表。x.spilt(‘str’, num),str 为分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)。 num数字表示切片次数,num为空时,默认全切
def read_txt():
result = [] # 空列表,用来存放切片后的字符串列表
file_name = 'student_grade_input.txt'
with open(file_name) as obj_file:
for line in obj_file:
new_line = line.rstrip() # 由于文本每行末端有空白,需要删除
result.append(new_line.split(',')) # 将每行字符串以‘,’进行内容分割,返回为包含这些分割部分的列表
return result
datas = read_txt() # 读取文件生成列表
print(datas)

对字符串进行整合:‘str’.join(内容)函数:以str为分割符,将内容分隔开生成字符串。内容可以是元组、字符串、列表、字典
#对序列进行操作(分别使用' '与':'作为分隔符)
>>> seq1 = ['hello','good','boy','doiido']
>>> print ' '.join(seq1)
hello good boy doiido
>>> print ':'.join(seq1)
hello:good:boy:doiido
#对字符串进行操作
>>> seq2 = "hello good boy doiido"
>>> print ':'.join(seq2)
h:e:l:l:o: :g:o:o:d: :b:o:y: :d:o:i:i:d:o
#对元组进行操作
>>> seq3 = ('hello','good','boy','doiido')
>>> print ':'.join(seq3)
hello:good:boy:doiido
def read_txt():
result = []
file_name = 'student_grade_input.txt'
with open(file_name) as obj_file:
for line in obj_file:
new_line = line.rstrip()
result.append(new_line.split(','))
return result
def sort_grade(list1):
after_sorted = sorted(list1, key=lambda x: int(x[2])) # lambda x: x[2],第一个x取list1列表中的类型,这里x是列表类型
return after_sorted
def write_grade(list2):
with open('after_sorted_grade_output.txt','w') as obj:
for data in list2:
obj.write('-'.join(data)+"\n")
datas = read_txt() # 读取文件生成列表
datas = sort_grade(datas) # 对读取的文件内容进行排序
write_grade(datas) # 写入排好序的文件
with open('after_sorted_grade_output.txt') as obj_1:
for line in obj_1:
print(line)

常见报错
1. 继承错误
TypeError: module() takes at most 2 arguments (3 given) 子类要继承父类而两者不在同一个模块(文件)时,用import 声明不能只声明类名,应该是 from 模块名 import 父类名
来源:https://www.cnblogs.com/kevin-hou1991/p/14806598.html
模块中导入类的另外几种方式:from 模块名 import*、 导入整个模块再用module_name.class_name继承:my_car = car.Car(…,…)、
2.命名错误
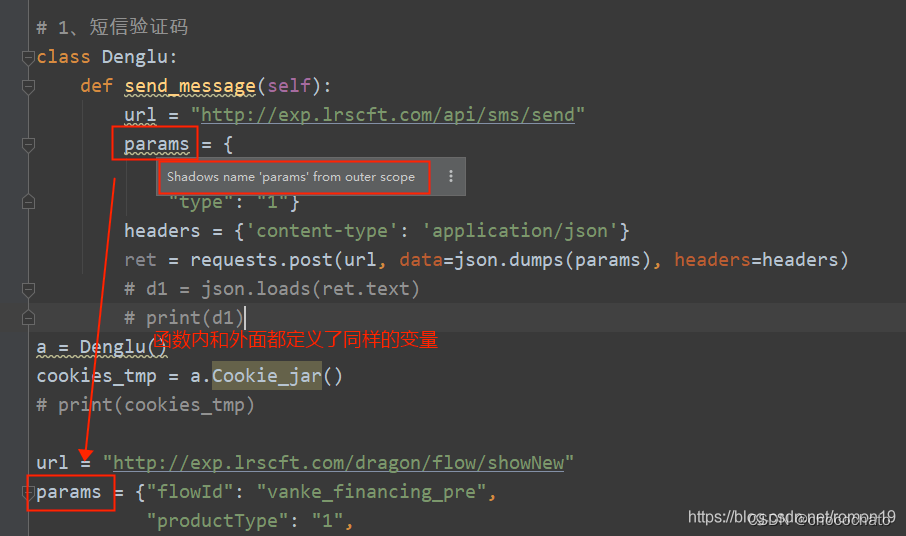
Shadows name ‘begin’ from outer scope :函数内部与外部定义了同样的变量
文件
路径
相对路径:来源:https://blog.csdn.net/weixin_38341556/article/details/107545835
写入字典内容到文件时遇到的语法问题----for key,values in zidian.items()
def Count_in():
prompt = "Count: "
prompt1 = "\n Password "
Count = input(prompt)
Password = input(prompt1)
User = {Count: Password}
return User
def File_in(User):
file_name = 'User_information.txt'
with open(file_name, 'a') as file_object:
for Count, Password in User.items():
file_object.write("Count : "+ Count
+"\n"
+"Password: "+ Password)
user_1 = Count_in() #要用一个变量接住函数的返回值
File_in(user_1)
总结:本周学完了python,目前遇到的问题基本百度查资料都解决了。总结下来就是函数调用和方法使用不熟练,其他的细节还要刷题目才能发现问题,下周目标刷200道题目,并记录刷题过程遇到的问题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









