






生产环境Tomcat的优化
估计很多公司的生产环境都使用Tomcat使用为Web容器,估计也有很多同学已经对生产环境的Tomcat的进行各种各样优化,努力找出Tomcat的性能瓶颈,在生产环境提供一个稳定的、高效的Tomcat。让在我们在生产环境进行优化之前,先对Tomcat进行压力测试,找出Tomcat性能瓶颈,然后修改优化配置,再观察Tomcat是否满足我们的性能要求。
测试环境

测试系统图示:
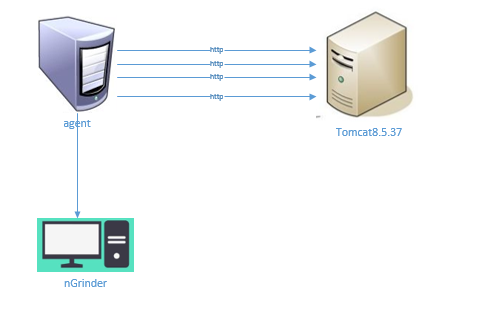
测试系统环境说明:
- 部署Tomcat的服务器程序是一个WAR包,WAR只有一个index.jsp页面,jsp页面的body只有一行” <p>hello world!</p>”,除此以外War中再没有任何额外的Jar类和Lib包。
- Agent客户端向服务器发送Http请求。
- Agent会把请求结果反馈至nGrinder管理机,包括TPS峰值、MTT、TPS图表等一系列数据。
- Tomcat服务器已接入Pinpoint,Pinpoint可以查询Tomcat服务器的heap、jvm cpu的使用情况。
- Tomcat的Webapps除测试包test.war外,还是host-manager、manager、ROOT均有Tomcat自带,方便偶尔观察Tomcat的线程池情况。
- Pinpoint、Tomcat监控严格意义来说会影响测试结果,但本次我们测试中忽略不计。
测试结果
heap.size=2G&G1
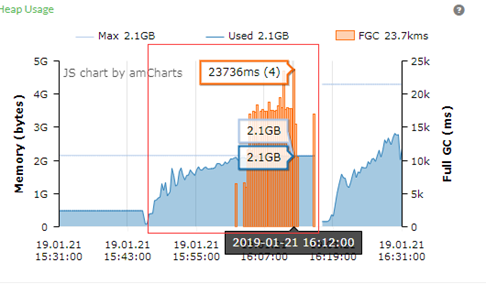
大约在Agent启动17分钟后,Tomcat的JVM开始出现Full GC(红色框是本次GC图),并且出现长时间STW事件。从第一个Full GC开始后,而且Full GC越来密集,大部分的停顿时间都在10000ms以上,对一个Web服务器来说停顿10秒钟是不可接受的。
从吞吐量的角度来看,系统启动17分钟以后吞吐量也下来了,导致Agent以出错的方式结束。
heap.size=4G&G1
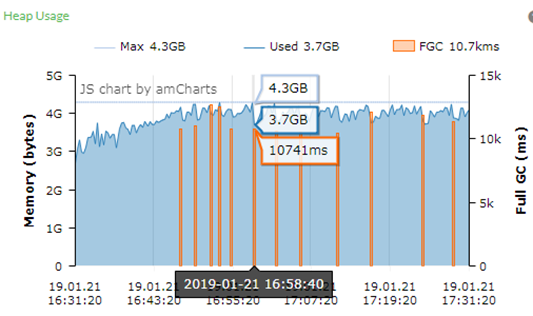
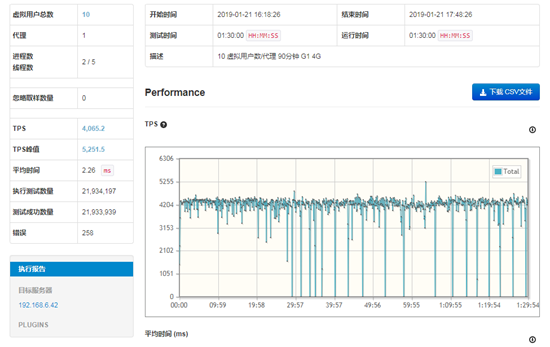
从GC图来看,可以看到存在比较频繁的Full GC,而且Full GC的持续时间较长为10741ms,即系统有10.7S停顿,系统的响应延迟现象是很明显的。
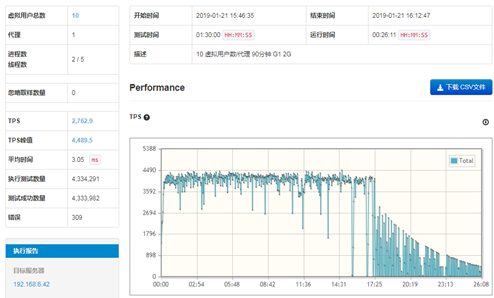
从测试结果来看,可以看到TPS的图在前面20多分钟属于相对稳定,但是之后就频繁出现为TPS为0或接近0的情况,结合上图可以知道此时系统正在进行Full GC。从整个测试结果的数值上看,TPS的平均值为4,065.2,TPS峰值为5,251.5,测试的后期TPS波动较大。
heap.size=4G&G1(6客户端)

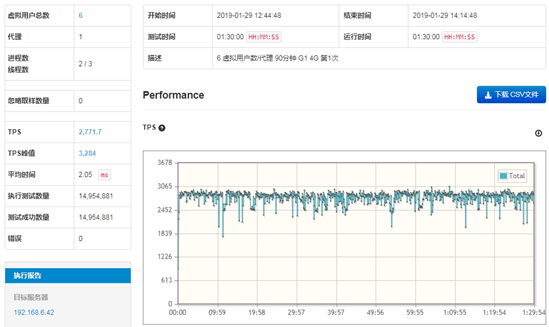
从GC图上看本次的测试没有发生Full GC事件,系统延迟也比较小,但是不能简单认为这次的测试的GC活动对系统没有影响。
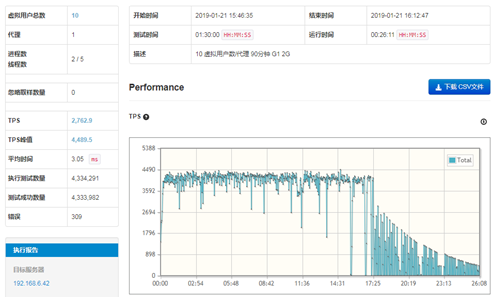
从测试结果图来看,TPS的趋势总体平衡,波动较小,没有出现特别低的点,总体属于优秀。其中,TPS的平均值为2,771.7,峰值为3,284,数据属于比较理想的情况。
heap.size=6G&G1
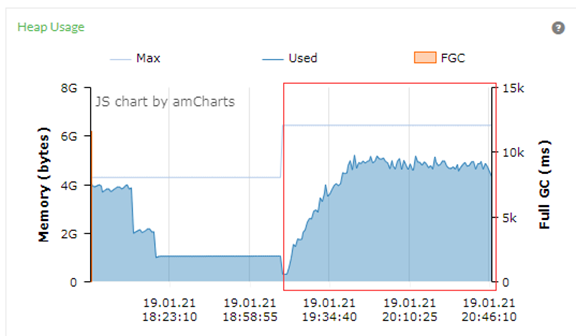
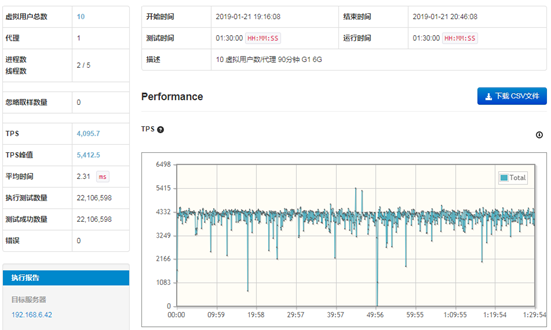
从GC图上看本次的测试没有发生Full GC事件,可以简单认为因为GC事件对系统延迟比较小,但是不能简单认为这次的测试的GC活动对系统没有影响。
从测试结果图来看,TPS的趋势总体平衡,但也存在波动的情况,特别是有二次比较低的点,分别是300TPS和700TPS,总体属于良好。其中,TPS的平均值为4,095.7,峰值为5,412.5,数据属于比较理想的情况。
heap.size=6G&ParallelOld
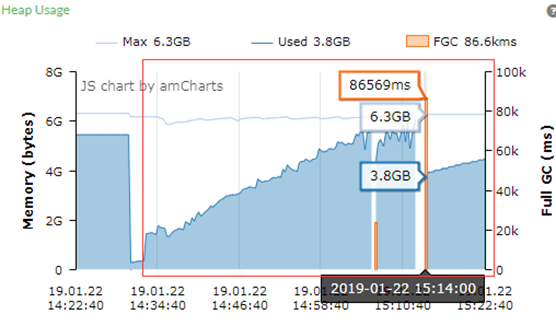
从GC图可以看到堆的大小几乎是沿着45度的角度增长,并且在系统测试的34分钟后,出现第一次Full GC,而且这次的Full GC是持续时间为86569ms,即86.6S。也即是因为Full GC,系统停止响应长达86.6S,直接导致Agent认为服务器没有响应从而停止发送请求,从而结束了测试。
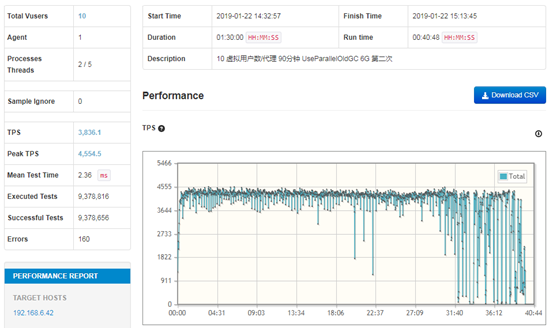
从Agent的统计图表来看,大约在开启压力测试22分钟后,TPS的波动非常大,TPS有时甚至为零。另外此处的TPS的平均值为3,836.1,TPS峰值为4,554.5,可以对比下” heap.size=6G&G1”的对应数值(TPS 4,095.7和TPS峰值为5,412.5)均有下降。可以看出来,ParallelOld算法在停顿方面的缺点还是很明显的,特别是大HeapSize的情况下。
heap.size=4G&ParallelOld(6客户端)
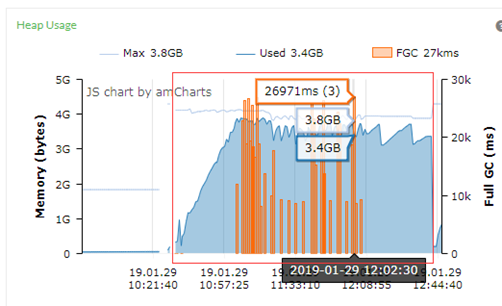
GC图上面来看,已经出现密集的Full GC,时间比较长的为26971ms,即27秒。
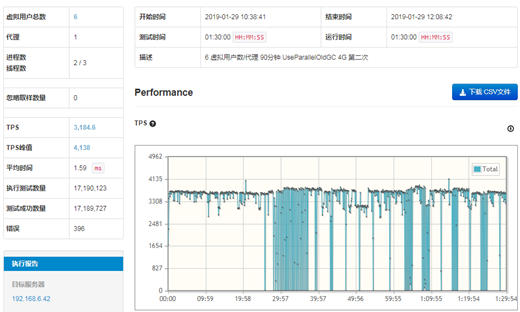
测试结果来看,29之后的TPS很不稳定,存在比较密集的触零点,属于比较差的测试结果。
heap.size=4G&CMS
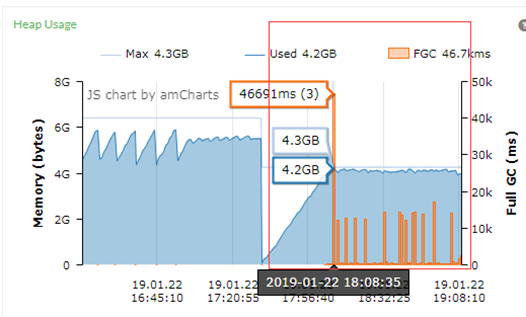
从上面的GC图可以看到Full GC的事件很频繁,其中有一个持续46651ms,而且底部的短时间Full GC很频繁,停顿时间较长。
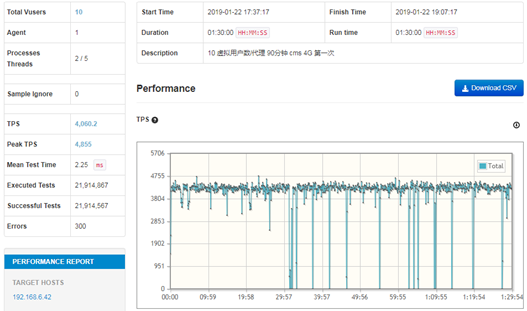
从测试结果来看,大概在开始测试的29分钟时后TPS波动很大,甚至有的接近底部。从TPS的走势图来看,表现为是不稳定。测试过程中平均TPS为4060.2,峰值为4855。
heap.size=4G&CMS(6客户端)

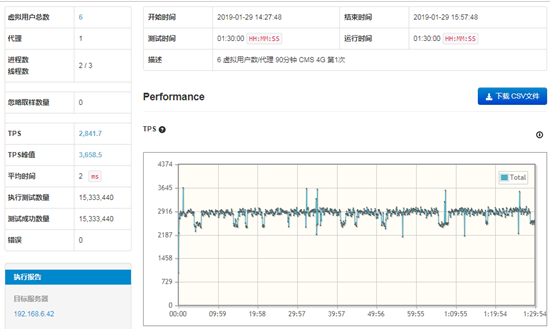
从GC图上看本次的测试发生6次Full GC事件,其中一次最长时间的一次Full GC事件为174ms,即0.1s,系统没有因为Full GC 而产生时间的停顿和延迟。
从测试结果图来看,TPS的趋势总体平衡,波动较小,没有出现特别低的点,总体属于优秀。其中,TPS的平均值为2,841.7,峰值为3,658.5,数据属于比较理想的情况。
heap.size=6G&CMS
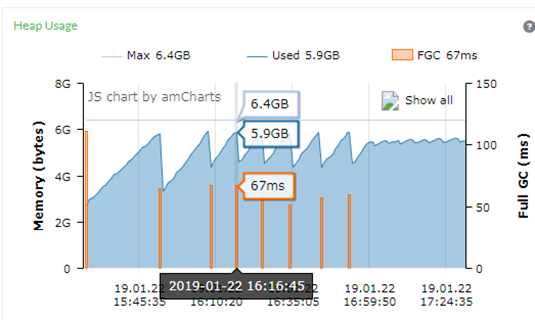

从上面的GC图可以看到发生好几次的Full GC事件,但每次的Full持续的时间不长,其中一次是67ms,这是我们可以接受的停顿时间,时间间隔比较是大概7分钟发生一次Full GC,但时间均小于100ms。
从上面的测试结果图表来看,TPS的量一直比较稳定,没有浮动很大的情况。TPS的平均值为4,238.8,峰值为5,346,其中峰值属于以上测试情况较好的,比” heap.size=6G&G1”的峰值5,412.5略小一点,但TPS” heap.size=6G&G1”的平均值4,095.7比更大。
测试结果分析与总结:
- Tomcat8默认使用NIO作为连接处理器,NIO相对的阻塞式BIO模式来说,NIO处理连接更高效、更节省线程,但NIO还不是Tomcat的连接器的最佳选择,APR才是。因为APR是从操作系统级别解决IO问题,Tomcat通过JNI的方式调用系统资源,提高服务器的并发处理性能,但是APR需要额外安装和配置。具体可以参考:https://tomcat.apache.org/tomcat-8.5-doc/apr.html
- 关闭Tomcat的” AccessLog”的输出(即注释:conf/server.xml的Valve className="org.apache.catalina.valves.AccessLogValve”节点),因为AccessLog平时使用不多,关闭后可以减少Tomcat的IO操作。这个操作需要自身业务系统的情况判断,确实不需要才关掉此日志输出。
- Tomcat sessionid生成器导致的延迟,这个问题不是每次测试都会出现,但是一旦出现会导致Tomcat出现类似假死的现象。具体表现为”org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [3,533] milliseconds”。可以参考:https://stackoverflow.com/questions/28201794/slow-startup-on-Tomcat-7-0-57-because-of-securerandom
- “too many open files”现象,当Tomcat并发的连接数太多时,即Tomcat进程的句柄数超出系统限制,就会出现” too many open files”,这个时候需要修改操作系统的默认参数。具体可以参考:https://stackoverflow.com/questions/36863451/apache-tomcat-exception-too-many-open-files?rq=1
- Tomcat 线程池配置,在conf/server.xml文件中,” Connector”配置节点可以修改Tomcat的线程池大小和连接等参数。
- 网上很多帖子说一个Tomcat进程最多只能配置1000线程,但是我在实际的测试过程配置了1005线程,并且通过Tomcat自带的监控观察到Tomcatpool大小为1005,系统可以正常运行,所以只能配置1000线程的说法是错误。
- 基于我的环境测试,Tomcat的thread pool的大小为300时属于比较合理。因为这个时候的MTT(系统平均响应时间)属于较小,并且TPS值较高并且持续较长时间运行,TPS平均值也没有出现较大波动。
- 基于我的环境测试,Tomcat的thread pool的大于400时,在测试的初期时,TPS的平均水平和峰值都可以获取比较高水平。但MTT时间增加了,即系统的响应时间增加了,thread pool并不是单纯的增大绝对数值就可以增加系统并发处理能力,并且在系统后期TPS回落较大,系统的可能出现假死、内存溢出等事件。所以Tomcat的线程池大小务必要根据硬件和内存等配置来设置。
- Tomcat的配置JVM。
- Heap大小及回收算法的优化配置,这个优化项是非常重要的。Tomcat8的JVM默认参数为:” CommandLine flags: -XX:InitialHeapSize=128950016 -XX:MaxHeapSize=2063200256 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC”。垃圾收集的算法为:ParallelGC,MaxHeapSize(堆的容量)约1.92G,可以看到JVM是很保守的参数启动的。这一点可以理解,因为JVM为了兼容绝大部分的硬件和环境而导致的,所以在硬件或要求高的情况下,优化是必须的。
- 因为操作系统有8G内存,除掉操作系统和一些必要的程序,Java进程可以使用的内存超过6G。为了提高Tomcat的吞吐量和减少延迟,在ParallelOld、CMS、G1三种算法选择一种。” Xms6144m Xmx6144m G1”组合经过8小时没有发生Full GC,而且在TPS线也很稳定,MTT也表现优秀。另外一个组合” Xms6144m Xmx6144m CMS”表现优秀,即CMS垃圾回收算法。自从有了G1,很多人都觉得只有G1都是才是最好的,其实,CMS也是一种优秀收集算法,特别是4G、6G级别的堆内存,差别其实不大,甚至在MTT方面表现更优秀。或者说有JDK1.8之前CMS更优秀,因为之前的G1并不是很成熟,即使是JDK1.8,G1在等预测模型方面有待改进。在测试过程中的同等条件下,CMS的TPS平均值、TPS峰值、MTT值均比G1的有更好的表现,所以说CMS表现非常优秀的。
- ParallelOld在堆较大时,缺点是很明显的,就是当年老代进行回收,停顿时间太长,因为ParallelOld进行一次年老代标记、清理时耗时太长了,会导致长时间STW事件,系统出现停顿、响应超时。
优化总结
Tomcat的最大并发数,这个估计是很想人知道数值。可以简单的认为,Tomcat在同一时刻能处理请求数(假设请求同时到达),那么Tomcat的并发数是Tomcat线程池的大小。个人认为:TPS的平均值、峰值对我们的生产环境更有意义,TPS峰值= ThreadPool/MTT。更重要的是,Tomcat很容易达到比较高的TPS峰值,但是要想在峰值保持长时间稳定运行是非常困难的,因为峰值TPS时,堆中分配内存的速度会远远大于堆内存回收的速度,系统运行一段时间后,系统就会出现Full GC,系统的Full GC就会越来越频繁,停顿时间会越来越时,MTT也会越来越长,请求可能出现超时、报错,从而TPS的出现直线下跌现象,如果请求的数仍然保持较高的数值,系统就会现出崩溃OutOfMemoryError现象,如下图。
所以短时间内Tomcat的TPS峰值是可以达到比较高数值,具体可以根据: ThreadPool /MTT计算,但需要长时间稳定运行,必须要考虑HeapSize、CPU处理能力、MTT、网络、IO等综合因素考虑,然后进行压力测试,找出性能的拐点。
虽然可以通过配置进行Tomcat优化后,相对原始的Tomcat优化后有着较高提升的空间,特别是HeapSize、GC收集算法、 ThreadPool的优化配置。但是我们系统的性能瓶颈往往不是由Tomcat导致,更多的是我们的系统在处理业务逻辑过程存在的问题导致的,如:频繁的数据库操作、不合理的使用索引、没有高命中率的缓存、过多的IO操作等操作,这些操作对系统的性能影响更大,优化后可以获得更大的更高性能提升。所以我们的优化顺序应该是:先优化业务逻辑实现,然后再考虑优化Tomcat,然后再优化业务逻辑实现。因为业务逻辑实现的优化空间更大,更值得我们花费时间优化。















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









