




 本文介绍AC算法原理及其实现,重点讲解基于双数组的Trie树优化方法,包括构建过程、状态转移函数、失败函数和输出函数的具体实现。
本文介绍AC算法原理及其实现,重点讲解基于双数组的Trie树优化方法,包括构建过程、状态转移函数、失败函数和输出函数的具体实现。
基于双数组的AC匹配算法学习
0. 前言
阅读本文之前,你需要了解KMP算法的原理以及AC自动机的相关概念。
1. AC算法
1.1. AC算法简述
AC算法基于有限状态自动机,在进行串匹配之前,先对模式串集合进行预处理,得到树形有限自动机,然后只需对文本进行一次扫描,便可以找到所有匹配成功的模式串。
例如以模式串集合P{she, he, her, him, hers, his}为例,构建树形状态转移自动机。
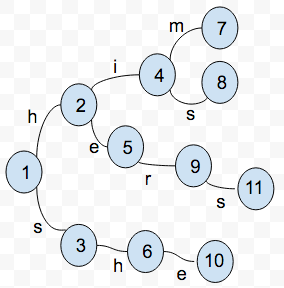
其中圆圈对应自动机的各个状态,边对应当前状态输入的字符。
1.2. AC与KMP的比较
AC多模式串匹配算法的思想与KMP算法有相通之处。AC算法从某种程度上可以说是KMP算法在多模式环境下的扩展。KMP算法比普通的字符比较方法的优点在于目标串不需要回溯,模式串回溯的距离尽可能小。从这句话可以看出,KMP算法需要解决模式串回溯的问题,也就说需要一个next数组来存储模式串中每个位置匹配失配之后,模式串当前的比较下标需要回溯的位置。AC算法也是这个思想,当比较到某个字符串的某个位置失配时,需要决定目标串的当前比较字符与模式串中的哪个字符串的哪个位置进行比较。因此,我们可以在这里引入一个状态转移矩阵,矩阵的行向量表示为若干个状态(具体有多少状态,取决于模式串的个数和各模式串的内部结构),矩阵的列向量表示为模式串中出现的所有字符,则具体某一个(i, j)元表示在状态为j的情况下,遇到一个字符i,所转移到的下一个状态的取值。
1.3. AC中的三个函数
AC算法的整个过程中需要实现三个函数:转移函数、输出函数、失败函数。
1.3.1. 转移函数
顾名思义,转移函数实现的就是状态转移。我们设转移函数为t=goto(s, c),表示当状态s遇到一个字符c后转移为状态t。若状态s不存在一条标记为c的有向边,则返回为-1,表示状态转移失败。
1.3.2. 输出函数
输出函数与每个状态对应,表示匹配到某个状态后,输出匹配成功的模式串。用output(s)表示,其中s为状态。output(s)在这里实现的相当于是状态和模式串之间的映射。因此,我们可以在匹配的过程中,对每个状态进行查询,看是否有匹配成功的模式串,若有,则输出。
1.3.3. 失败函数
失败函数也与每个状态对应,表示输入字符在当前状态匹配失败时所转移到的新的状态。用fail(s)表示,其中s为状态。
1.3.4. 典型的AC算法伪代码
s = INIT_STATE;
while (scanf(“%c”, &ch) != ch)
{
t = g(s, ch);
while (invalid(t))
{
s = fail(s);
t = g(s, ch);
}
output(t);
}
2. 基于双数组trie树的AC算法
2.1. 双数组trie树与AC算法的关系
从前面知道,AC算法需要三个函数来进行字符串匹配,而且这三个函数的求解都和一个确定的DFA(有限状态自动机)有关,那么我们必须得先求出这样一个DFA才行。DFA为一个树形结构,因此我们考虑用trie树来表示DFA,而且我们还得保证TRIE树检索速度的前提下,提高空间利用率,所以最终我们用基于双数组的trie树来存储DFA。
2.2. trie树
又称单词查找树,Trie树,是一种树形结构。所有含有公共前缀的字符串将挂在树中同一个结点下。实际上trie简明的存储了存在于串集合中的所有公共前缀。利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。字典树trie 搜索关键码的时间和关键码自身及其长度有关,最快是0(1),即在第一层即可判断是否搜索到,最坏的情况是0(n), n为Trie树的层数。由于很多时候Trie树的大多数结点分支很少,因此Trie树结构空间浪费比较多。Trie树是搜索树的一种,它在本质上是一个确定的有限状态自动机DFA,每个结点代表一个状态,根据输入变量的不同,进行状态转移。
通常,一个DFA是用一个transition table表示,它的行对应状态s,它的列对应转换标签s。每一个单元中的数据当输入与标记相同时,给定一个状态后要到达的状态。
这是一个的遍历高效方法,因为每次转换可以通过计算二维的数组索引得到。但是,从空间使用的角度看,这是相当浪费的,因为,在trie这种情况中,大多数结点只有少量的分枝,表中大多数单元是空白的。同时,一个更紧凑的方式是用链表保存每个状态的转移,但这种方式会比较慢,因为要进行线性搜索。
所以,建议使用可以快速访问的表压缩技术。
2.3. 基于双数组的trie树
双数组Trie(Double-Array Trie)是trie树的一个简单而有效的实现,由两个整数数组构成,一个是base[],另一个是check[]。base和check数组拥有一致的下标,(下标)即DFA中的每一个状态,也即TRIE树中所说的节点,base数组中的每个元素存储的是一个偏移量,用来计算下一个状态t,即t = base[s] + c,s为当前状态,base[s]为状态s的偏移量,c为输入字符,check数组用于检验转移的正确性。因此,从状态s输入c到状态t的一个转移必须满足如下条件:
若 base[s] + c == t,则check[t] == s。
由上述可知,构造基于双数组的trie树,关键在于求得每个状态的base[s]值。
2.4. 构建双数组trie树
假设模式串集合中所有字符对应的序列码为:
e=1, h=2, i=3, m=4, r=5, s=6
1).初始时base数组和check数组全为0,下标为0的状态不使用。下标为1的状态为初始状态。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| check | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2).引入函数q = x_check(char *str, int len)用来求出一个最小的正整数q满足对于字符串str中所有字符’c’有,CHECK[q+c] = 0,即寻找一个合适的偏移量,使得可以容纳所有可能出现的子节点。
3).插入可以分为3种情况:
case 1:当双数组trie为空时,插入模式串。
case 2:双数组trie不为空,插入时没有出现冲突。
case 3:双数组trie不为空,插入时出现冲突。
因此,在插入的过程中需要对这三种情况分别做处理。
4).插入过程的伪代码:
for str in p{str1, str2, …} //依次取出每一个模式串。
{
s = 1; //设s为初始状态
i = 0;
while (str[i])
{
if (base[s] == 0)
{
base[s] = x_check(str + i, 1);
}
t = base[s] + str[i];
if (check[t] == s)
{
; //字符str[i]为公共前缀,且已插入trie树中。
} else if (check[t] == 0)
{
check[t] = s; //没有出现冲突,直接插入
} else //插入时出现冲突
{
m = check[t];
//此时需要确定check[t]最终是由m占据,还是s占据?
//这取决于移动m和s各自的所有子节点所花费的工作量,取工作量较小者移动
//这里以移动m为例
if (child_count(m) < child_count(s) + 1)
//重新确定状态m的base[m],并移动m的所有子节点
{
old_base=base[m];
base[m] = x_check(child_str(m), child_count(m));
for i in child_str(m)
{
d=old_base + i;
base[base[m] + i] = base[d];
check[base[m] + i] = m;
for j in child_str(d)
{
check[base[d] + j] = base[m] + i;
}
base[d] = 0;
check[d] = 0;
}
} else //重新确定状态s的base[s],并移动s的所有子节点
{
//同移动m类似
}
check[t] = s;
}
s = t;
++i;
}
}
4).对于模式串中的第1个字符串”she”,设当前状态s为初始状态,即s=1。
首字符为’s’,计算base[s]=q=x_check(“s”, 1),得base[s]=1,由base[s]+ ’s’=t=7, check[7]=0,表示状态7可用,则check[7]=1,转移当前状态s=t;
第2个字符为’h’, 计算base[s]=q=x_check(“h”, 1),得base[s]=1,由base[s] + ‘h’=t=3, check[3]=0,表示状态3可用,则check[3]=7,转移当前状态s=t;
第3个字符为’e’,计算base[s]=q=x_check(“e”,1),得base[s]=1,由base[s] + ‘e’=t=2, check[t]=0,表示状态2可用,则check[2]=3;
插入字符串“she”后,双数组中的值为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| check | 0 | 3 | 7 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5).对于模式串中的第2个字符串”he”,设当前状态s为初始状态,即s=1。
首字符为’h’,由base[s] + ‘h’=t=3,check[3]=7≠1,表示遇到冲突,状态s=1有2个节点(’s’,’h’),状态check[t]=7有1个节点(‘h’),因此需要移动状态7的所有子节点,并转移当前状态s=t,移动后双数组中的值为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 1 | 0 | 0 | 1 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| check | 0 | 4 | 1 | 7 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
第2个字符为’e’,计算base[s]=q=x_check(“e”, 1),得base[s]=4,由base[s] + ‘e’=t=5,check[t]=0,表示状态5可用,则check[5]=3;
6).对于模式串中的第3个字符串“her”,设当前状态s为初始状态,即s=1。
对于前两个字符’h’、’e’,都不用插入;
对于第3个字符’r’,当前状态为s=5,计算base[s]=q=x_check(“r”, 1),得base[s]=1,由base[s]+’r’=t=6,check[6]=0,表示状态6可用,则check[6]=5;
插入字符串“her”后,双数组中的值为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base | 1 | 0 | 4 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| check | 0 | 4 | 1 | 7 | 3 | 5 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
7).按照4)中给出的算法依次插入剩下的所有字符串。
2.4. goto函数的实现
构建好了双数组,goto函数的实现就简单多了。
int goto_foo(int s, char c)
{
int t = base[s] + c;
if (check[t] == s)
{
return t;
}
return -1;
}
2.5. fail函数和output函数的实现
首先明确一点,构建双数组trie是为了快速、高效的实现状态转移函数t=goto(s,c)。但我们还得实现fail函数和output函数,实现的思想和KMP算法构造next的思想有异曲同工之妙。具体描述,可参考《再谈AC算法》。
回想在KMP中如何构造next数组?我们知道在KMP算法中,是通过回溯的方法来求next值的,也就是当前位置(对应一个字符)的next值是通过前一个位置的next值和当前字符这两个元素来决定,就是前一个位置的next值所对应的字符是否和当前字符相等,若相等则当前位置的next为前一个位置的next值加1,若不相等,则当前字符回溯比较前一个位置的next值所对应的位置的next值所对应的字符(有点绕),依次类推,直到比较到第1个位置。
同理,在trie树中求fail值,也需要通过回溯的方法来求。若要求当前状态的fail值,同样我们需要两个值,一个是前一个状态的fail值,另一个是前一个状态转移到当前状态的输入字符。当前状态失配后,我们需要得到前一个状态的fail值。(在树形结构中,前一个状态即为父节点所对应的状态。)然后我们查看输入字符在前一个状态的fail值所对应的状态下是否可以转移,若可以则返回转移后的结果,若不可以,则通过回溯的方法继续对更前一个状态进行查看,直到回溯到初始状态。
即若goto(m, c)=n, 则fail[n]的计算方法为:
int fail(int m, char c)
{
int p = fail[m];
while (p != 1 && goto_foo(p, c) == -1) //1为初始状态
{
p = fail[p];
}
if (goto_foo(p, c) == -1)
{
return 1;
}
return goto_foo(p, c);
}
若求得fail[n]的值不为1(初始状态),即fail[n]=g(p, c),则还须将output[p]中匹配的模式串,全部加入output[n]中。
从这里可看出来,在求当前状态的fail值时,它的前一个状态(父节点)的fail值必须先求出来,因此我们可以通过BFS的方法来实现。首先,令trie树中的第一层节点的fail值都为1,并依次入队列,这相当于初始化。然后,依次取出每一个节点m,计算m的所有子节点n的fail值,如果节点n还有子节点,则将节点n入队列,直到队列为空。
3.参考资料
- http://blog.csdn.net/nocml/article/details/6880154
- http://blog.sina.com.cn/s/blog_5cf4a61d0100yemd.html
- http://blog.csdn.net/zhoubl668/article/details/6957830
- http://my.oschina.net/amince/blog/222806?fromerr=5pVdTyDG
- http://ansjsun.iteye.com/blog/702255
- http://linux.thai.net/~thep/datrie/datrie.html
- http://blog.csdn.net/maotianwang/article/details/34559755
- http://blog.csdn.net/joylnwang/article/details/6793192
- http://blog.csdn.net/joylnwang/article/details/6884450
- http://www.hankcs.com/program/algorithm/aho-corasick-double-array-trie.html

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









