






代码下载地址:https://github.com/tazhigang/big-data-github.git
一、概述
要在一个mapreduce程序中根据数据的不同输出两类结果到不同目录,这类灵活的输出需求可以通过自定义outputformat来实现。
- 自定义outputformat,
- 改写recordwriter,具体改写输出数据的方法write()
二、案例需求
- 需求:过滤输入的log日志中是否包含baidu
- (1)包含atguigu的网站输出到j:/url/baidu_url.txt
- (2)不包含atguigu的网站输出到j:/url/other_url.txt
- 输入数据
=================log.txt====================
https://www.baidu.com
http://news.baidu.com
https://map.baidu.com
http://www.google.com
http://cn.bing.com
http://www.sohu.com
http://www.sina.com
https://github.com
https://my.oschina.net
- 输出结果
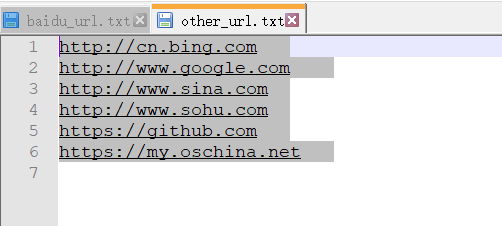
=================baidu_url.txt====================
http://news.baidu.com
https://map.baidu.com
https://www.baidu.com
=================other_url.txt====================
http://cn.bing.com
http://www.google.com
http://www.sina.com
http://www.sohu.com
https://github.com
https://my.oschina.net
三、创建maven项目
- 项目结构
- 代码实现
- HDFSUtil.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.junit.After; import org.junit.Before; import org.junit.Test; import java.io.IOException; import java.net.URI; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 22:54 */ public class HDFSUtil { Configuration configuration = new Configuration(); FileSystem fileSystem = null; /** * 每次执行添加有@Test注解的方法之前调用 */ @Before public void init(){ configuration.set("fs.defaultFs","hadoop-ip-101:9000"); try { fileSystem = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),configuration,"hadoop"); } catch (Exception e) { throw new RuntimeException("获取hdfs客户端连接异常"); } } /** * 每次执行添加有@Test注解的方法之后调用 */ @After public void closeRes(){ if(fileSystem!=null){ try { fileSystem.close(); } catch (IOException e) { throw new RuntimeException("关闭hdfs客户端连接异常"); } } } /** * 上传文件 */ @Test public void putFileToHDFS(){ try { fileSystem.copyFromLocalFile(new Path("F:\\big-data-github\\hadoop-parent\\hadoop-outputformat\\src\\main\\resources\\file\\log.txt"),new Path("/user/hadoop/outputformat/input/log.txt")); } catch (IOException e) { e.printStackTrace(); System.out.println(e.getMessage()); } } /** * 创建hdfs的目录 * 支持多级目录 */ @Test public void mkdirAtHDFS(){ try { boolean mkdirs = fileSystem.mkdirs(new Path("/user/hadoop/outputformat/input")); System.out.println(mkdirs); } catch (IOException e) { e.printStackTrace(); } } } - MyRecordWriter.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 22:57 */ public class MyRecordWriter extends RecordWriter<Text, NullWritable> { private FSDataOutputStream baiduOut = null; private FSDataOutputStream otherOut = null; public MyRecordWriter(TaskAttemptContext job) { Configuration configuration = job.getConfiguration(); try { FileSystem fileSystem = FileSystem.get(configuration); //创建两个输入流 Path baiduPath = new Path("j:/url/baidu_url.txt"); Path otherPath = new Path("j:/url/other_url.txt"); baiduOut = fileSystem.create(baiduPath); otherOut = fileSystem.create(otherPath); } catch (IOException e) { e.printStackTrace(); } } public void write(Text key, NullWritable value) throws IOException, InterruptedException { if(key.toString().contains("baidu")){ baiduOut.write(key.toString().getBytes()); }else{ otherOut.write(key.toString().getBytes()); } } public void close(TaskAttemptContext context) throws IOException, InterruptedException { if(baiduOut != null){ baiduOut.close(); } if(otherOut != null){ otherOut.close(); } } } - MyFileOutputFormat.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 22:55 */ public class MyFileOutputFormat extends FileOutputFormat<Text,NullWritable> { public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { return new MyRecordWriter(job); } } - MyFileOutputFormatDriver.java
package com.ittzg.hadoop.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import java.io.IOException; import java.net.URI; /** * @email: tazhigang095@163.com * @author: ittzg * @date: 2019/7/7 23:08 */ public class MyFileOutputFormatDriver { static class MyMapper extends Mapper<LongWritable,Text,Text,NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value,NullWritable.get()); } } static class MyReduce extends Reducer<Text,NullWritable,Text,NullWritable> { Text urlFormat = new Text(); @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { urlFormat.set(key.toString()+"\t\n"); context.write(urlFormat,NullWritable.get()); } } public static void main(String[] args) throws Exception { String input = "hdfs://hadoop-ip-101:9000/user/hadoop/outputformat/input"; String output = "hdfs://hadoop-ip-101:9000/user/hadoop/outputformat/output"; Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); job.setJarByClass(MyFileOutputFormatDriver.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop"); Path outPath = new Path(output); if(fs.exists(outPath)){ fs.delete(outPath,true); } // 将自定义的输出格式组件设置到job中 job.setOutputFormatClass(MyFileOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(input)); // 虽然我们自定义了outputformat,但是因为我们的outputformat继承自fileoutputformat // 而fileoutputformat要输出一个_SUCCESS文件,所以,在这还得指定一个输出目录 FileOutputFormat.setOutputPath(job, outPath); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
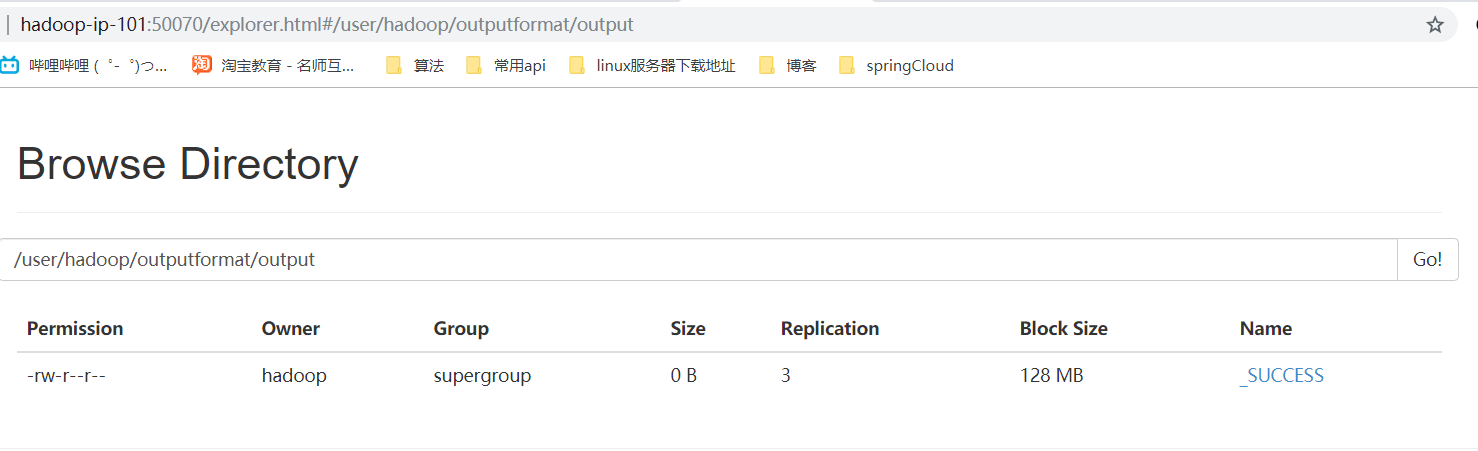
四、运行结果
- 网页浏览及本地文件浏览
- 文件内容下载浏览
















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









