






四个创新点:
一)ReLU
在梯度下降中,不饱和非线性比饱和非线性快很多。
二)在双GPU上训练
双显卡并行计算,只和各自相关显卡的上一层有关联,加快速度。
三)LRN
ReLU不需要归一化防止过饱和,不过仍然发现以下公式帮助归一化。
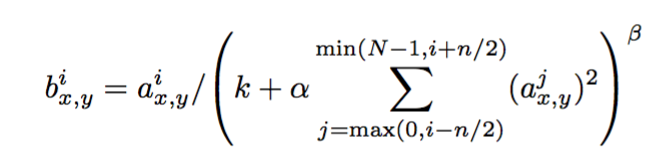
(x,y)位置,i kernal,k, n, a,b 是超参数(无特定含义的字的参数)。
四)重叠池化
错误率下降0.4%和0.3%(top-1 和 top-5)
避免过拟合的方法:
一)数据变化(镜面、平移、PCA变换等)
二)dropout
整体结构:
八个学习层,包含五个卷积层和三个全连接层。
 \\
\\















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









