






前言:
新人简单尝试,高手请忽略吧!
此文章禁止转载!
缩放网页可看清图片!
实验环境:win10 + python3.6 + pycharm
第三方库: beautifulsoup
爬虫开始:
第一步:确立目的
目的的把豆瓣top250: https://movie.douban.com/top250 上的电影信息保存下来,包括:排名、电影名、评分、简评和电影封面图片。
第二步:开始分析
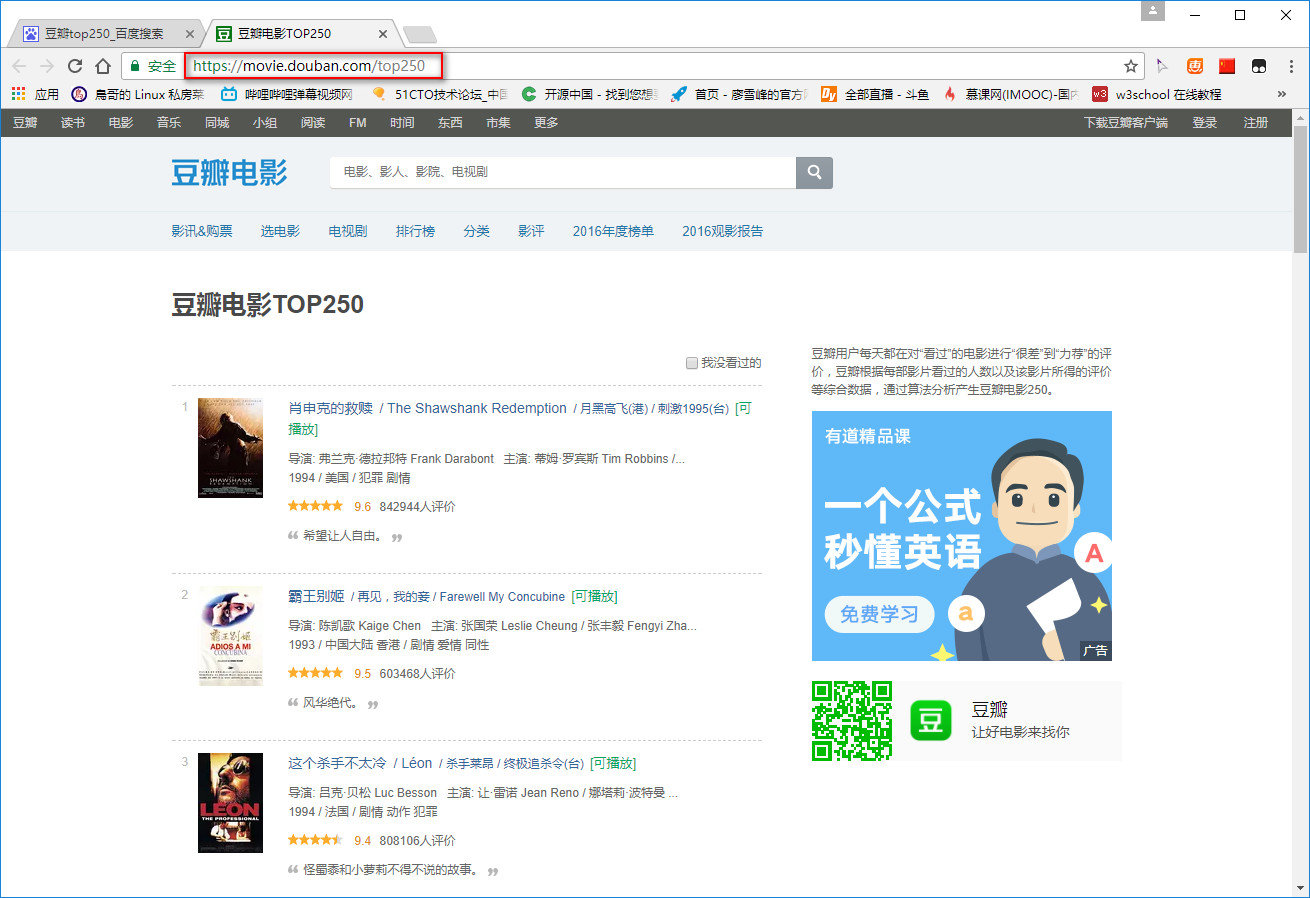
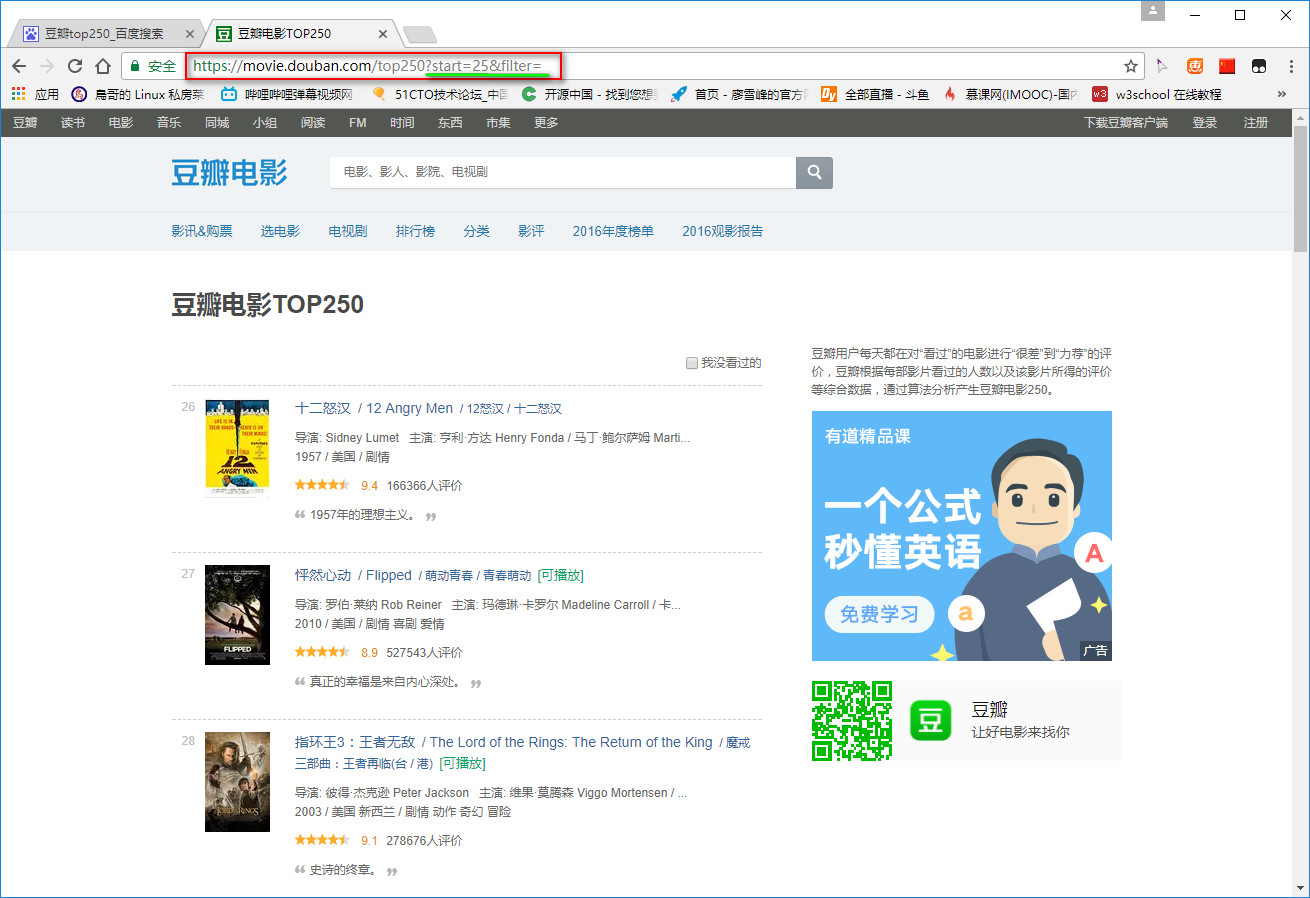
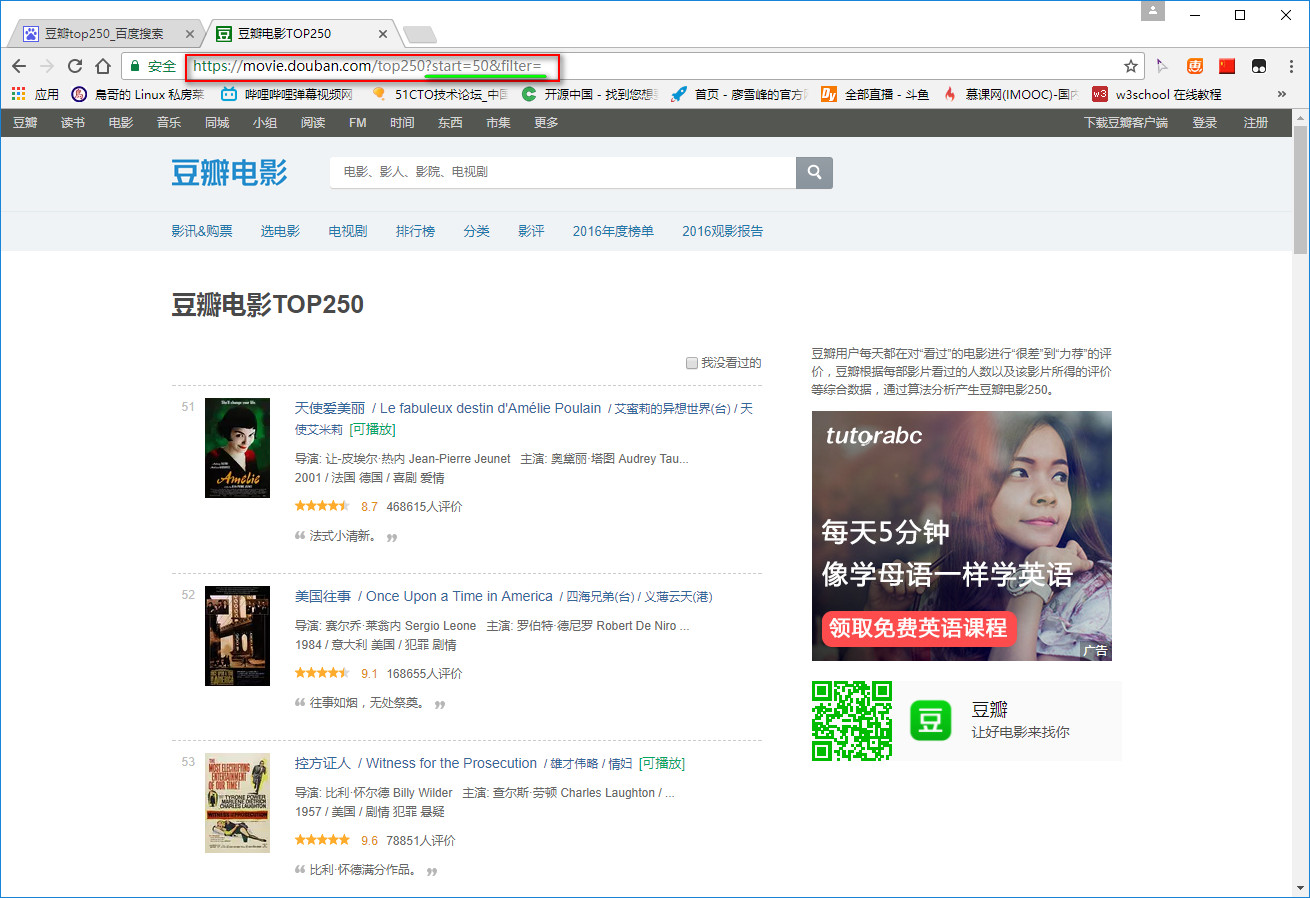
习惯性用chrome浏览器打开目标网站:https://movie.douban.com/top250,发现一页有25部影片,拉到底翻到第二页,观察网址变化。可以发现第二页网址变为:https://movie.douban.com/top250?start=25&filter= ,再翻到第三页网址变为:https://movie.douban.com/top250?start=50&filter= 。
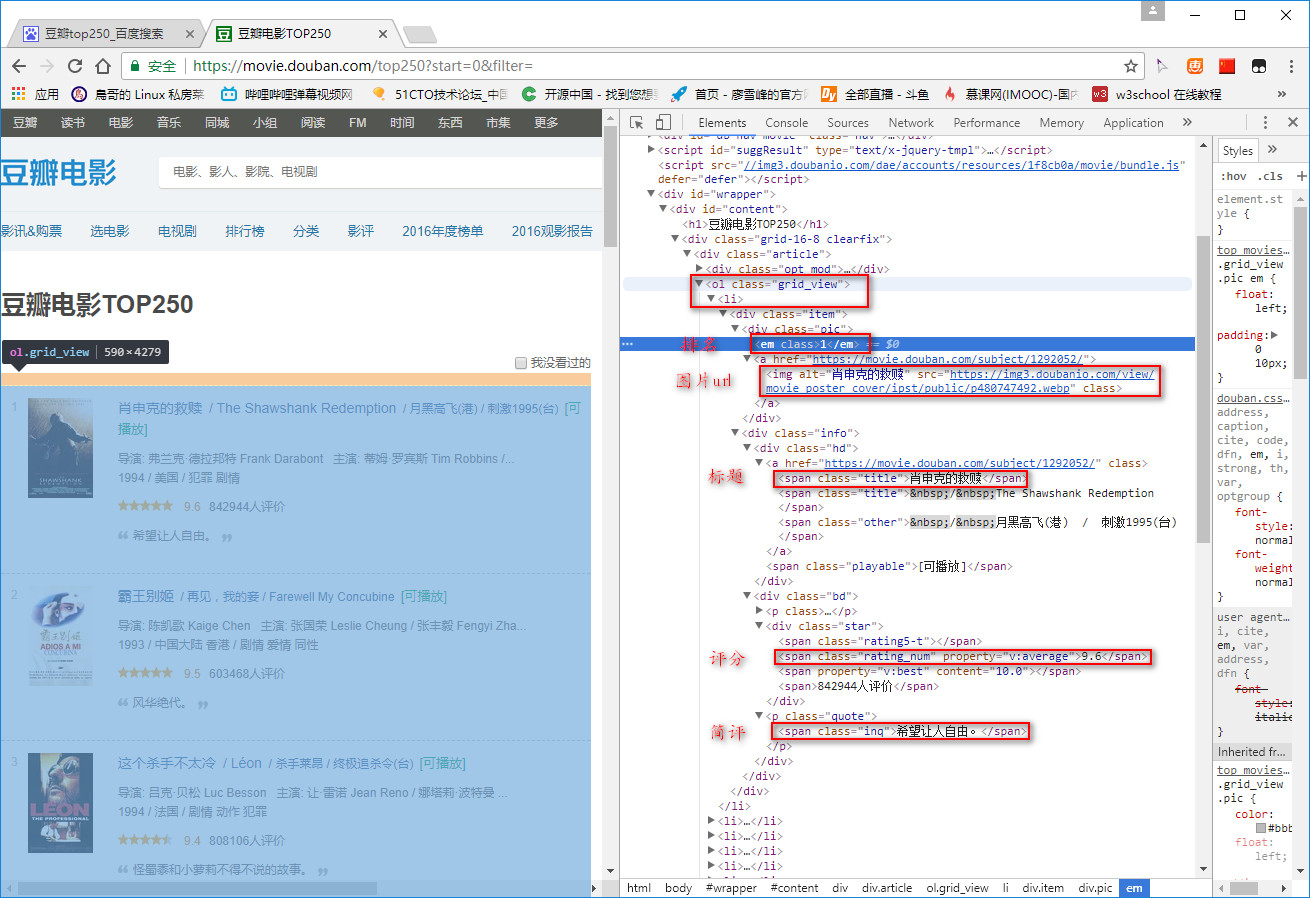
接下来按F12分析网页内容,容易找到25部影片所在的标签<ol>,同时也容易找到电影名、排名、图片url、评分和简评。
第三步:理清思路,构思框架
通过来回在 https://movie.douban.com/top250 翻页,可以发现规律:网址其实是https://movie.douban.com/top250?start=xx&filter= ,其中 xx 是从第一页0 到第二页25 到第三页50,每页递增25(即每页25部电影),共10页。每页所需信息都在<ol> class=grid_view下,不难发现影片排名、电影名、图片url、评分和简评所在的标签。这次采用简单框架的方式去实现爬取,分为:爬虫调度主文件:spider_main.py、HTML下载器:html_downloader.py、HTML解释器:html_parser.py、HTML输出器:html_outputer.py
第四步:代码实现
- spider_main.py
from douban_spider import html_downloader, html_parser, html_outputer from bs4 import BeautifulSoup class SpiderMain(object): def __init__(self): self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def crawl(self, new_url): html_cont = self.downloader.download(new_url) new_data = self.parser.parse_data(html_cont) self.outputer.collect_data(new_data) if __name__ == "__main__": print('爬虫开始:\n') obj_spider = SpiderMain() for i in range(0, 10): url = 'https://movie.douban.com/top250?start=%d&filter=' % (i * 25) # 构造爬取网页url print('正在爬取:%s' % url) obj_spider.crawl(url) obj_spider.outputer.output() print('爬虫完毕。\n') -
html_downloader.py
import urllib.request class HtmlDownloader(object): @staticmethod def download(new_url): if new_url is None: return None response = urllib.request.urlopen(new_url) print('正在下载网页内容...') if response.getcode() != 200: return None return response.read() -
html_parser.py
from bs4 import BeautifulSoup class HtmlParser(object): @staticmethod def parse_data(html_cont): print('正在解析网页内容...') soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8') data = [] for li in soup.find('ol', class_='grid_view').findAll('li'): index = li.find('em').get_text() # 排名 title = li.find(class_='title').get_text() # 标题(电影名) picUrl = li.find('img').get('src') # 图片url score = li.find(class_='rating_num').get_text() # 评分 try: # 经过后期发现,有些影片没有电影简介, 如:疯狂动物城 brief = li.find(class_='inq').get_text() # 一句话介绍 except: brief = ' ' dic = {'index': index, 'title': title, 'pic': picUrl, 'score': score, 'brief': brief} data.append(dic) return data -
html_outputer.py
import os import urllib class HtmlOutputer(object): def __init__(self): self.data = [] def collect_data(self, new_data): print('正在收集所需信息...\n') self.data.append(new_data) def output(self): print('正在储存收集的信息...') print('请稍等!\n') file = open('douban.txt', 'w', encoding='utf-8') for arr in self.data: for item in arr: self.save_text(file, item) self.save_images(item) print('储存完毕!\n') file.close() def save_text(self, file, item): content = '排名: '+ item['index'] + ' ' + '影片: '+item['title'] + ' ' + '评分: '\ +item['score'] + ' ' + '介绍: '+item['brief'] file.write(content) file.write('\n\n') def save_images(self, item): if os.path.exists('pics') == False: os.mkdir('pics') filename = item['index'] + "-" + item['title'] + '.jpg' resource = urllib.request.urlopen(item['pic']) data = open('pics/%s' % filename, 'wb') data.write(resource.read()) data.close()
第五步:测试、总结
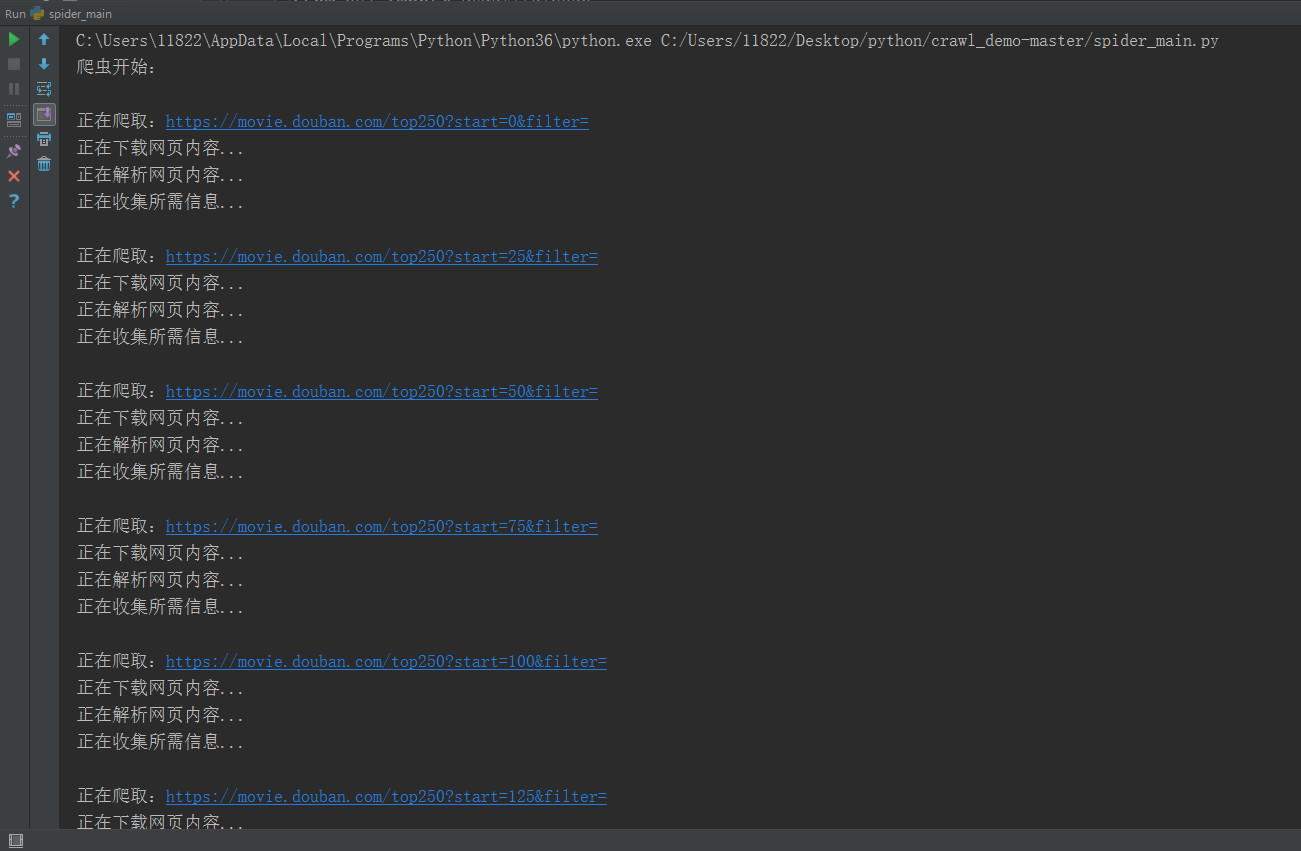
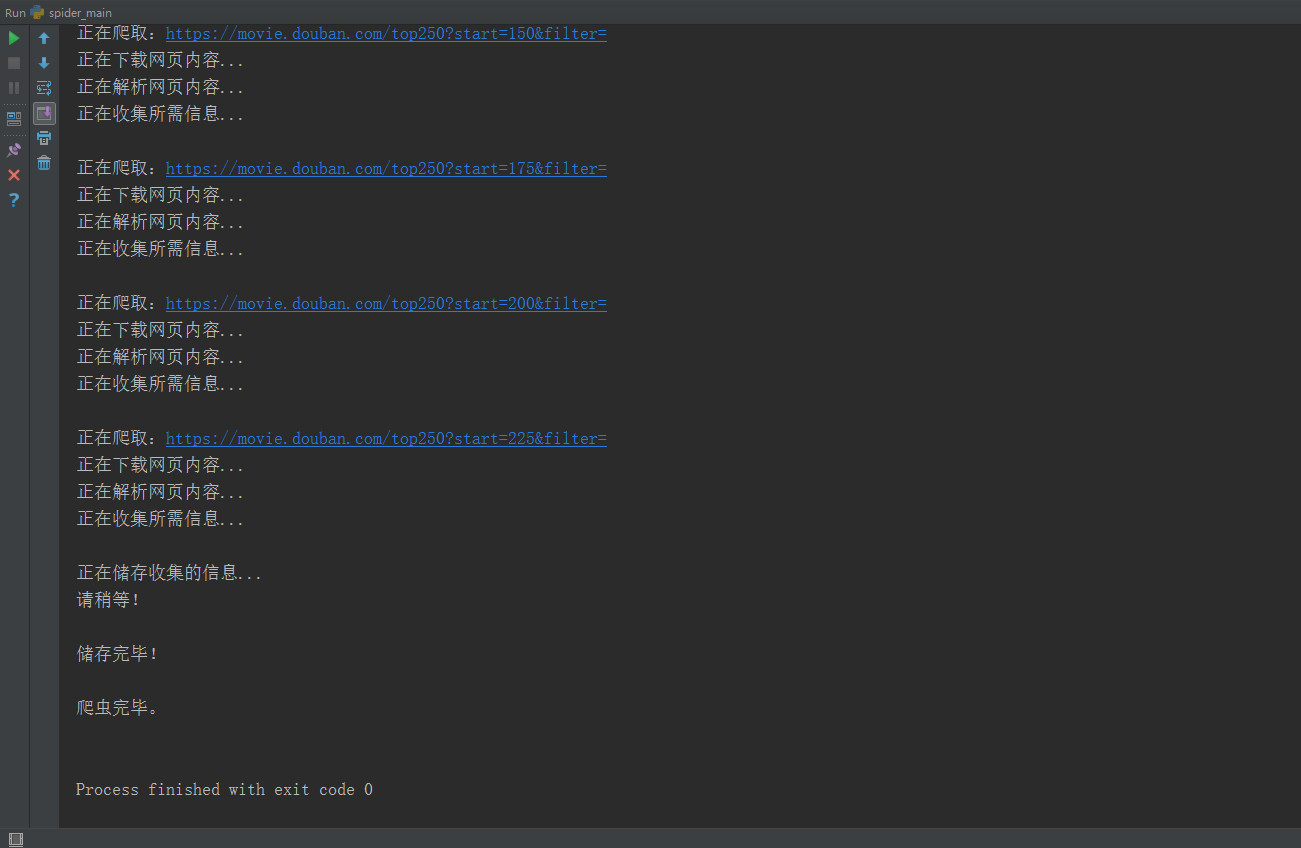
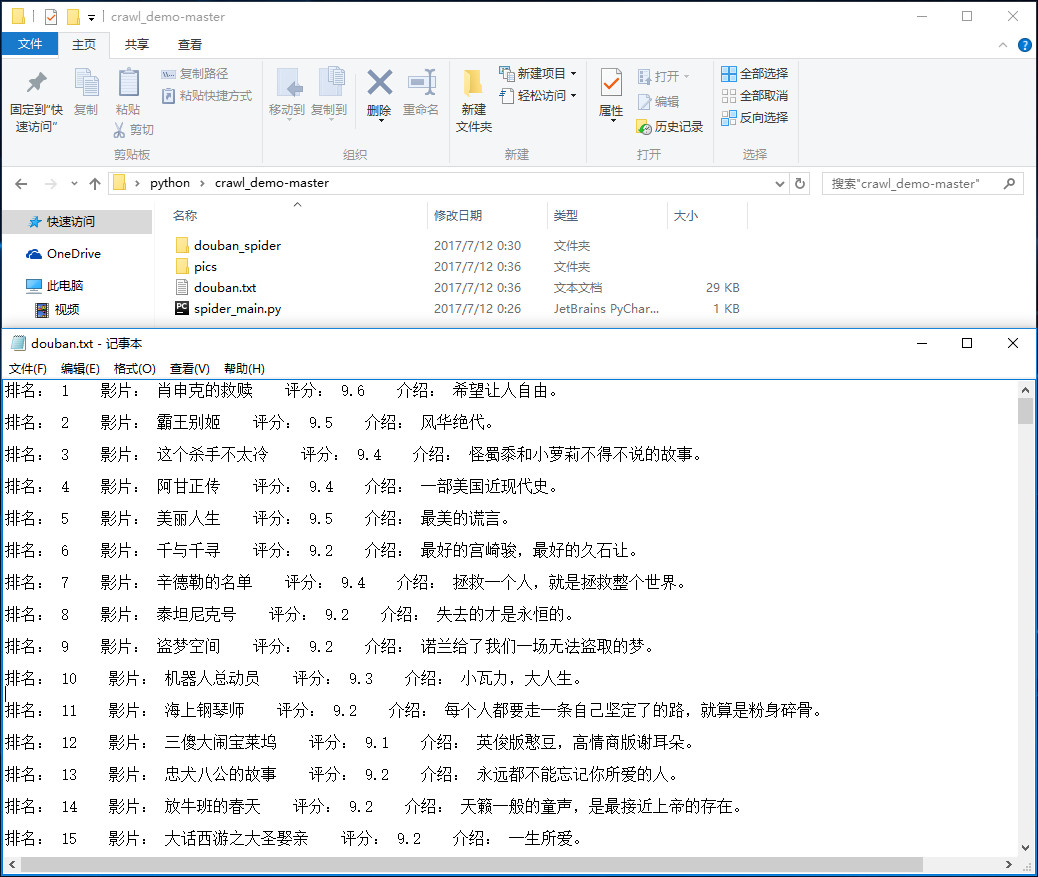
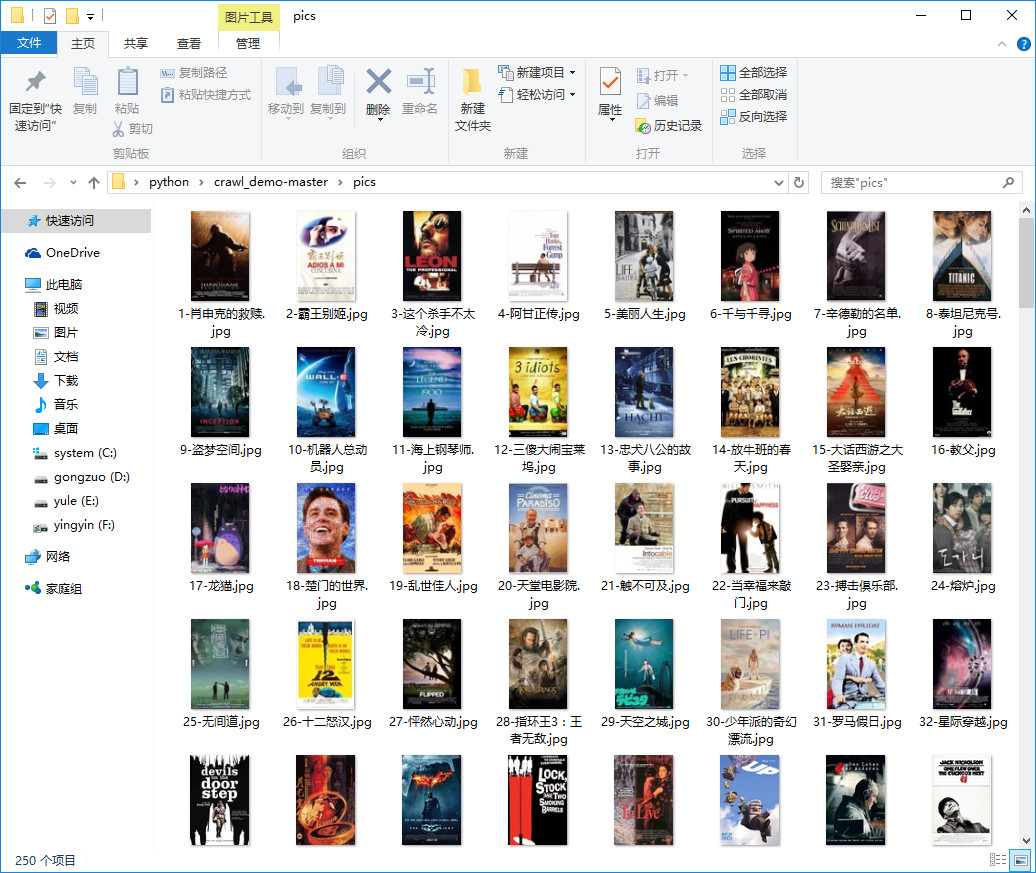
爬取豆瓣电影top250也不算难,容易爬取,这次主要是采用类似框架的代码去实现,有比较清晰的思路。
想学习可以参考慕课网的讲解:http://www.imooc.com/learn/563
完。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









