







1.列表
列表(list)是R语言的数据类型中最为复杂的一种。一般来说,列表就是一些对象的有序集合。列表允许整合若干对象到单个对象名下。例如,某个列表可能是若干向量、矩阵、数据框,甚至其他列表的组合。
1.1 创建列表
list函数用于创建列表,格式如下:
List(object1,object2,…)
其中的对象可以是目前为止介绍过的任何类型。创建列表时,列表中对象命名的格式如下:
List(name1=object1,name2=object2,…)
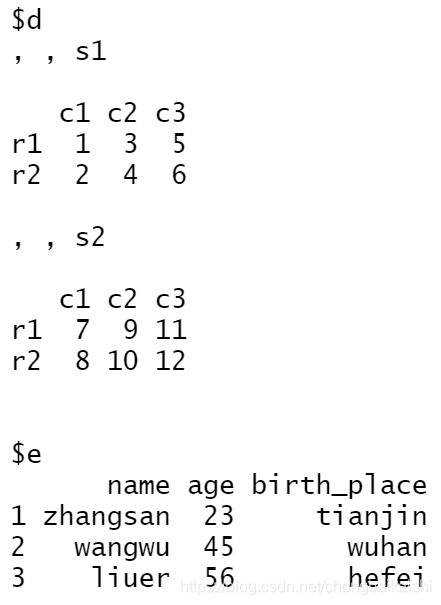
data <- list(a='python',
b=c(11,22,33,44),
c=matrix(seq(1,12),nrow=4,
dimnames=list(c('r1','r2','r3','r4'),c('c1','c2','c3'))),
d=array(seq(1,12),dim=c(2,3,2),
dimnames=list(c('r1','r2'),c('c1','c2','c3'),c('s1','s2'))),
e=data.frame(name = c('zhangsan','wangwu','liuer'),
age = c(23,45,56),
birth_place = c('tianjin','wuhan','hefei')))
data

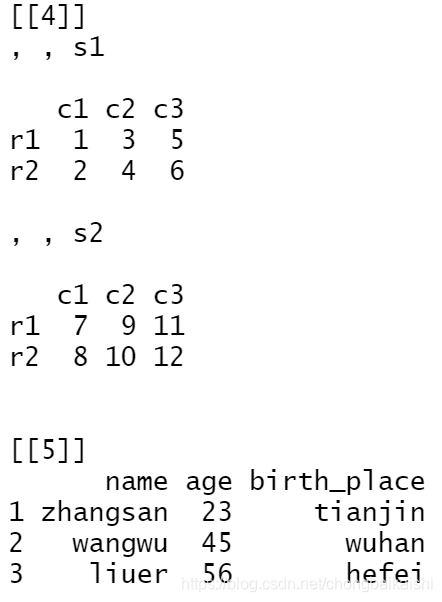
没有命名分量名称时
data2 <- list('python',
c(11,22,33,44),
matrix(seq(1,12),nrow=4,
dimnames=list(c('r1','r2','r3','r4'),c('c1','c2','c3'))),
array(seq(1,12),dim=c(2,3,2),
dimnames=list(c('r1','r2'),c('c1','c2','c3'),c('s1','s2'))),
data.frame(name = c('zhangsan','wangwu','liuer'),
age = c(23,45,56),
birth_place = c('tianjin','wuhan','hefei')))
data2

1.2 列表的索引
1.2.1 直接索引
单个分量的索引
一个中括号[]与两个中括号[[]]返回的数据类型不同,一个中括号[]返回的依然是列表,两个中括号[[]]返回的是向量。
> aa <- data[2]
> aa
$b
[1] 11 22 33 44
> class(aa)
[1] "list"
> bb <- data[[2]]
> bb
[1] 11 22 33 44
> class(bb)
[1] "numeric"
> is.vector(bb)
[1] TRUE
多个分量的索引
> dd <- data[c(1,3)]
> dd
$a
[1] "python"
$c
c1 c2 c3
r1 1 5 9
r2 2 6 10
r3 3 7 11
r4 4 8 12
1.2.2 名称索引
> # 方式一: <列表名>$<分量名称>
> ww <- data$d
> ww
, , s1
c1 c2 c3
r1 1 3 5
r2 2 4 6
, , s2
c1 c2 c3
r1 7 9 11
r2 8 10 12
> class(ww)
[1] "array"
>
> # 方式二:[]
> ss <- data['d']
> ss
$d
, , s1
c1 c2 c3
r1 1 3 5
r2 2 4 6
, , s2
c1 c2 c3
r1 7 9 11
r2 8 10 12
> class(ss)
[1] "list"
>
> #方式三: [[]]
> qq <- data[['d']]
> qq
, , s1
c1 c2 c3
r1 1 3 5
r2 2 4 6
, , s2
c1 c2 c3
r1 7 9 11
r2 8 10 12
> class(qq)
[1] "array"
1.2.3 二级索引
> # 情况1
> data[1][1] # 返回列表data[1]中的第一个列表
$a
[1] "python"
> data[1][2] # 会报错,因为返回列表中只有一个列表,没有下标2
$<NA>
NULL
>
> # 情况2
> data[[2]][2] #返回向量b中的第二个元素
[1] 22
> data$b[2]
[1] 22
> data[['b']][2]
[1] 22
1.3 列表编辑
1.3.1 单个元素修改
# <列表名>[[成分序号]]
# <列表名>[[成分名称]]
# <列表名>$成分名称
# 上述三种形式返回的均值组成列表的成分原本的数据结构
# 列表相应成分的修改在此基础上进行
# 列表data第一个成分:单个字符串修改
data[[1]] <- 'R语言'
data
# 列表data第二个成分:向量修改
data[['b']][3] <- 3333
data
# 列表data第三个成分:矩阵修改
data[[3]][2,2] <- 666
data
data[['c']][c(3,4),c(2,3)] <- c(77,88,111,1212)
data
# 列表data第四个成分:数据框修改
data$e[,2][3] <- 11
data
data$e$birth_place[2] <- 'hefei'
data

1.3.2 修改某一成分的所有值
> # 1.3.1 修改向量(三种方式)
> data[[2]] <- c(66,77)
> data[2]
$b
[1] 66 77
> data[['b']] <- c(77,88)
> data[2]
$b
[1] 77 88
> data$b <- c(88,99)
> data[2]
$b
[1] 88 99
> #1.3.2 修改矩阵
> data[[3]] <- matrix(seq(2,by=2,length.out=6),nrow=3)
> data[3]
$c
[,1] [,2]
[1,] 2 8
[2,] 4 10
[3,] 6 12
> # 既可以将整个成分修改为原来的数据结构,也可改变数据结构
> data[[3]] <- list('a','b','c') #改为列表
> data[3]
$c
$c[[1]]
[1] "a"
$c[[2]]
[1] "b"
$c[[3]]
[1] "c"
> data$c <- c('R','python') #改为向量
> data[3]
$c
[1] "R" "python"
# 修改多个成分
data[c(2,3)] <- list(rep(1,3),matrix(1:4,nrow=2))
data[c(2,3)]
1.3.3 列表成分的新增
方法一:
> data$f <- c('郑州','合肥','武汉')
> data[[7]] <- c(1,2,3)
> data[8] <- list(c('ss','ww'))
> data[c(6,7,8)]
$f
[1] "郑州" "合肥" "武汉"
[[2]]
[1] 1 2 3
[[3]]
[1] "ss" "ww"
方法二:
> data1 <- c(data,list(c('R','python'))) # 与一个包含一个成分的列表合并
> data1[c(5,6)]
$e
name age birth_place
1 zhangsan 23 tianjin
2 wangwu 45 wuhan
3 liuer 56 hefei
[[2]]
[1] "R" "python"
1.3.4 删除成分
> # 1.3.5 删除成分
> data[2] <- NULL
> data[[2]] <- NULL
> data['a'] <- NULL
> data[['d']] <- NULL
> data$e <- NULL
> data
named list()














 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









