Hive
 关注
关注
 分享
分享
文章平均质量分 66
以数据仓库,用户画像实战为线索,从概念入门讲解到Hive深入开发实战各个环节
不要迷恋发哥
永远不要“用战术上的勤奋,掩饰战略上的懒惰”~~~~~~一名爱好古筝的IT宅男
展开
-
Hive之企业级调优实战
1:Fetch抓取Fetch抓取是指,==Hive中对某些情况的查询可以不必使用MapReduce计算例如:select * from score;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。在hive-default.xml.template文件中 hive.fetch.task.conversion默认是more,老版本hive默认是minimal,该属性修改为more以后...原创 2021-08-04 15:05:40 · 169 阅读 · 0 评论 -
Hive之存储和压缩企业实战
ORC存储方式的压缩Key Default Notes orc.compress ZLIB high level compression (one of ==NONE, ZLIB, SNAPPY==) orc.compress.size 262,144 number of bytes in each compression chunk;256kB orc.stripe.size 67,108,864 number of bytes in eac原创 2021-08-04 14:11:46 · 93 阅读 · 0 评论 -
Hive之文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC(列式存储)、PARQUET(列式存储)1:列式存储和行式存储上图左边为逻辑表,右边第一个为行式存储,第二个为列式存储。TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的。ORC和PARQUET是基于列式存储的。1:行存储的特点查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的.原创 2021-08-04 13:58:47 · 248 阅读 · 0 评论 -
Hive之表的数据压缩
1:数据的压缩说明压缩模式评价 可使用以下三种标准对压缩方式进行评价 1、压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好 2、压缩时间:越快越好 3、已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化 常见压缩格式 压缩方式 压缩比 压缩速度 解压缩速度 是否可分割 gzip原创 2021-08-02 17:55:03 · 1280 阅读 · 0 评论 -
Hive之静态分区和动态分区
1:静态分区表的分区字段的值需要开发人员手动给定1:创建分区表use myhive;create table order_partition(order_number string,order_price double,order_time string)partitioned BY(month string)row format delimited fields terminated by '\t';2:准备数据cd /install/hivedatasvim o原创 2021-08-02 15:42:29 · 400 阅读 · 0 评论 -
Hive数据导出
1:insert 导出语法INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ...将查询的结果导出到本地insert overwrite local directory '/install/hived...原创 2021-08-02 15:12:51 · 256 阅读 · 0 评论 -
Hive数据导入
1:直接向表中插入数据强烈不推荐使用hive (myhive)> create table score3 like score;hive (myhive)> insert into table score3 partition(month ='201807') values ('001','002','100');2:通过load加载数据语法hive> load data [local] inpath 'dataPath' [overwrite] ...原创 2021-08-02 14:54:17 · 214 阅读 · 0 评论 -
Hive之分桶表与实战
1:分桶表结构2:分桶表原理①分桶是相对分区进行更细粒度的划分,Hive表或分区表可进一步的分桶。②分桶将整个数据内容按照某列取hash值,对桶的个数取模的方式决定该条记录存放在哪个桶当中;具有相同hash值的数据进入到同一个文件中。比如按照name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。取模结果为 0 的数据记录存放到一个文件取模结果为 1 的数据记录存放到一个文件取...原创 2021-08-02 14:28:17 · 1343 阅读 · 0 评论 -
Hive之分区表与实战
1:分区表的原因如果hive当中所有的数据都存入到一个文件夹下面,那么在使用MR计算程序的时候,读取一整个目录下面的所有文件来进行计算,就会变得特别慢,因为数据量太大了实际工作当中一般都是计算前一天的数据,所以我们只需要将前一天的数据挑出来放到一个文件夹下面即可,专门去计算前一天的数据。这样就可以使用hive当中的分区表,通过分文件夹的形式,将每一天的数据都分成为一个文件夹,然后我们计算数据的时候,通过指定前一天的文件夹即可只计算前一天的数据。...原创 2021-07-31 23:17:09 · 306 阅读 · 1 评论 -
Hive之DDL操作
1:数据库DDL操作1:创建数据库hive > create database db_hive;# 或者hive > create database if not exists db_hive;数据库在HDFS上的默认存储路径是 /user/hive/warehouse/数据库名.db2:显示所有数据库hive> show databases;3:查询数据库hive> show databases like 'db_hive*';4:查看数据原创 2021-07-31 19:00:20 · 729 阅读 · 0 评论 -
Hive之复合数据类型实战
1:参数说明创建表的时候可以指定每行数据的格式,如果使用的是复合数据类型,还需要指定复合数据类型中的元素分割符。ROW FORMAT DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]其中这里FIELDS TERMINATED B.原创 2021-07-31 17:47:07 · 918 阅读 · 0 评论 -
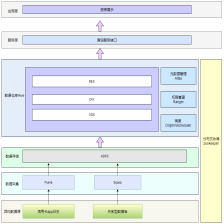
数据仓库分层架构
1:数据仓库的基本概念数据仓库的英文名称为Data Warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。它出于分析性报告和决策支持的目的而创建。数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。2:数据仓库的主要特征数据仓库是面向主题的(Subject-Oriented)、集成的(Integrat原创 2021-07-31 13:46:33 · 2514 阅读 · 0 评论 -
Hive架构原理
1:Hive的概念Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储支持。Hive可以理解为一个将SQL转换为MapReduce任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。2:Hive与数据库的区别Hive 具有 SQL 数据库的外表,但应用场景完全不同Hive 只适合用来做海量离线数据统计分析,.原创 2021-07-31 14:46:50 · 606 阅读 · 0 评论 -
Hive的交互方式
Hive的交互方式主要有三种使用Hive的前置准备:①先启动hadoop集群:因为hql语句会被编译成MR任务提交到集群运行;hive表数据一般存储在HDFS上。②mysql服务:因为对hive操作过程中,需要访问mysql中存储元数据的库及表。1:Hive交互shell在任意路径运行hive[hadoop@node03 ~]$ hive2:Hive JDBC服务启动hiveserver2服务,前台启动与后台启动方式二选一1:前台启动[hadoop@node03原创 2021-07-31 17:34:17 · 324 阅读 · 0 评论