






Kafak版本:kafka_2.12-0.10.2.0
Zookeeper版本:zookeeper-3.4.9
spring-kafka版本:1.2.1.RELEASE
kafka是一个高并发的基于发布订阅模式的分布式消息队列系统。kafka具有更好的吞吐量、内置的分区、复制和容错能力,这使它成为大型消息处理应用程序的一个很好的解决方案。
介绍
topics是记录被发布的一个类别。它一般有多个消费者订阅它。每个topics 都会有一个以上的partition 。每个分区的记录都是有序的持久化到磁盘中,因此kafka长时间存储消息不是问题。kafka集群记录了发布的记录,包括消费的和未被消费的,它们都会有一个可配置的有效期。
消息存储在以主题命名的文件夹内(test-0 ,test-1,0和1是分区代表该主题有两个分区),且以.log命名的文件中。producer发送来的消息追加在log文件的尾部,consumer按照从头到尾的顺序依次读取log内的消息。
Distribution
在集群中,每个服务器都会有同一分区的拷贝,在这些服务器中,其中有一台服务器充当leader角色,其它都是followers角色。leader进行消息记录的读写操作,followers复制leader中的内容。如果leader宕机了,followers中的一个会自动变成leader。这就保证了负载均衡。所有的服务logs都包含相同的偏移量和消息。
Producers
生产者将数据发布到某一个topic上的某一个分区上。如果topic有多个分区,默认以循环的方式将消息发给这些分区。当然也可以自己指定分区。发送消息有三种模式。
- At most once—至多一次,消息可能会丢失,也不会重复提交.
- At least once—至少一次,消息不会丢失,也会重复提交
- Exactly once—恰好一次,这是人们所希望的,消息恰好提交一次,也没丢失。
Consumers
每一个消费者都有一个分组,消费者可以在不同的服务器上,也可以在同一台服务器上。对一同一组的消费者,他们以负载均衡的方式消费同一个主题下所有分区的消息。同一组消费者,只能消费同一主题下不同的消息,不同的组名下的消费者消费同一个主题,这两个组会同时消费相同的消息。一般consumer个数要小于等于partition个数。下图说明了这种消费关系(来自官网文档):
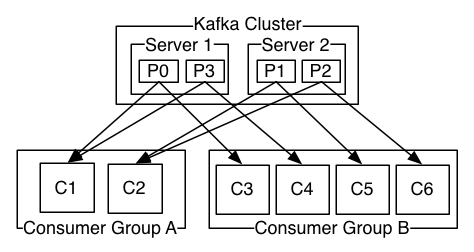
常见的mq系统,都会在broker上记录消息是否被消费,当消息传递给consumer时候,broker会记录当前情况或者等待消费者确认。这样有两种问题,一如果消费者处理消息,但在发送确认之前失败,那么消息将被消耗两次。第二个问题是关于性能的,broker必须在每个消息上保持多个状态(首先要锁定它,这样它就不会再被释放,然后将它标记为永久使用,这样就可以删除它)。棘手的问题必须处理,比如如何处理发送但从未被承认的信息。而kafka消息消费记录由消费者维护。
消费者跟踪它在每个分区中消耗的最大offset,并定期提交offset量矢量,以便在重新启动时能够恢复这些偏移量。kafak borker 有个offset manager,存储指定消费者组的偏移量,consumer会提交偏移量或者从其中获取偏移量。manager收到 consumer 的OffsetCommitRequest时,会把request添加到 __consumer_offsets,然后manager会给consumer一个offset 提交响应。当manger收到获取offset请求时,会返回最后提交的offset量,manager缓存了offset,以便能快速获取。
当group内新增消费者后,系统会重新平衡partition和consumer之间关系(rebalance),如果此时提交offest大余log最新offset,这个group将丢失这段内message。如果此时提交的offset小于log最新的offest,那么group将会消费两次这段内message。
自动提交:(设置auto.commit.offset = ture auto.commit.interval.ms=5000参数)是kafak默认配置,即消费者5秒钟提交一次offset。如果三秒钟中系统就已经完成了rebalance(增加分区,增加消费者,某一个消费者所在服务器宕机,集群中某个broker宕机),而之前消费者的offset还没提交。这短时间消息会被消息两次。自动提交很方便,但是开发者很难避免重复消息的问题。
commitSync同步提交,当消费者处理完消息,则提交offest,但是应用程序会一直阻塞,直到broker响应提交,这影响了系统的吞吐量。
Asynchronous Commit异步提交
kafka将消息缓存和存储在磁盘上的,大部分人认为磁盘的效率是比较慢的,实际上,它的速度快慢取决于如何设计和使用它。一方面,随机性的内存访问要比顺序的硬盘访问慢;另一方面,kafka是在linux上运行的,linux读取磁盘文件得cache机制,读写,最后,kafak运行在jvm上的,对象所占的内存开销非常高,通常比数据大一倍,而且随着堆内存的增加,垃圾回收会变得越来越繁琐和缓慢。
安装和配置
kafka依赖于zookeeper,首先要下载安装zookeeper。这个其它文章有介绍安装方法。
下载kafka_2.12-0.10.2.0.tar.gz 解压。修改config目录下 server.properties配置:
zookeeper.connect=localhost:2181 # zookeeper 注册中心
log.dirs=/opt/kafka/kafka-logs #log目录
num.partitions=2 #主题默认分区个数
listeners=PLAINTEXT://192.168.0.130:9092
broker.id=0 #id标识,在集群中,必须是唯一的整形数字
操作指令
启动:bin/kafka-server-start.sh config/server.properties 。如果集群的话,只需复制粘贴server.properties 重命名 server1.properties,修改broker.id和log.dirs。启动脚本替换使用该配置即可。
创建topic:bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test --partitions 2 --replication-factor 2
查看所有topic:bin/kafka-topics.sh --list --zookeeper localhost:2181
查看topic : bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
修改topic :bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --partitions 40
Kafak 监控启动命令:java -cp monitor.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --offsetStorage kafka --zk 192.168.0.130:2181 --port 81 --refresh 10.seconds --retain 2.days &
使用
springboot使用
springboot使用起来很简单,在springboot学习笔记一种已经将配置和依赖添加好了,这里在简单的把代码贴出来:
gradle或maven加入以下依赖(以gralde为例):
compile('org.springframework.kafka:spring-kafka')
application.yml加入以下配置:
spring:
kafka:
bootstrap-servers: 192.168.0.130:9092,192.168.0.130:9293
template.default-topic: bootkafka
listener:
concurrency: 10 #并发数
producer:
bootstrap-servers: 192.168.0.130:9092,192.168.0.130:9293 #中间件ip:port
#key指定key 和value序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#发送消息失败情况下,尝试放送消息的次数
retries: 3
batch-size: 16384
acks: 1
linger:
ms: 1
consumer:
bootstrap-servers: 192.168.0.130:9092,192.168.0.130:9293
key-serializer: org.apache.kafka.common.serialization.StringSerializer
#消费者组,默认
group-id: boot这样一个就配置好了,springboot配置比springmvc简单的多。
producer发布消息:
private @Autowired KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping(value = "/home", method = RequestMethod.GET)
public String home() {
try {
Map<String,Object> message=new HashMap<String,Object>();
message.put("description","kafka 消息测试");
message.put("topic","主题是 bootkafka");
message.put("timestamp",System.currentTimeMillis()/1000);
String stringValue = JSONObject.toJSONString(message);
kafkaTemplate.sendMessage("bootkafka",stringValue);//主题,消息
} catch (Exception e) {
e.printStackTrace();
}consumer消费消息,这里使用spring注解方式,比较简单:
@Component
public class KafkaConsumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = {"bootkafka" })
public void listen(String data) {
logger.info("收到kafka消息" + data);
}
springmvc使用
springmvc的配置就比较多一点,这也是springboot慢慢流行起来的原因。
gralde或maven加入以下依赖:
compile 'org.apache.kafka:kafka-clients:0.10.1.0'
compile 'org.springframework.kafka:spring-kafka:1.1.1.RELEASE'application.properties:
#bootstrap.servers=192.168.0.130:9092,192.168.0.130:9093,192.168.0.130:9091
kafka.bootstrap.servers=192.168.0.130:9092,192.168.0.130:9093
kafka.group.id=0
kafka.retries=1
kafka.batch.size=16384
kafka.linger.ms=1
kafka.buffer.memory=33554432
kafka.key.serializer=org.apache.kafka.common.serialization.StringSerializer
kafka.value.serializer=org.apache.kafka.common.serialization.StringSerializerspring-kafka.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:cache="http://www.springframework.org/schema/cache" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!-- 定义producer的参数 -->
<bean id="producerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<!--连接到kafka集群-->
<entry key="bootstrap.servers" value="${bootstrap.servers}" />
<entry key="group.id" value="0" />
<!--发送失败了,重新尝试次数-->
<entry key="retries" value="1" />
<!--批量记录的最大量-->
<entry key="batch.size" value="16384" />
<!--消息延迟发送到broker-->
<entry key="linger.ms" value="1" />
<entry key="buffer.memory" value="33554432" />
<!--序列化key实现的接口-->
<entry key="key.serializer"
value="org.apache.kafka.common.serialization.StringSerializer" />
<entry key="value.serializer"
value="org.apache.kafka.common.serialization.StringSerializer" />
</map>
</constructor-arg>
</bean>
<context:property-placeholder location="classpath*:config/config.properties"/>
<!-- 创建kafkatemplate需要使用的producerfactory bean -->
<bean id="producerFactory" class="org.springframework.kafka.core.DefaultKafkaProducerFactory">
<constructor-arg>
<ref bean="producerProperties"/>
</constructor-arg>
</bean>
<!-- 创建kafkatemplate bean,使用的时候,只需要注入这个bean,即可使用template的send消息方法 -->
<bean id="KafkaTemplate" class="org.springframework.kafka.core.KafkaTemplate">
<constructor-arg ref="producerFactory"/>
<constructor-arg name="autoFlush" value="true"/>
<property name="defaultTopic" value="mhb-test"/>
<property name="producerListener" ref="producerListener"/>
</bean>
<!-- 定义producer监听器,如果发送消息,会触发这个类 -->
<bean id="producerListener" class="com.test.myspring.kafka.kafkaProducerListener" />
< 定义消费者consumer的参数 -->
<bean id="consumerProperties" class="java.util.HashMap">
<constructor-arg>
<map>
<entry key="bootstrap.servers" value="${bootstrap.servers}"/>
<entry key="group.id" value="0"/>
<entry key="enable.auto.commit" value="false"/>
<entry key="auto.commit.interval.ms" value="1000"/>
<entry key="session.timeout.ms" value="15000"/>
<entry key="key.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/>
<entry key="value.deserializer" value="org.apache.kafka.common.serialization.StringDeserializer"/>
</map>
</constructor-arg>
</bean>
<!-- 创建消费者工厂consumerFactory bean -->;
<bean id="consumerFactory" class="org.springframework.kafka.core.DefaultKafkaConsumerFactory">
<constructor-arg>
<ref bean="consumerProperties"/>
</constructor-arg>
</bean>
<!-- 如果采用和上面所述注解的方式创建消费者bean,就不需要下面这些配置 -->
<bean id="messageListernerConsumerService" class="com.test.myspring.kafka.KafkaConsumerServer"/>
<!-- 消费者容器配置信息 -->
<bean id="containerProperties_trade" class="org.springframework.kafka.listener.config.ContainerProperties">
<constructor-arg value="mhb-test"/>
<property name="messageListener" ref="messageListernerConsumerService"/>
</bean>
<bean id="containerProperties_other" class="org.springframecck.kafka.listener.config.ContainerProperties">
<constructor-arg value="other_test_topic"/>
<property name="messageListener" ref="messageListernerConsumerService"/>
</bean>
</beans>web.xml 加上:
<param-value>classpath*:/config/spring-kafka.xml</param-value>如果不想创建spring-kafka.xml。我们可以自己创建KakfaFactory对象来初始化kafka:
package com.wtsd.myspring.kafka;
import org.apache.commons.lang3.StringUtils;
import org.apache.log4j.Logger;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
/**
* 生成kafka工厂类
*
* @author test
* @date 2017/4/4 11:27
* @Package com.myspring.kafka
* @Version v1.0
*/
public class KakfaFactory {
private static final Logger logger = Logger.getLogger(KakfaFactory.class);
public static DefaultKafkaProducerFactory<String, String> kafkaProducerFactory;
public static volatile KafkaTemplate<String, String> kafkaTemplate;
/**
* 创建factory
*
* @param []
* @return
* @throws
* @date 2017/4/4 19:04
*/
public static DefaultKafkaProducerFactory<String, String> getKafkaFactory() {
return new DefaultKafkaProducerFactory<String, String>(getConfigs());
}
/**
* 读取*.properties中文件
*
* @param []
* @return
* @throws
* @date 2017/4/4 19:04
*/
public static Map<String, Object> getConfigs() {
logger.info(">>>> 加载kafka配置参数 <<<<<");
Resource resource = new ClassPathResource("config/application.properties");
Map<String, Object> config = new HashMap<String, Object>();
try {
InputStream inputStream = resource.getInputStream();
Properties properties = new Properties();
properties.load(inputStream);
inputStream.close();
config = getKafakProperteis(properties);
} catch (IOException e) {
logger.error("加载kafka配置参数", e);
}
logger.info(">>>配置参数:" + config);
return config;
}
/**
* 获取kafka的配置参数
*
* @param [properties]
* @return
* @throws
* @date 2017/4/4 13:02
*/
public static Map<String, Object> getKafakProperteis(Properties properties) {
HashMap<String, Object> config;
Set<String> set = new HashSet<String>();
if (null != properties) {
config = new HashMap<String, Object>();
set = properties.stringPropertyNames();
for (String s : set) {
if (StringUtils.contains(s, "kafka") && StringUtils.isNotBlank(properties.getProperty(s))) {
config.put(s.replace("kafka.", ""), properties.getProperty(s));
}
}
return config;
}
return null;
}
public static KafkaTemplate<String, String> getKafkaTemplate() {
if (kafkaTemplate == null) {
logger.info("开始获取kafkaTemplae");
synchronized (kafkaTemplate ) {
if (kafkaTemplate == null) {
kafkaTemplate = new KafkaTemplate<String, String>(getKafkaFactory(), true);
}
}
return kafkaTemplate;
}
}
生产者发送消息和消费者消费消息和springboot使用方法一样,这里就不介绍了。















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









