






Redis Cluster是Redis的分布式解决方案,在3.0版本正式推出,有效地解决了Redis分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用Cluster架构方案到达负载均衡的目的。之前,Redis分布式方案一般有两种:
- 客户端分区方案,有点事分区逻辑可控,确定是需要自己处理数据路由、高可用、故障转移等问题
- 代理方案,有点事简化客户端分布式逻辑和升级维护便利,确定是家中架构部署复杂度和性能损耗
接下来我们介绍下Redis Cluster的数据分布。
- 数据分布
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
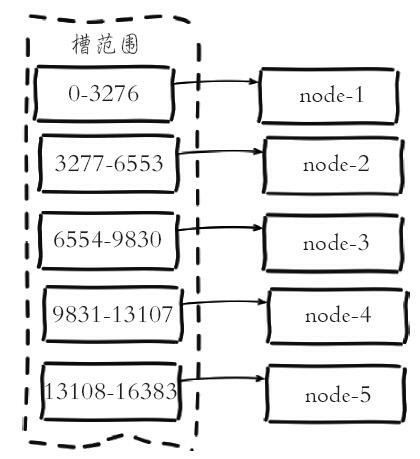
虚拟槽分区:巧妙的使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽。这个范围一般远远大于节点数,比如Redis Cluster槽范围是0~16363.槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽。如下图所示:
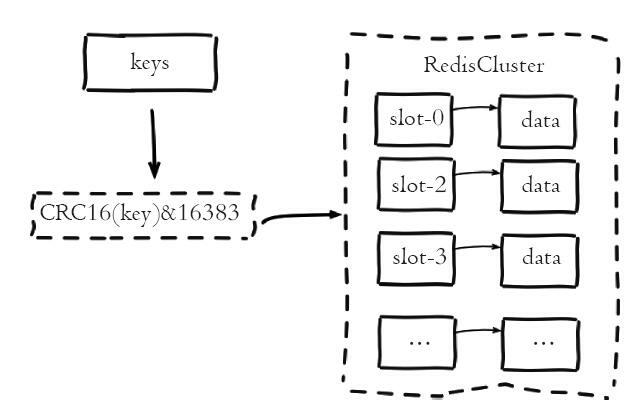
Redis Cluster采用虚拟槽分区:所有的键根据哈希函数映射到0~16383整数槽内,计算公式slot=CRC16 & 16383.每一个节点负责维护一部分槽以及槽所映射的键值数据,如下图:
Redis虚拟槽分区的特点:
- 解耦数据和节点之间的关系,简化了几点扩容和收缩的难度
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据。
- 支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景















 4670
4670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









