






前言:
新人初次尝试,高手请忽略吧!
此文章禁止转载!
缩放网页可看清图片!
实验环境:win10 + python3.6 + pycharm
第三方库: beautifulsoup
爬虫开始:
第一步:确立目的
目的是爬取网站:http://www.mmjpg.com/ ,把网站上的妹子图片全部下载并保存在电脑硬盘上。
第二步:开始分析
用chrome浏览器打开 http://www.mmjpg.com/ 网站,按F12分析页面。不难发现网站每页都有3*5=15个美女套图网页,仔细发现每个美女套图网页url都是:http://www.mmjpg.com/mm/xxxx 。

去到网站最后一页验证:结果没错。而且发现 http://www.mmjpg.com/mm/xxxx 中的 xxxx 数字是从 1 开始递增。可见,目前目标网站的总套图网页有 1038 个。
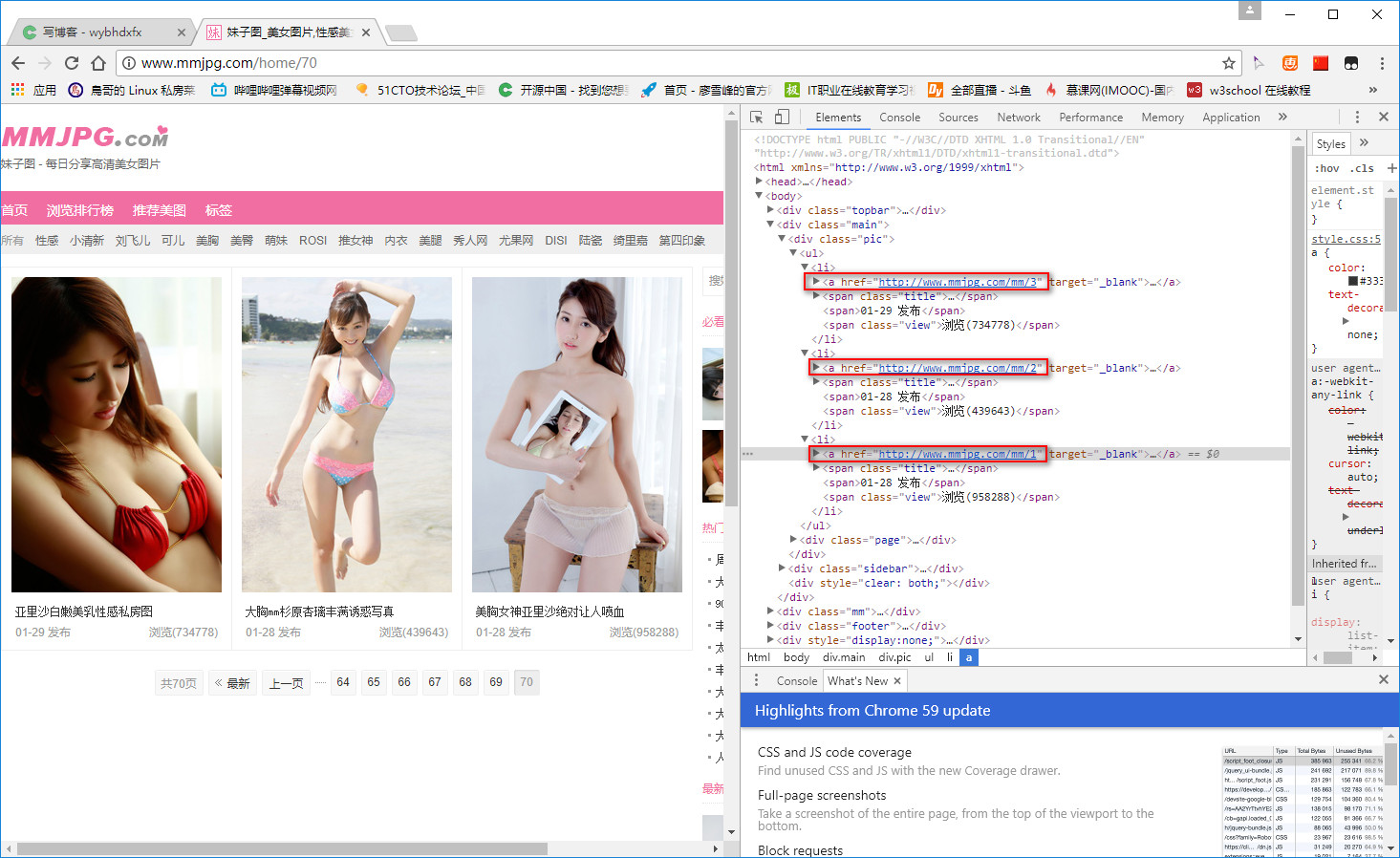
接下来,随便点击进一个套图网页,容易找到标题,第一张图片url和套图总页数(也就是总张数)所在的标签。同时,每张图片url都是:http://img.mmjpg.com/2017/1038/x.jpg,其中 x 代表第几张图片,数字 2017 估计和发布时年份有关,数字 1038 是指第几个套图。
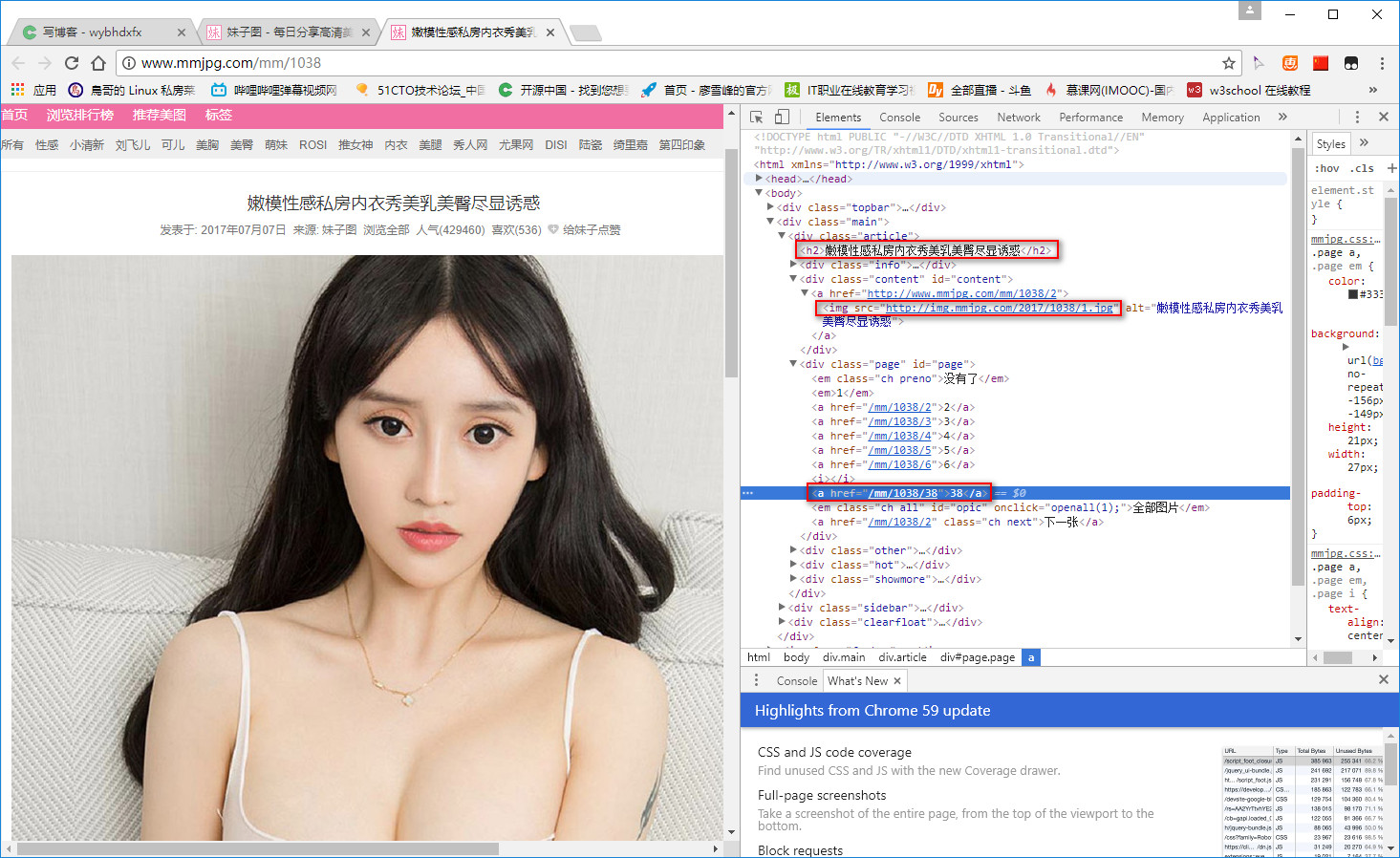
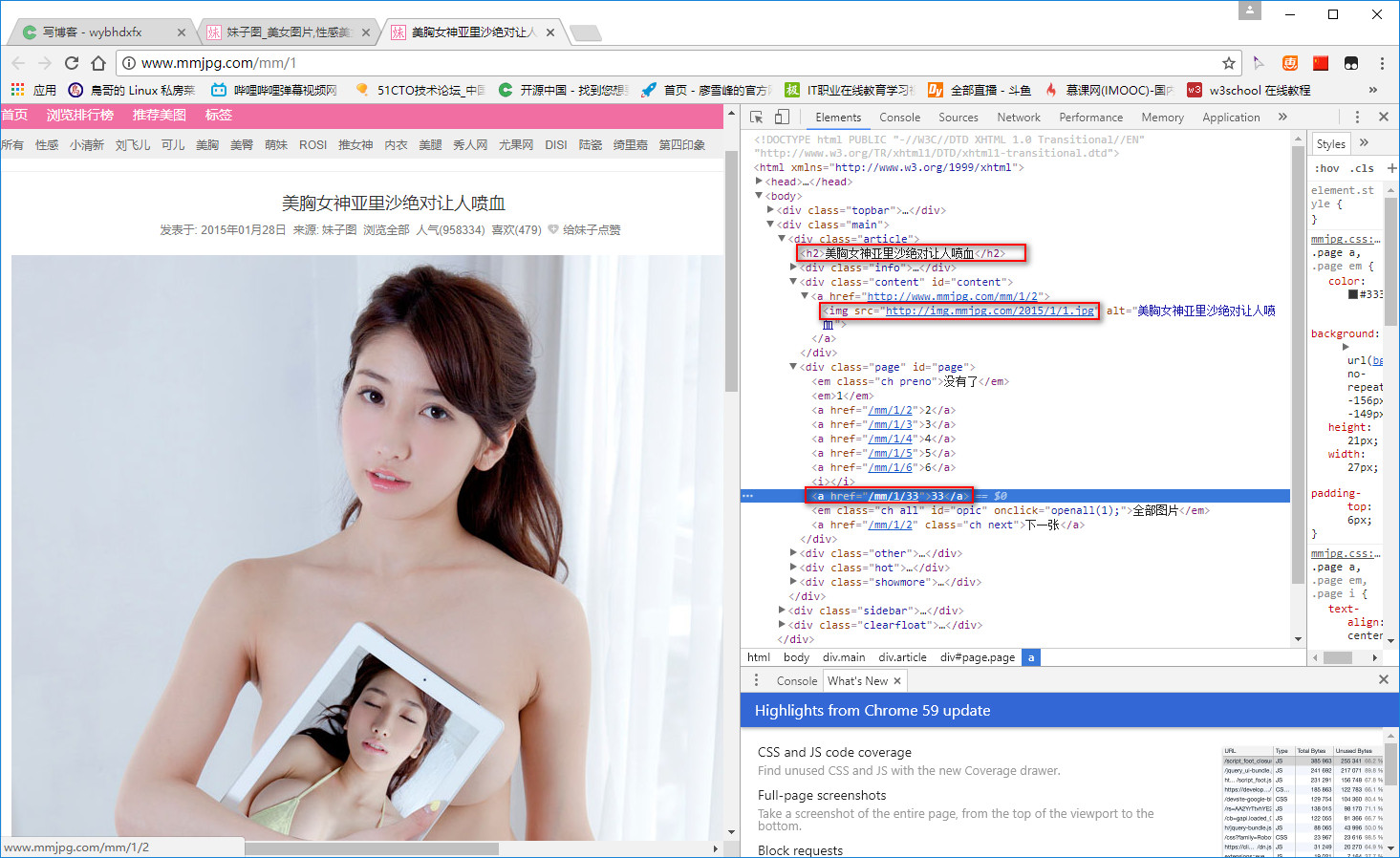
同样方法去网站最后一页验证:结果没错。
第三步:理清思路,构思框架
首先,目标网站的美女套图网页地址都是有规律的,从第一个套图网页:http://www.mmjpg.com/mm/1 到最新的套图网页:http://www.mmjpg.com/mm/1038 ,地址变的是最后的数字,数字代表是第几个套图,并且是递增。那我们可以通过手动构造每个套图网页url,然后,通过解析每个套图网页内容,可以得到套图标题,图片url和多少页(张)。同时,每张图片url也有规律:http://img.mmjpg.com/y/x/z.jpg ,y 是2015、2016、2017 中的一个,x 是第几个套图,z 是套图中的第几张图。
第四步:代码实现
-
获取网站的总套图数。
# 获取网站的总妹子套图网页函数 def get_web_sum(): req = request.Request('http://www.mmjpg.com/', headers=headers) response = request.urlopen(req) conent = response.read().decode('utf-8') soup = BeautifulSoup(conent, 'html.parser') web_number = soup.find("a", href=re.compile("http://www.mmjpg.com/mm/\d+")).attrs["href"] # 获取第一个最新套图url web_sum = int(re.sub("\D", "", str(web_number))) # 从最新套图url中提取总套图网页数 return web_sum # 返回总套图网页数 -
获取套图标题,总页数,以及 y 对应的日期。
while first_web_page < last_web_page + 1: get_url = "http://www.mmjpg.com/mm/" + str(first_web_page) + "/" + "1" # 构造网页url 如:http://www.mmjpg.com/mm/1 req = request.Request(get_url, headers=headers) response = request.urlopen(req) conent = response.read().decode('utf-8') soup = BeautifulSoup(conent, 'html.parser') get_page_title = soup.findAll("h2") # 提取网页标题 for i in get_page_title: page_title = str(i.get_text()) # 返回网页标题 get_page_sum = soup.findAll("a", href=re.compile("/mm/\d+/\d\d")) # 提取一个套图的总页数 for j in get_page_sum: page_sum = int(j.get_text()) # 返回一个套图总页数 get_page_url = soup.findAll("img", src=re.compile("http://img.mmjpg.com/20\d\d/\d+/\d+.jpg")) # 提取套图的图片url for k in get_page_url: page_url = k.attrs["src"] p = re.search(r'\d\d\d\d', str(page_url)) # 提取套图url里的数字,2017还是2016还是2015,方便下面构造图片url number = p.group() -
自定义一个下载图片函数。
# 下载图片函数 def download_image(image_url): req = request.Request(image_url, headers=headers) response = request.urlopen(req) get_img = response.read() return get_img -
创建文件夹,构造图片地址。
while i < page_sum + 1: img_url = "http://img.mmjpg.com/" + str(number) + '/' + str(first_web_page) + "/" + str( i) + '.jpg' # 构造图片url 如:http://img.mmjpg.com/2017/1038/1.jpg jpg_path = title_path + '/' + str(i) + '.jpg' # 构造图片命名格式 with open(jpg_path, 'wb') as fp: fp.write(download_image(img_url)) print("~~~爬啊~~~爬啊~~~爬~~~,第%02d张图片下载完成啦!~~~" % i) i = i + 1 time.sleep(1) # 设置每张图片爬取时间间隔,默认1秒,可以更改。 print("该网页图片下载完毕,准备爬取下一个网页!\n") first_web_page = first_web_page + 1 -
记录爬虫时间。
time_end = time.time() # 记录爬虫结束时间 time_s = int(time_end - time_start) # 爬虫运行的时间 m, s = divmod(time_s, 60) h, m = divmod(m, 60) print("用时: " + "%02d:%02d:%02d" % (h, m, s)) -
完整代码。
from urllib import request from bs4 import BeautifulSoup import re import os import time import urllib # 构造header 模拟浏览器访问 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'Connection': 'keep-alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' } # 获取网站的总妹子套图网页函数 def get_web_sum(): req = request.Request('http://www.mmjpg.com/', headers=headers) response = request.urlopen(req) conent = response.read().decode('utf-8') soup = BeautifulSoup(conent, 'html.parser') web_number = soup.find("a", href=re.compile("http://www.mmjpg.com/mm/\d+")).attrs["href"] # 获取第一个最新套图url web_sum = int(re.sub("\D", "", str(web_number))) # 从最新套图url中提取总套图网页数 return web_sum # 返回总套图网页数 # 下载图片函数 def download_image(image_url): req = request.Request(image_url, headers=headers) response = request.urlopen(req) get_img = response.read() return get_img # 主程序 print("\n\n~~爬虫准备开始!~~\t目标网站: http://www.mmjpg.com/\n") print("正在获取目标网站的总网页数:") print("请稍候...") web_sum = get_web_sum() # 获得爬取网站的总网页数 time.sleep(1) # 设置等待一秒 print("获取成功: %d\n" % web_sum) first_web_page = int(input("请问你想从第几个网页开始爬?(int)?\n")) last_web_page = int(input("请问你想爬到第几个网页?(不要超过总网页数)\n")) print("okay,现在爬虫开始!!!\n") time_start = time.time() # 记录爬虫开始时间 while first_web_page < last_web_page + 1: get_url = "http://www.mmjpg.com/mm/" + str(first_web_page) + "/" + "1" # 构造网页url 如:http://www.mmjpg.com/mm/1 req = request.Request(get_url, headers=headers) response = request.urlopen(req) conent = response.read().decode('utf-8') soup = BeautifulSoup(conent, 'html.parser') get_page_title = soup.findAll("h2") # 提取网页标题 for i in get_page_title: page_title = str(i.get_text()) # 返回网页标题 get_page_sum = soup.findAll("a", href=re.compile("/mm/\d+/\d\d")) # 提取一个套图的总页数 for j in get_page_sum: page_sum = int(j.get_text()) # 返回一个套图总页数 get_page_url = soup.findAll("img", src=re.compile("http://img.mmjpg.com/20\d\d/\d+/\d+.jpg")) # 提取套图的图片url for k in get_page_url: page_url = k.attrs["src"] p = re.search(r'\d\d\d\d', str(page_url)) # 提取套图url里的数字,2017还是2016还是2015,方便下面构造图片url number = p.group() print("正在爬取第%d个网页:" % first_web_page) print(str(page_title) + ":" + str(get_url)) print("该网页一共有%d张图片,请耐心等候!" % page_sum) title_path = str(first_web_page) + "-" + str(page_title) os.mkdir(title_path) # 创建以标题为命名的文件夹 i = 1 while i < page_sum + 1: img_url = "http://img.mmjpg.com/" + str(number) + '/' + str(first_web_page) + "/" + str( i) + '.jpg' # 构造图片url 如:http://img.mmjpg.com/2017/1038/1.jpg jpg_path = title_path + '/' + str(i) + '.jpg' # 构造图片命名格式 with open(jpg_path, 'wb') as fp: fp.write(download_image(img_url)) print("~~~爬啊~~~爬啊~~~爬~~~,第%02d张图片下载完成啦!~~~" % i) i = i + 1 time.sleep(1) # 设置每张图片爬取时间间隔,默认1秒,可以更改。 print("该网页图片下载完毕,准备爬取下一个网页!\n") first_web_page = first_web_page + 1 time.sleep(2) # 设置每个网页爬取时间间隔,默认2秒,可以更改。 time_end = time.time() # 记录爬虫结束时间 time_s = int(time_end - time_start) # 爬虫运行的时间 m, s = divmod(time_s, 60) h, m = divmod(m, 60) print("用时: " + "%02d:%02d:%02d" % (h, m, s)) print("爬取的图片全部已下载,请留意对应文件夹。") print('目标已经全部爬取完毕!over~~') print("______the end______")
第五步:测试、总结
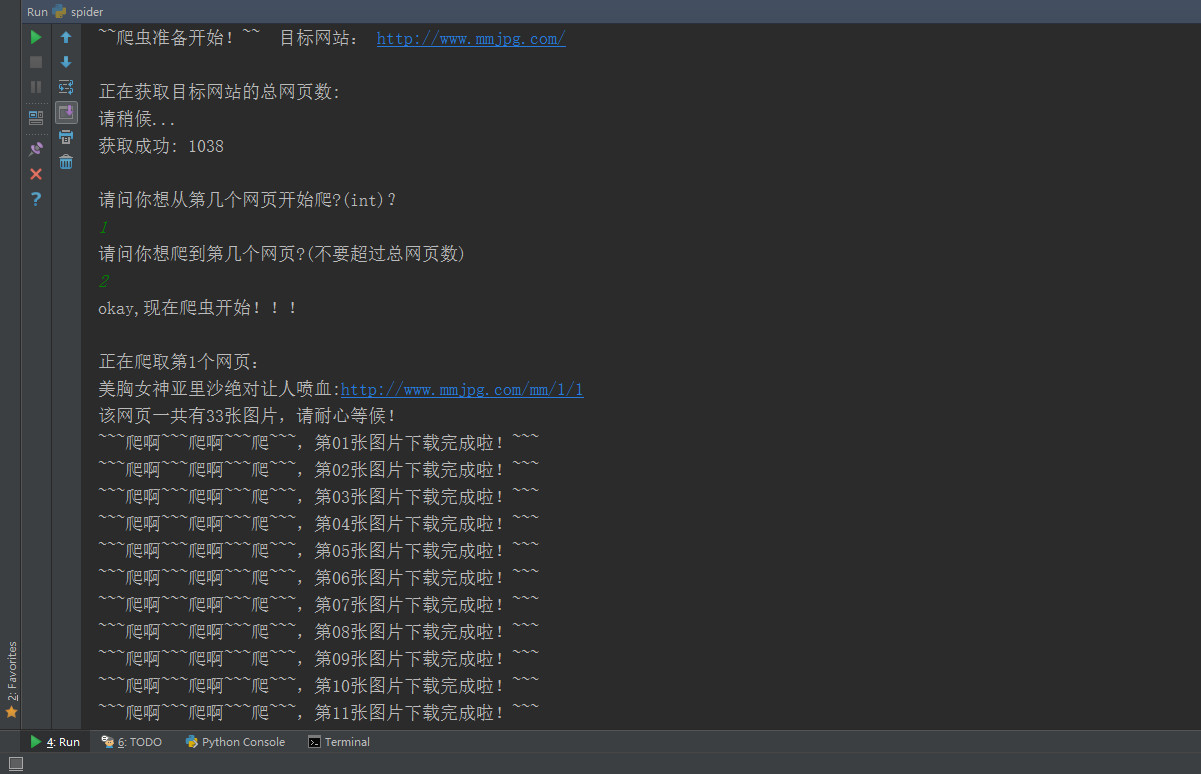
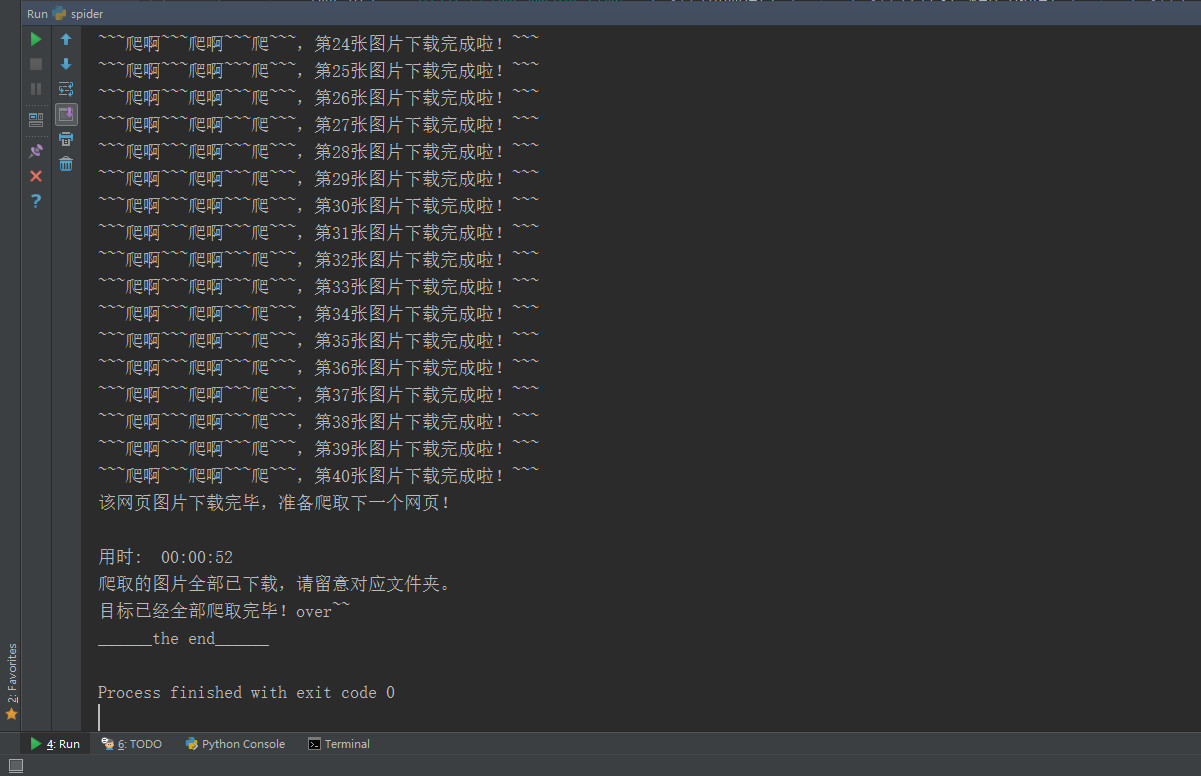
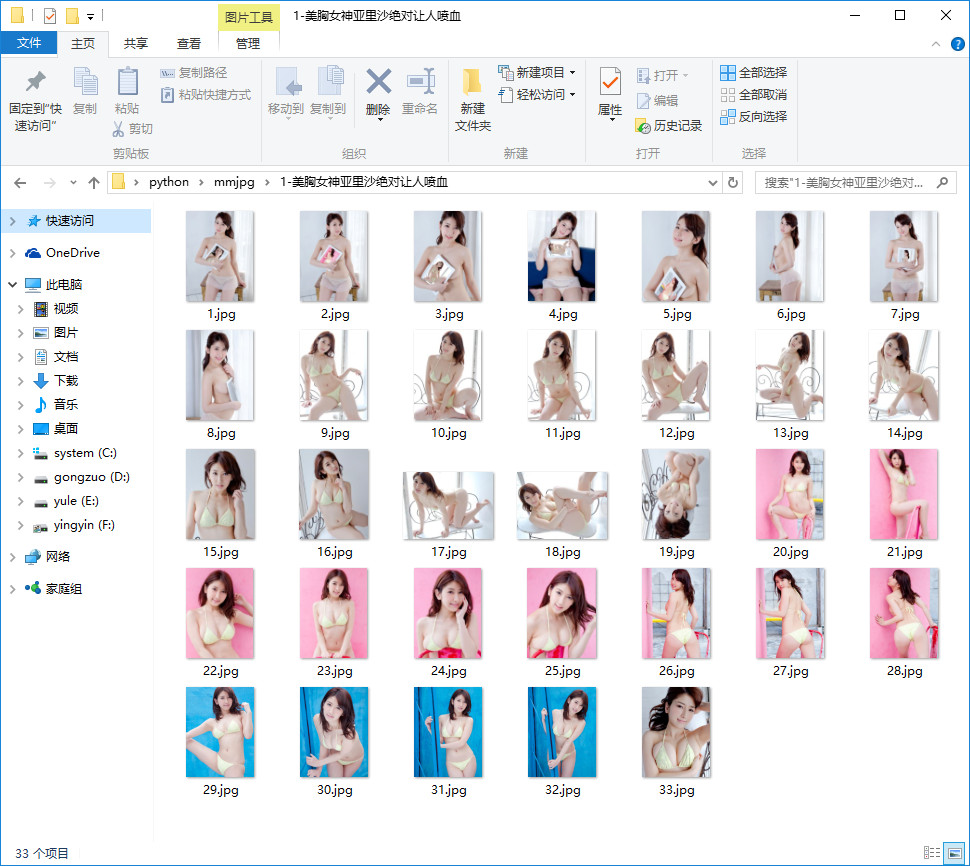
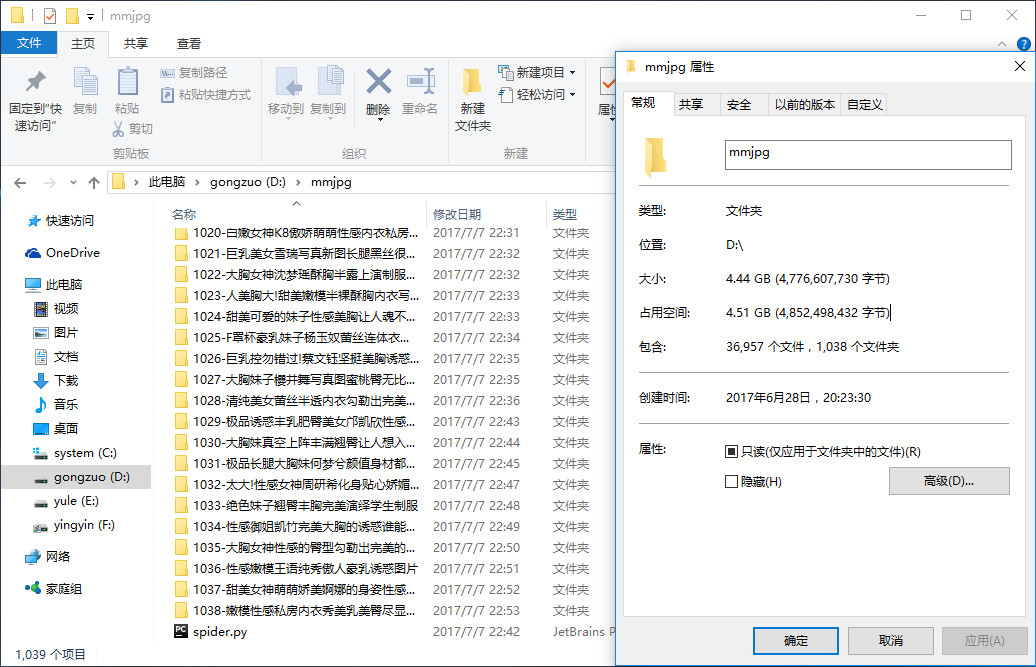
前几周就做好了这个小爬虫,遇到了一些小问题,比如之前代码里写了许多函数,导致重复请求网站,最终出现访问请求错误,这次尽量减少去请求网站,当然设置爬虫时间间隔长一点或许可以防止被封,设置ip池,应用多线程等。我知道此小脚本有很多不足的地方,大家可以分享你的想法。我写博客的目的是用来记录我学习成长过程。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









