






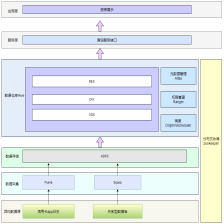
ORC存储方式的压缩
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of ==NONE, ZLIB, SNAPPY==) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk;256kB |
| orc.stripe.size | 67,108,864 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | "" | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
1:创建一个非压缩的的ORC存储方式
1:建表语句
create table log_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");2:插入数据
insert into table log_orc_none select * from log_text ;3:查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_none;
7.7 M /user/hive/warehouse/log_orc_none/123456_02:创建一个SNAPPY压缩的ORC存储方式
1:建表语句
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");2:插入数据
insert into table log_orc_snappy select * from log_text ;3:查看插入后数据
dfs -du -h /user/hive/warehouse/myhive.db/log_orc_snappy ;
3.8 M /user/hive/warehouse/log_orc_snappy/123456_04:上一节中默认创建的ORC存储方式,导入数据后的大小为
2.8 M /user/hive/warehouse/log_orc/123456_0比Snappy压缩的还小。原因是orc存储文件默认采用ZLIB压缩。比snappy压缩的小。
5:存储方式和压缩总结
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy。
3:企业实战
1:通过MultiDelimitSerDe 解决多字符分割场景
①创建表
官网建表语法参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-CreateTable
MultiDelimitSerDe参考:https://cwiki.apache.org/confluence/display/Hive/MultiDelimitSerDe
use myhive;
create table t1 (id String, name string)
row format serde 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES ("field.delim"="##");②准备数据 t1.txt
cd /install/hivedatas
vim t1.txt
1##xiaoming
2##xiaowang
3##xiaozhang③加载数据
load data local inpath '/install/hivedatas/t1.txt' into table t1;④查询数据
0: jdbc:hive2://node1:10000> select * from t1;
+--------+------------+--+
| t1.id | t1.name |
+--------+------------+--+
| 1 | xiaoming |
| 2 | xiaowang |
| 3 | xiaozhang |
+--------+------------+--+2:通过RegexSerDe 解决多字符分割场景
①创建表
官网手册参考:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
直接搜索RegexSerDe即可
create table t2(id int, name string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES ("input.regex" = "^(.*)\\#\\#(.*)$");②准备数据 t1.txt
1##xiaoming
2##xiaowang
3##xiaozhang③加载数据
load data local inpath '/install/hivedatas/t1.txt' into table t2;④查询数据
0: jdbc:hive2://node1:10000> select * from t2;
+--------+------------+--+
| t2.id | t2.name |
+--------+------------+--+
| 1 | xiaoming |
| 2 | xiaowang |
| 3 | xiaozhang |
+--------+------------+--+















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











