






作者: rockeet
发表日期: 2014年12月17日
原始链接: AC 自动机的实现
分类: 算法, 自动机
评论: 17 条
阅读次数: 13,373 次
关于 AC 自动机,有太多的文章在讲述它的原理,讲述者借此来展示自己的算法能力。但其实AC自动机的原理很简单,真正困难的地方在于一个高效的实现!对于任何一个基础算法,一个好的实现都要尽量满足:

不好的实现
可悲的是,大家能找到的那些实现,最多只满足速度快的需求,因为要速度快实在是太容易了,下面这个数据结构就能满足:
class AcTrie {
struct State {
int next[256];
int fail_link;
std::set<std::string> match_set;
bool is_final() const { return !match_set.empty(); }
// bool is_final; // not needed
};
std::vector<State> m_trie;
public:
// .....
};
在大家能找到的开源代码中,next 数组可能实现为 list<pair<char, int> >,或者 map<char, int>,或许这省了一点内存,但速度一般要下降一个数量级。也有一些更傻逼的实现不使用整数表示State,而是用指针,因为这样更加“面向对象”,例如:
State* next[256]; // 或者,因为叶节点没有孩子,可以更加“聪明”一点:
boost::shared_ptr<std::map<char, boost::shared_ptr<State> > next;
// 这种改动,fail_link 也得呼应一下
我们来看看美团的实现:http://tech.meituan.com/ac.html,这里只看它的接口(Java),不看实现:
public class Keyword implements Serializable {
private Integer id;
private Map<Integer, Integer> categoryTypeMap;
private String word;
private List<Integer> categories; //当前的关键词属于哪几个分类
}
static class Node {
int state; //自动机的状态,也就是节点数字
char character = 0; //指向当前节点的字符,也即条件
Node failureNode; //匹配失败时,下一个节点
List<Keyword> keywords; //匹配成功时,当前节点对应的关键词
List<Node> children; //当前节点的子节点
// ...
}
public static class Patterns {
protected final Node root = new Node();
protected List<Node> tree;
public Patterns(List<Keyword> keywords);
public void addKeyword(Keyword keyword);
public void setFailNode();
}
public static class UnknownClass {
public Set<Keyword> searchKeyword(String data, Integer category);
}
/*
其中最关键的方法有三个:
1. Patterns.addKeyWord : 动态创建 trie
2. Patterns.setFailNode : 创建 AC 自动机的 fail link
3. UnknownClass.searchKeyword : 这个不用说了吧
这个实现成功地把业务逻辑(Category相关的东西)绑到了算法中,非常有助于提高核心码农的不可替代性。
*/算法的接口
如果我们仔细思考一下:AC 自动机向应用程序提供的接口应该是什么?至少需要两点:
1.从 Pattern 集合创建 AC 自动机
2.用 AC 自动机在字符串上搜索 Pattern
创建 AC 是个离线 (Offline) 过程,可以做一些优化,但优化的空间和意义都不是很大。
关键是搜索到 Pattern 以后,我们应该怎样向用户返回搜索结果?传统的方式是返回一个字符串集合(例如 set<string>),这种方式往往导致上面那种不好的实现。
仔细思考一下,其实完全没有必要返回这个集合本身,我们只要返回一个可以“表达”这个集合的东西就可以了,至此,我们接触到了问题的本质,nark 自动机库中 AC 自动机的搜索接口是这样的:
template<class BaseTrie>
class Aho_Corasick : public BaseTrie, public AC_Scan_Interface {
public:
// OnHitWord(uint endpos, uint* beg, uint num)
template<class OnHitWord>
void ac_scan(fstring text, OnHitWord callback) const;
///...
};
ac_scan 从头至尾扫描 text,每当碰到一个包含匹配的状态时,调用应用程序提供的 OnHitWord 回调函数,该回调函数告诉用户当前匹配的结尾位置(endpos),和以数组形式表达的“字符串ID集合”(beg,num)。把字符串转化成ID,Pattern 集合用数组表达,这一点看上去毫无新意,却非常关键,因为:
- ID 就是一个整数,表达 Pattern 数组下标
- 用下标访问 Pattern 数组和用指针访问 Pattern 对象一样快
- 用下标还可以访问每个 Pattern 对应的具体业务数据
- 如果不需要,Pattern 的字符串字面值甚至可以不保存
这样创建出来的 AC 自动机找到的是每个匹配的 结尾位置(endpos),如果我们想要的是起始位置呢?也很简单,只需要在创建 AC 自动机时把每个模式串(Pattern)都先翻转一下,然后匹配时也反着匹配就 OK 了!
AC 自动机的数据结构/存储结构
AC 自动机本质上是一个 Trie + FailLink,我感觉很奇怪,有很多文章在讲双数组Trie,也有很多文章在讲AC自动机,但是把两者结合在一起的,却非常少,几乎没有,你可以尝试搜索双数组 AC自动机,或者 Double Array Trie Aho Corasick,或这些词的任意组合。
多的话我也不说了,我的 AC 自动机实现,就是在双数组 Trie 上加了 FailLink,然后 Pattern 集合用数组表示。除了这些,还有一点很关键:每个状态(Trie结点)对应的 MatchSet 怎么表示?其实也很简单:
Trie 结点是保存在数组中的,在 Trie 结点上,再加一个整数,表示 MatchSet 的起始偏移,最终的数据结构:
class AhoCorasic : ... {
struct State {
uint32_t base : 31;
uint32_t is_final : 1; // just for use AC Automata as a normal trie
uint32_t check : 31;
uint32_t is_free : 1;
uint32_t match_set; // start index to m_flat_match_set
uint32_t fail_link; // link to fail state
};
valvec<State> m_states;
valvec<uint32_t> m_flat_match_set;
//...
public:
size_t match_set_size(size_t state_id) const {
return m_states[state_id + 1].match_set - m_states[state_id].match_set;
}
};
可能有人还有疑问,match_set 是有了,尺寸在哪里呢?这个问题很简单:相邻求差,参考 match_set_size 函数。细心的人还会有疑问,id 最大的那个 State, state_id+1 作为数组下标越界了!这只要在 m_states 结尾多追加一个无用的 state,只用它的 match_set 成员。
进一步优化
很多时候,我们往往只需要最长的匹配,在这个实现中,只需要把每个 state 的 match_set 数组的第一个ID设为长度最长的那个就可以了:对于 {abcd, bcd, cd, d} ,abcd 将是第一个。而 OnHitWord 对每一个 MatchSet 非空的 State,只有一次调用,在这个调用中,应用程序只需要处理第一个ID,忽略其他ID就可以了。
优化无止境,终极优化
为了逻辑简洁,上面的示例代码使用了 Bit Field,但是,我们再仔细分析:一旦某个状态已被分配,它的 is_free 字段就是0,而所有从根(初始状态)可达的状态都是 非free 的,从而,当我们提取 check(或base) 字段时,就不需要多此一举做个 check & 0x7FFFFFFF,当然,使用 Bit Field 时,这个动作编译器帮我们做了。所以,最终的优化就是这样(两种写法皆可):
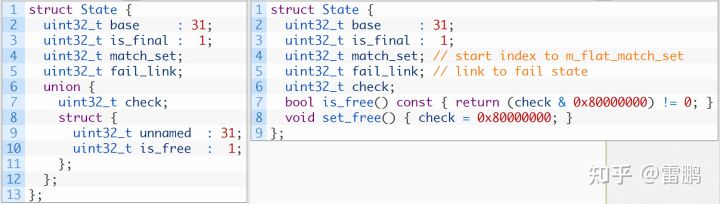
性能测试
机器: i7-4790, 内存 8G。数据集来自 Cygwin 下 find / 的输出,pattern集是 split 这个输出结果中所有的目录层次并去重(共205,754条),2000个pattern的集合是简单地取前2000条。
使用 Visual C++ 2013 ,分别编译成64位和32位,结果显示32位更快(大约快 20~30%):
| Pattern 个数 | Pattern 总字节数 | AC自动机 尺寸(字节数) | AC自动机 创建时间 | 扫描的数据大小 (字节数) | 所有 Pattern 命中总次数 | 吞吐量 (MB每秒) | 吞吐量 (最新优化) |
|---|---|---|---|---|---|---|---|
| 2,000 | 64,116 | 487,988 | 5 毫秒 | 292,230,711 | 2,306,570 | 524.3 MB/s | 721.8 MB/s |
| 205,754 | 8,971,910 | 105,772,516 | 2.78 秒 | 292,230,711 | 538,374,654 | 273.5 MB/s | 376.7 MB/s |
不过最终还是你们的实测结果最有说服力:下载软件,运行 ac_bench.exe 即可。
下载页面也有 Linux 版 (使用 gcc-4.8.2 编译) ,从实测结果看还是 Visual C++ 2013 要更快一点。
AC自动机创建工具
用 ac_build.exe 可以创建 AC 自动机,再使用 BaseDFA::load 加载,详情请看下载包中的 ac_scan.cpp ,ac_scan.cpp 中使用了 AC 自动机的抽象接口,这一方面为了保护我们的代码,另一方面也提高了代码的编译速度,并减小可执行文件的尺寸。















 4835
4835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









