






1RabbitMq相关概念
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消 息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收 件人的手上, RabbitMQ 就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说, RabbitMQ 模型更像是一种交换机模型 。
1.1Producer: 生产者,就是投递消息的 一方。
生产者创建消息,然后发布到 RabbitMQ 中。消息一般可以包含 2 个部分:消息体和标签 (Label)。消息体也可以称之为 payload ,在实际应用中,消 息体 一般是一个带有业务逻辑结构 的数据,比如一个 JSON 字符串。当然可以进一步对这个消息体进行序列化操作。消息的标签 用来表述这条消息 , 比如 一个交换器的名称和 一个路由键 。 生产者把消息交由 RabbitMQ , RabbitMQ 之后会根据标签把消息发送给感兴趣 的消费者 (Consumer)
1.2Consumer: 消费者, 就是接收消息的 一方。
消费者连接到 RabbitMQ 服务器,并订阅到队列上。当消费者消费一条消息时,只是消费 消息的消息体 (playload)。在消息路由的过程中,消息的标签会丢弃,存入到队列中的消息只 有消息体,消费者也只会消费到消息体,也就不知道消息的生产者是谁,当然消费者也不需要 知道 。
1.3Broker: 消息中间件的服务节点 。
对于 RabbitMQ 来说,一个RabbitMQ Broker可以简单地看作一个RabbitMQ 服务节点, 或者RabbitMQ服务实例。大多数情况下也可以将一个RabbitMQ Broker看作一台RabbitMQ 服务器 。 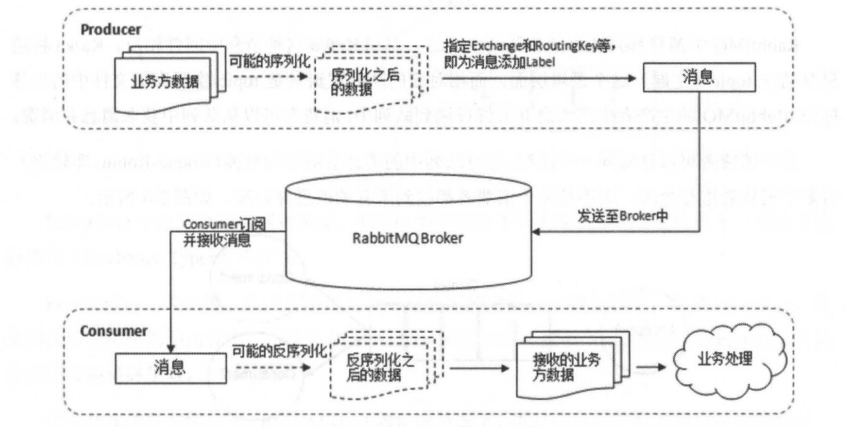
1.4Queue:队列
队列,是 RabbitMQ 的内部对象,用于存储消息。
1.5交换器,路由键,绑定
Exchange: 交换器。在图 2-4 中我们暂时可以理解成生产者将消息投递到队列中,实际上 这个在 RabbitMQ 中不会发生。真实情况是,生产者将消息发送到 Exchange (交换器,通常也 可以用大写的 "X" 来表示),由交换器将消息路由到一个或者多个队列中。如果路由不到,或 许会返回给生产者,或许直接丢弃。
RoutingKey: 路由键 。生产者将消息发给交换器 的时候, 一般会指定 一个 RoutingKey ,用 来指定这个消息的路由规则,而这个 RoutingKey 需要与交换器类型和绑定键 (BindingKey) 联 合使用才能最终生效。
Binding: 绑定。RabbitMQ中通过绑定将交换器与队列关联起来,在绑定的时候一般会指定一个绑定键 ( BindingKey ),这样RabbitMQ就知道如何正确地将消息路由到队列了。生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹 配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许 使用相同的 BindingKey 0 BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比 如 fanout 类型的交换器就会无视BindingKey,而是将消息路由到所有绑定到该交换器的队列中 。
1.6交换器类型
RabbitMQ 常用的交换器类型有 fanout 、 direct 、 topic 、 headers 这四种 。
fanout:它会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中。
direct:类型的交换器路由规则也很简单,它会把消息路由到那些 BindingKey 和 RoutingKey 完全匹配的队列中。
topic:direct 类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey,但是这种严 格的匹配方式在很多情况下不能满足实际业务的需求。topic 类型的交换器在匹配规则上进行了 扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队 列中。
headers:类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中 的 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对,当发送消息到交换器时, RabbitMQ 会获取到该消息的 headers (也是一个键值对的形式),对比其中的键值对是否完全 匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由 到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
1.7RabbitMq运转流程
(1)生产者连接到RabbitMQ Broker,建立一个连接(Connection),开启 一个信道 (Channel)。
(2) 生产者声明一个交换器,并设置相关属性,比如 交换机类型、是否持久化等。
(3) 生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等。
(4) 生产者通过路由键将交换器和队列绑定起来。
(5) 生产者发送消息至 RabbitMQ Broker,其中包含路由键、交换器等信息。
(6) 相应的交换器根据接收到的路由键查找相匹配的队列 。
(7) 如果找到,则将从生产者发送过来的消息存入相应的队列中。
(8) 如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
(9) 关闭信道。
(10) 关闭连接。
消费者接收消息的过程: (1)消费者连接到RabbitMQ Broker,建立一个连接(Connection),开启一个信道(Channel) 。
(2) 消费者向 RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数,以及做一些准备工作。
(3)等待 RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息。
(4) 消费者确认 (ack) 接收到的消息 。
(5) RabbitMQ 从队列中删除相应己经被确认的消息 。
(6) 关闭信道。
(7) 关闭连接。
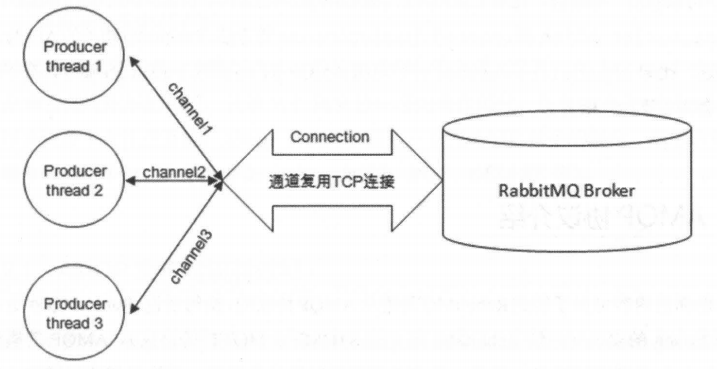
我们又引入了两个新的概念: Connection 和 Channel。我们知道无论是生产者还是消费者,都需要和 RabbitMQ Broker 建立连接,这个连接就是一条 TCP 连接,也就是Connection 。一旦 TCP 连接建立起来,客户端紧接着可以创建一个 AMQP 信道 (Channel) ,每个信道都会被指派一个唯一的id。信道是建立在 Connection 之上的虚拟连接, RabbitMQ 处理的每条 AMQP 指令都是通过信道完成的。我们完全可以直接使用 Connection 就能完成信道的工作,为什么还要引入信道呢?试想这样一个场景,一个应用程序中有很多个线程需要从 RabbitMQ 中消费消息,或者生产消息,那么必然需要建立很多个 Connection,也就是许多个 TCP 连接。然而对于操作系统而言,建立和销毁 TCP 连接是非常昂贵的开销,如果遇到使用高峰,性能瓶颈也随之显现。RabbitMQ 采用类似 NIO (Non-blocking 1/0) 的做法,选择 TCP 连接复用,不仅可以减少性能开销,同时也便于管理 。
每个线程把持一个信道,所以信道复用了Connection 的TCP连接。同时RabbitMQ可以确保每个线程的私密性,就像拥有独立的连接一样。当每个信道的流量不是很大时,复用单一的Connection可以在产生性能瓶颈的情况下有效地节省TCP连接资源。但是当信道本身的流量很大时,这时候多个信道复用一个Connection就会产生性能瓶颈,进而使整体的流量被限制了。此时就需要开辟多个Connection,将这些信道均摊到这些Connection中,至于这些相关的调优策略需要根据业务自身的实际情况进行调节。信道在AMQP中是一个很重要的概念,大多数操作都是在信道这个层面展开的。















 304
304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









