







生产
基本流程是这样的:
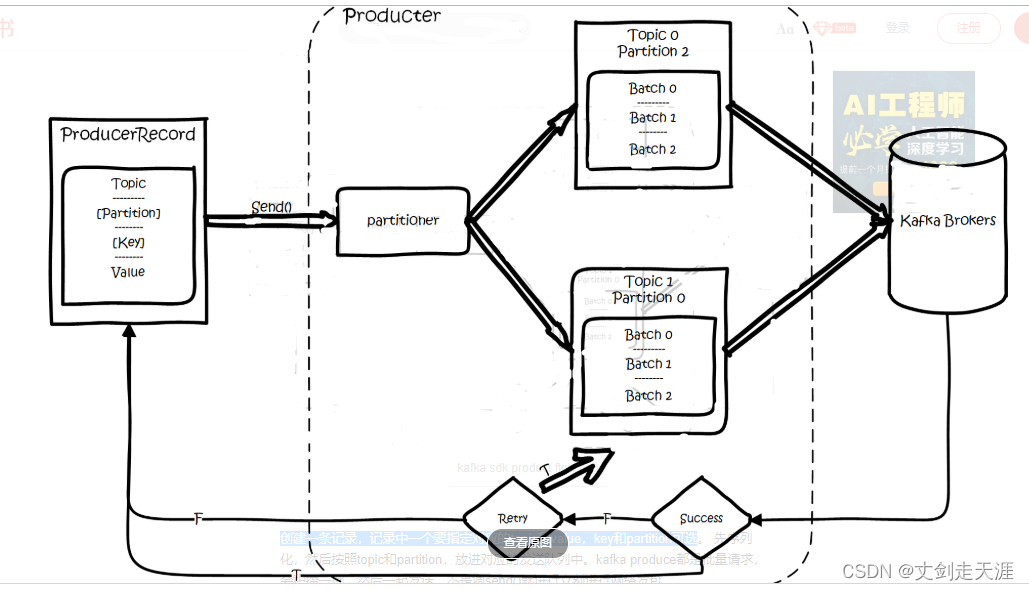
创建一条记录,记录中一个要指定对应的topic和value,key和partition可选。 先序列化,然后按照topic和partition,放进对应的发送队列中。kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。
如果partition没填,那么情况会是这样的:
- key有填
按照key进行哈希,相同key去一个partition。(如果扩展了partition的数量那么就不能保证了)
2. key没填
round-robin来选partition
这些要发往同一个partition的请求按照配置,攒一波,然后由一个单独的线程一次性发过去。
API
有high level api,替我们把很多事情都干了,offset,路由啥都替我们干了,用以来很简单。
还有simple api,offset啥的都是要我们自己记录。
partition
当存在多副本的情况下,会尽量把多个副本,分配到不同的broker上。kafka会为partition选出一个leader,之后所有该partition的请求,实际操作的都是leader,然后再同步到其他的follower。当一个broker歇菜后,所有leader在该broker上的partition都会重新选举,选出一个leader。(这里不像分布式文件存储系统那样会自动进行复制保持副本数)
然后这里就涉及两个细节:怎么分配partition,怎么选leader。
关于partition的分配,还有leader的选举,总得有个执行者。在kafka中,这个执行者就叫controller。kafka使用zk在broker中选出一个controller,用于partition分配和leader选举。
partition的分配
- 将所有Broker(假设共n个Broker)和待分配的Partition排序
- 将第i个Partition分配到第(i mod n)个Broker上 (这个就是leader)
- 将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
leader容灾
controller会在Zookeeper的/brokers/ids节点上注册Watch,一旦有broker宕机,它就能知道。当broker宕机后,controller就会给受到影响的partition选出新leader。controller从zk的/brokers/topics/[topic]/partitions/[partition]/state中,读取对应partition的ISR(in-sync replica已同步的副本)列表,选一个出来做leader。
选出leader后,更新zk,然后发送LeaderAndISRRequest给受影响的broker,让它们改变知道这事。为什么这里不是使用zk通知,而是直接给broker发送rpc请求,我的理解可能是这样做zk有性能问题吧。
如果ISR列表是空,那么会根据配置,随便选一个replica做leader,或者干脆这个partition就是歇菜。如果ISR列表的有机器,但是也歇菜了,那么还可以等ISR的机器活过来。
多副本同步
这里的策略,服务端这边的处理是follower从leader批量拉取数据来同步。但是具体的可靠性,是由生产者来决定的。
生产者生产消息的时候,通过request.required.acks参数来设置数据的可靠性
| acks | what happen |
| 0 | which means that the producer never waits for an acknowledgement from the broker.发过去就完事了,不关心broker是否处理成功,可能丢数据。 |
| 1 | which means that the producer gets an acknowledgement after the leader replica has received the data. 当写Leader成功后就返回,其他的replica都是通过fetcher去同步的,所以kafka是异步写,主备切换可能丢数据。 |
| -1 | which means that the producer gets an acknowledgement after all in-sync replicas have received the data. 要等到isr里所有机器同步成功,才能返回成功,延时取决于最慢的机器。强一致,不会丢数据。 |
在acks=-1的时候,如果ISR少于min.insync.replicas指定的数目,那么就会返回不可用。
这里ISR列表中的机器是会变化的,根据配置replica.lag.time.max.ms,多久没同步,就会从ISR列表中剔除。以前还有根据落后多少条消息就踢出ISR,在1.0版本后就去掉了,因为这个值很难取,在高峰的时候很容易出现节点不断的进出ISR列表。
从ISA中选出leader后,follower会从把自己日志中上一个高水位后面的记录去掉,然后去和leader拿新的数据。因为新的leader选出来后,follower上面的数据,可能比新leader多,所以要截取。这里高水位的意思,对于partition和leader,就是所有ISR中都有的最新一条记录。消费者最多只能读到高水位;
从leader的角度来说高水位的更新会延迟一轮,例如写入了一条新消息,ISR中的broker都fetch到了,但是ISR中的broker只有在下一轮的fetch中才能告诉leader。
也正是由于这个高水位延迟一轮,在一些情况下,kafka会出现丢数据和主备数据不一致的情况,0.11开始,使用leader epoch来代替高水位。















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









