







文章目录
SPDK简介
概念(什么是SPDK)
英特尔开发了SPDK(Storage Performance Development Kit),包含一套驱动程序,以及一整套端到端的存储参考架构。
首先要明确spdk是一个框架,而不是一个分布式系统,spdk的基石是
用户态(user space)、轮询(polled-mode)、异步(asynchronous)、无锁(lockless)。
SPDK基于Nvme驱动提供了零拷贝、高并发直接从用户态访问ssd的特性。
其最初的目的是为了优化块存储落盘。但随着spdk的持续演进,大家发现spdk可以优化存储软件栈的各个方面。很多分布式存储系统都在思考如何吸纳spdk框架,或是采用spdk代表的高性能存储技术,来优化整条IO链路。
使用SPDK原因
固态硬盘SSD正在迅速扩展它在数据中心中的份额,相较于传统存储介质,相较于传统机械硬盘性能耗电等优势明显。随着更新的闪存介质投入市场(如3D NAND),这些优势还在不断扩大。
这些新的设备目前大都基于NVMe:NVMe准确的说是目前最新的存储设备通信协议。现在一块基于NVMe的SSD硬盘的性能比一个企业级磁盘阵列还要好。
用户在集成新一代的NVMe设备,会碰到很大的挑战。因为NVMe硬盘的吞吐量和时延表现太好了就IOPS而言,比传统SAS或SATA温氏磁盘快上千倍,也比之前的SATA SSD快5~10倍。一般存储软件的表现,相对于NVMe来说,在整个IO事务中消耗的时间百分比就显得太多了。
nvme(硬件)已经快到一定程度了,尤其是软件已经赶不上他了,此时软件反而成为了系统IO的瓶颈。换句话说,存储软件栈的性能和效率在整个存储系统中越来越重要。
举个例子:我们从北京乘飞机到美国加州,按照当前的飞行速度(假设为机械硬盘),在天上需要13个小时。这种情况下,你安检的时间,过海关的时间,候机的时间,加起来3个小时,相对于总共的13+3=16个小时也不算长。设想现在飞机的飞行速度(硬件速度)提高了100倍(使用了NVME设备),不到10分钟的飞行时间,就可在加州落地,这时3个小时(软件速度)的地面手续就显得太长了。这时软件拖慢了整体时间,我们就需要提高安检,候机时间等,也就是提高软件效率。
SPDK就是做这件事的。
SPDK关键技术
相对于传统IO方式,SPDK运用了以下关键技术实现其高性能方案。
1.用户态(空间)
定义:什么是用户空间:Kernel space 是 Linux 内核的运行空间,User space 是用户程序的运行空间。为了安全系统稳定性,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
Kernel space 可以执行任意命令,调用系统的一切资源;User space 只能执行简单的运算,不能直接调用系统资源,必须通过系统接口(又称 system call),才能向内核发出指令也叫系统调用。
SPDK运行在用户态的实现
第一:驱动是一个直接连接并控制计算机硬件的软件。
第二:操作系统将根据权限级别将系统虚拟内存分为两类:用户空间和内核空间。
通常情况,驱动运行在内核空间,我们应用程序访问磁盘,读取网卡的数据,新建一个线程都需要通过系统调用接口,完成从用户态到内存态的切换。
但是SPDK包含的驱动运行在用户空间,但是这些驱动仍旧直接和硬件设备相连。也就是直接绕过内核空间。
SPDK为了控制硬件设备,他先指示操作系统放弃对该硬件的控制,这样就不会走内核空间了。比如在Linux上解除NvMe设备的绑定,则对应的/dev/nvme1就会消失。然后通过驱动直接控制硬件设备这样更快。
SPDK选择用户态的好处
传统IO是在用户态和内核态频繁切换,这会造成大量开销。而我们的设备驱动代码运行在用户态意味着,在定义上驱动代码不会运行在内核中。减少系统调用,避免内核上下文切换和中断的处理开销,从而节省了大量的CPU负担。允许更多的时间被用来做实际的数据存储。
2. 轮询模式
采用轮询模式改变了传统I/O的基本模型。
传统方式IO方式
一般来说读写数据的运作方式是这样的:
OS kernel请求一组数据,硬盘回应“嗯,没问题”,但是磁盘IO较慢,所以需要一点时间来准备数据,准备好了就会告诉OS kernel准备好了。假设现在已经准备好了,就会给CPU发送一个中断信号,通知OS说我的数据准备好了,可以来取数据了。这就是中断的方式。
有IO需要处理时就请求一个中断,CPU先去处理其他事务,等收到中断后才进行资源调度来处理IO。
但是注意中断是有开销的,需要切换资源。
轮询工作
当磁盘速度远慢于CPU时,CPU中断处理资源充沛,中断机制是能对这些IO任务应对自如的。
但是当硬盘设备速度很快,马上就可以把数据准备好,也就是磁盘IO几乎不需要等待了,再使用中断,本来硬盘IO数据立刻都准备好了,而CPU切换到其他地方执行去了,然后再中断回来取数据,这就会造成没必要的开销并且对性能造成影响。
在低速设备中,中断开销只占整个I/O时间的一个很小的百分比。然而,在固态设备的时代,持续引入更低延迟的持久化设备,中断开销成为了整个I/O时间中不能被忽视的部分。继续使用中断的方式会大大浪费硬盘性能。
所以解决方案:对于超高速设备(比如这里的nvme磁盘,基于RAM的缓存盘)以一种叫做“轮询”的模式运作。
所以我们采用轮询的工作方式:我们提交完io 请求之后,就一直通过轮询的方式来判断io 请求是否完成。SPDK架构中也是通过这样的方式,而不是依靠中断,在高速设备上用于取代中断的访问方式。这样会一直占用CPU,但是由于硬盘IO很快,这样带来的好处是降低总延迟和延迟抖动。通俗的来讲spdk运行时会占用满指定的CPU core,其本质就是一个大的while死循环,占满一个cpu core。去连续的跑用户指定的poller,轮询队列。
注意:是中断驱动处理还是轮询驱动处理,取决于系统硬件的搭配方式,不同的条件会匹配不同的优化策略。我们使用轮询是因为使用高速存储设备存储IO速度极快。
3. 线程无锁
spdk设计的主要目标之一就随着使用硬件(e.g. SSD,NIC,CPU)的增多而获得性能的线性提升,为了达到这目的,spdk的设计者就必须消除使用更多的系统资源带来的过载,如:更多的线程、进程间通信,访问更多的存储硬件、网卡带来的性能损耗。
spdk引入了无锁队列,使用lock-free编程,从而避免锁带来的性能损耗。
spdk的无锁队列主要依赖的dpdk的实现,其本质是使用CAS(compare and swap)实现了多生产者多消费者FIFO队列。
SPDK运行在用户空间:比如和应用绑定,因为线程是应用本身自己创建的这些线程,这样创建的线程就可以很方便被维护(比如数量)。SPDK驱动会将硬件队列直接暴露给应用(因为驱动在用户空间),应用被要求每次只能从一个线程访问一个硬件队列。这保证了:每个线程提交请求的时候不需要和其他线程协调(比如通过锁协调)因为每个线程控制一个硬件队列,这样避免了冲突。实现无锁。
4. 异步
SDPK提供的了大量的异步接口
spdk_bs_init(bs_dev, NULL, bs_init_complete, hello_context);
使用异步好处:是不会阻塞当前程序的执行,并且在操作完成之后调用回调函数。
通过轮询实现
SPDK架构介绍
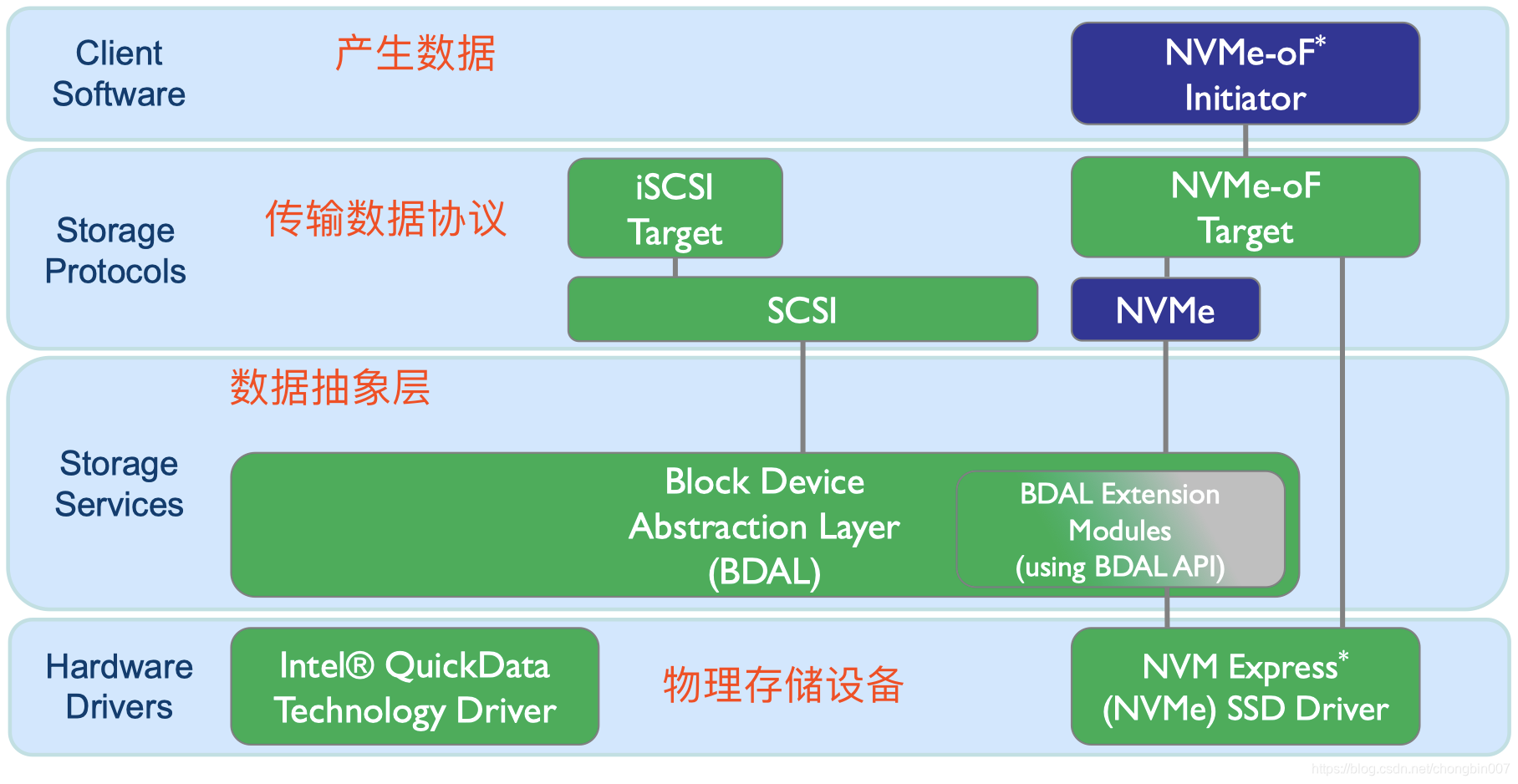
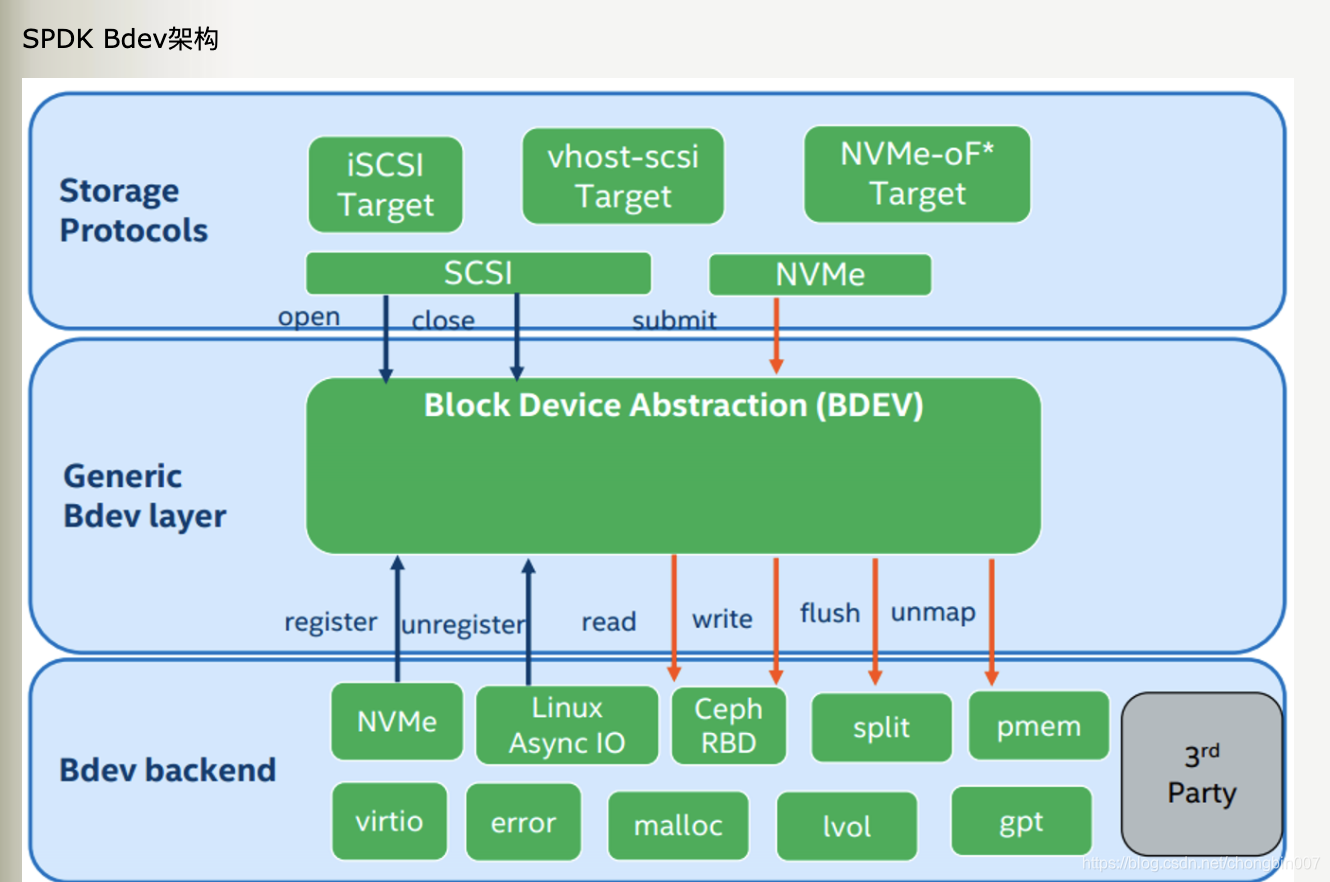
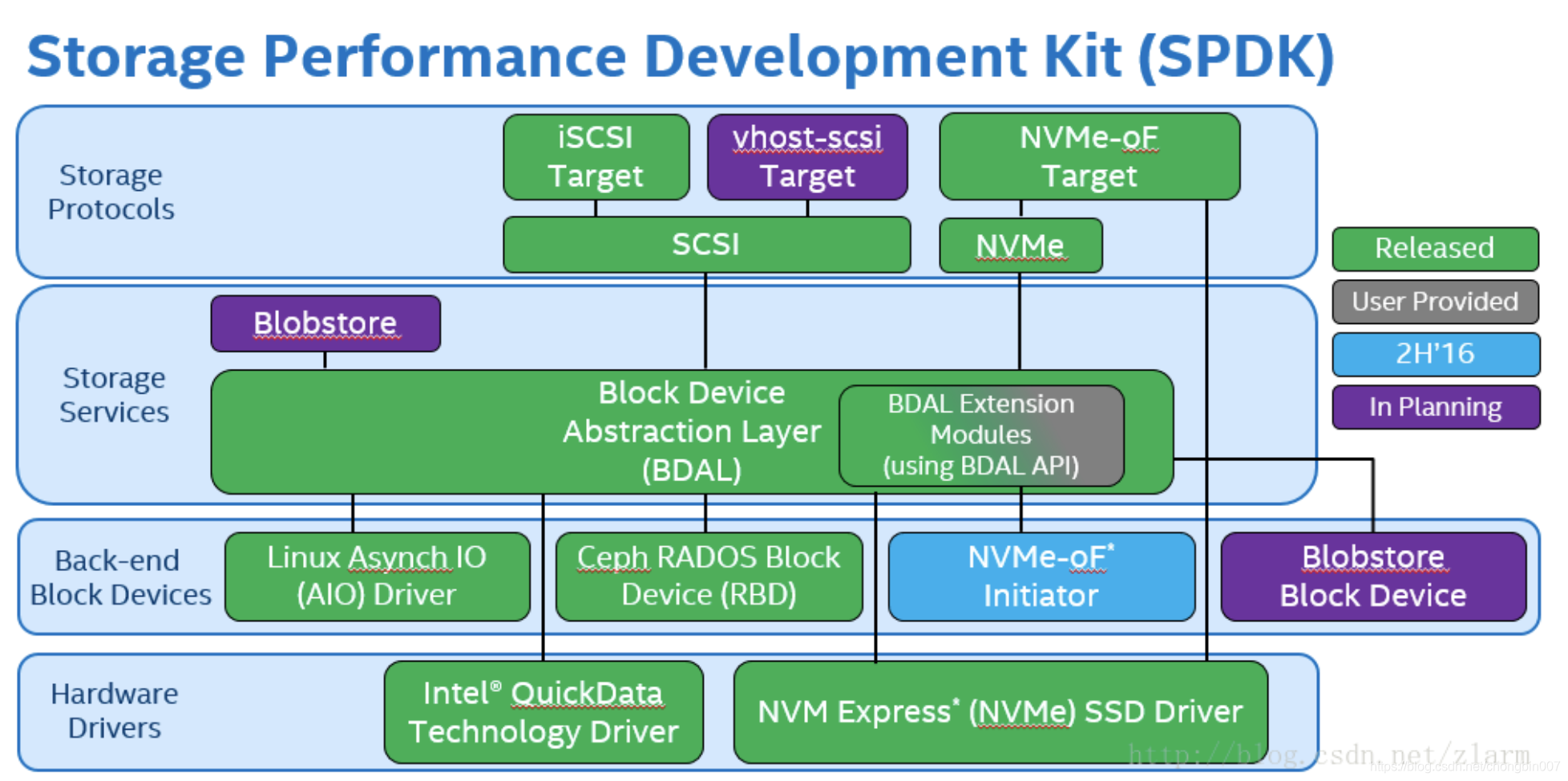
SPDK各层解析
1. client software就是
client software就是产生数据的部分,比如mysql数据库中的要存储到硬件设备上的数据。
2. 数据存储协议层
比如使用的是SCSI协议或者NVME协议,将上面的数据通过不同的传输通信协议发送给下层。
每个种类的接口可以使用不同的通信协议,不同通信协议是决定传输速度的关键因素。比如我们的网络层,同一个网络可以有不同的传输协议比如TCP或者UDP。
- NVME:一个通信协议,现在SSD大都使用的是NVME协议,可以极大提高传输速度。https://baijiahao.baidu.com/s?id=1637421199219751340&wfr=spider&for=pc
- SCSI也是一个传输协议,其中包括了很多协议。https://blog.csdn.net/weixin_43997530/article/details/108202722
3. 存储服务层 BDAL(BDEV)
数据块抽象层。
spdk提供了块设备(bdev)的软件栈,这个块设备并不是linux系统中的块设备,spdk中的块设备只是软件抽象出的接口层。
spdk已经提供了各种bdev,满足不同的后端存储方式、测试需求。如NVMe (NVMe bdev既有NVMe物理盘,也包括NVMeof)、内存(malloc bdev)、不落盘直接返回(null bdev)等等。用户也可以自定义自己的bdev,一个很常见的使用spdk的方式是,用户定义自己的bdev,用以访问自己的分布式存储集群。
blobstore层
块设备抽象,旨在等同于操作系统块存储层,该层通常位于传统内核存储堆栈中设备驱动程序的正上方。
blobstore是BDAL层的具体技术实现,使用blobstore技术,将后端存储层都抽象成一个存储块。提供给上层进行存储。上层将BDAL当成一个整体的存储介质就并提供存储接口给上层。
他可以将后端存储设备(如NVMe (NVMe bdev既有NVMe物理盘,也包括NVMeof)、内存(malloc bdev)分割成不同的存储单元blob,然后向blob中存储数据。
4. 后端块设备
通过BDAL,我们可以将数据存储到不同的地方比如AIO文件系统,再比如malloc内存,再比如NVME 协议。通过这些,就可以将数据落到物理存储介质。比如通过NVME直接将数据存放到NVME SSD固态硬盘。
总结
spdk目前的的应用场景主要是针对块存储,可以说块存储的整个存储的基石,再其之上我们又构建了各种文件存储、对象存储、表格存储、数据库等等。
参考资料
https://zhuanlan.zhihu.com/p/362978954
https://blog.csdn.net/weixin_40343504/article/details/88706733
https://www.optbbs.com/forum.php?mod=viewthread&tid=14642318
https://blog.csdn.net/zlarm/article/details/79140299



















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











