







1月准备考数据结构;成天窝在家里鼓捣这玩意.现在勉强弄出了个可以实用的树和图的库.接下来是实现树和图的各种算法.说到算法必然就要有用来测试的数据.这几天在弄树.刚开始是从文件系统来构造.但是每次从硬盘文件系统构造不但要花大量的时间而且过于复杂不方便测试.书上有不少例子,但是问题是数据结构书上的方法都是在代码内手动编码构造.说实在写着很憋屈.现在不都是自动化的时代了么?回想起某书上所说的”纯文本的威力”,再加上上次做图的时候为图弄了个脚本引擎来记录图的架构;于是觉定为树结构也弄一个.
首先想到的自然是XML.XML有现成的引擎,XML有标准的支持;但是XML书写之麻烦…弄出来后感觉比手动硬编码轻松不了多少.在考虑了不到两分钟后决定放弃转而弄自己的脚本.
接下来就是脚本的设计…回想做图结构的脚本我是这样设计的:
//Graph定义文件
//语法:
//以//开头的行为注释
//连接符:
//a->b
//表示a到b间有一条以a起始止于b的路径
//a<->b表示a与之间是互通的
//每行定义为路径的名称,后面跟路径的定义,以冒号分隔;
//每个定义以分号表示结尾;
//节点&路径命名规则:
//字数无限制,字符必须是a-z A-Z 0-9中的字符
//defnode 用于定义节点(可选,用于定义没有出度入度的孤立点)
defnode a,b,c,d,e,f,g;
12:a -> c;
15:b->e;
//c
30:c->b;
3:c->e;
//d
8:d->b;
//e
40:e->d;
5:e->f;
//f
40:f->a;
10:f->d;
但树和图不太一样,树主要保存节点之间的父子兄弟关系.没必要记录边.先是翻了半天数据结构的书,找到了通过前序/后序遍历序列 + 中序遍历序列构造二叉树的方法.而树是可以转成二叉树的.嗯…于是第一种方案出来了,使用两行节点序列构造二叉树后通过”左儿子右兄弟”的法则再构造成树:
节点1,节点2,节点3,……,节点N
节点1,节点2,节点3,……,节点N
正当我准备动手做解析器的时候某人给我提出异议:
这玩意但是表达二叉树就已经够麻烦了;做比较复杂的树比如有十来个节点的难不成要先在脑内补完成二叉树后再写出来?
……
…
囧……我把这茬儿给忘了,光想着怎么以文本表达节点间关系了.这样弄不是比硬编码更麻烦嘛?还好还没开始编码.谢天谢地.亲手删掉写了半天的代码会是很痛苦的事…
接下来脚本的设计目标就很明显了:
1. 要便于使用文本编辑器直接书写.
2. 要直观.不用解析器也能很好的表达节点间的关系.
在换了n个方案后,(其实前后也就几分钟)在我无聊的点击VS代码编辑器里的+号玩的时候;才想到C++/C#的类语法不就是很好的表达了节点关系的东东嘛:将类看做是父节点,内部可以包含子结点(嵌套类/类方法).而且也很直观.于是就有了这么个设计方案:
//树的构成脚本.
//脚本仅描述了树节点间的关系,并不携带节点数据信息
//脚本语法:
//双斜杠"//"开头的行为注释.
//节点命名规则:只能包含a-z A-Z 或 0-9中的字符
//节点名称可以重复出现,有节点名的地方仅表示"这里有一个节点"而已
//如果一个节点没有子结点.则以分号";"结尾.如:n;
//如果一个节点有子结点则紧跟节点名的是一对大括号,大括号必须配对,其子结点写在大括号内.
//大括号可以嵌套 例: a{b; c{d;}}
//一段脚本只可包含一个根结点.即只能包含一棵树;拥有多个根的脚本解析虽然不会出错,但仅会解析第一棵树
a{//根结点
//子树
b111{
c;
//子树中的子树
d{
e;
}
}
//单个的节点
f;
gn;
h;
//还是子树
i{
j;
k;
}
l;
//仍然是子树
m{
n;
}
q;
}
接下来就是脚本的解析器了.先是设计了一个简单的类FSM:
/// <summary>
/// 一个简单的有限状态机
/// </summary>
/// <typeparam name="S"></typeparam>
class FSM
{
public int State
{
get;
set;
}
int m_stopState;
Action<FSM,int> m_proc;//状态的转换处理函数
public FSM(int initState, int stopState, Action<FSM,int> proc)
{
State = initState;
m_stopState = stopState;
m_proc = proc;
}
public void Run()
{
while (State.CompareTo(m_stopState)!=0)
{
m_proc(this,State);
}
}
}
用它来记录脚本代码扫描的状态.
然后为Tree添加一个静态的Parse方法:
Tree <T> Parse(string script,Func <string,T> valfunc);
Valfunc用于在构造树节点的时候通过节点名获取节点数据.结合C#的Lambda表达式,将节点数据的保存/获取交给调用方实现.可以让树的存储/读取变得更加的灵活.
然后在Parse中先对脚本做预处理:
script = Regex.Replace(script, "//.*//n", "");//去除注释
script = Regex.Replace(script, "//s*", "") ;//去除无用的空白
PS:这是头一次写正则表达式一次成功.泪奔ing…
经过这个处理后形如
A{
B{
C;
}
D;
}
的代码就会变成这样:
A{B{C;}D;}
的代码.然后内部新建了一个解析器类scriptParser,送进去进行解析.
至于scriptParser的实现….先添加一个FSM成员,然后为它定义3种状态:
const int Symbol = 0;//当前状态为取符号
const int Match = 1;//正在配对花括号或分号
const int Complete = 3;//解析完成,结束
然后定义成员函数nextword用于每调用一次从脚本中读取出一个节点名(这里称之为Symbol)或是一个特殊符号(花括号或分号).并自动增加字符串中的游标curPos.然后开始考虑如何提取每个节点名的问题:
FSM的初始态为Symbol;此时解析器将期盼获取一个节点名.
在获取一个Symbol后,它将尝试匹配一对花括号或者一个分号.
编写FSM的回调函数void parseProc(FSM fsm, int state)
第一行先读取一个字符串:
string word = nextword();
然后开始处理这个word:
switch (state)
{
case State.Symbol:
fsm.State = State.Match;
break;
case State.Match
switch (word)
{
case "{":
//接下来期望取得的将是一个节点
fsm.State = State.Symbol;
//定义一个int match用于配对花括号
match++;
break;
case "}":
{
//先保存curPos
int tmp = curPos;
//下一个可能会跟花括号
if (nextword() != "}")
{
fsm.State = State.Symbol;
}
//恢复curPos
curPos = tmp;
match--;
}
break;
case ";":
{
int tmp = curPos;
//分号后可能会跟花括号
if (nextword() != "}")
{
fsm.State = State.Symbol;
}
curPos = tmp;
}
break;
default:
throw new Exception(string.Format("非法符号/"{0}/"", word));
}
break;
}
if (curPos >= m_script.Length - 1)
{
//读取完毕,置为终止状态
fsm.State = State.Complete;
}
这样.在case Symbol:中取到的word将都是节点名.调用FSM.Run()反复执行这条函数的话.将会得到一个节点名的序列;接下来考虑如何将这个序列变成一棵树.
说到构造树,最常用的数据结构就是栈.定义一个类成员Stack <TreeNode> nodeStack;用于存储节点.
然后在处理节点符号的地方加上这些语句:
TreeNode node;
//获取节点值
T value = valfunc(word);
//m_result为最终返回的Tree<T>
if (m_result == null)
{
//树尚未被构建出来,先构造一个树
m_result = new Tree<T>(value);
node = m_result.Root;
}
else
{
node = new Tree<T>.TreeNode(value);
//栈顶的节点将是这个节点的父节点
nodeStack.Peek().Children.Add(node);
}
//无论如何,将新的节点压入栈
nodeStack.Push(node);
//改变fsm的状态
fsm.State = State.Match;
这样,决定下一个节点是否为当前节点的子节点的关键就在nodeStack的Pop操作上了.首先是对分号的处理.因为一个以分号结尾的节点没有子结点.所以在处理”;”的时候加上一条nodeStack.Pop ();对于”{“,它代表接下来直到配对的”}”前的所有节点都是当前节点的子结点.所以在处理”{“的时候什么都不做,而在处理”}”的时候加上一条nodeStack.Pop ();
完整的parseScript:(加上了简单的语法检错)
void parseProc(FSM fsm, int state)
{
//读取下一个词/符号
string word = nextword();
switch (state)
{
case State.Symbol:
//验证节点命名的合法性
if (validateSymbol(word))
{
TreeNode node;
T value = valfunc(word);
if (m_result == null)
{
m_result = new Tree<T>(value);
node = m_result.Root;
}
else
{
node = new Tree<T>.TreeNode(value);
nodeStack.Peek().Children.Add(node);
}
nodeStack.Push(node);
fsm.State = State.Match;
}
else
{
throw new Exception(string.Format("/"{0}/"不是一个合法的标识符", word));
}
break;
case State.Match:
switch (word)
{
//接下来期望取得的将是一个节点
case "{":
fsm.State = State.Symbol;
match++;
break;
case "}":
{
int tmp = curPos;
//下一个可能会跟花括号
if (nextword() != "}")
{
fsm.State = State.Symbol;
}
curPos = tmp;
nodeStack.Pop();
match--;
}
break;
case ";":
{
int tmp = curPos;
//分号后可能会跟花括号
if (nextword() != "}")
{
fsm.State = State.Symbol;
}
curPos = tmp;
nodeStack.Pop();
}
break;
default:
throw new Exception(string.Format("非法符号/"{0}/"", word));
}
break;
}
if (curPos >= m_script.Length - 1)
{
fsm.State = State.Complete;
}
}
这样就能由简单易写的脚本构造出各种树的结构了.比起照着书上的例子一行一行录入代码构成树要省下大量的时间J
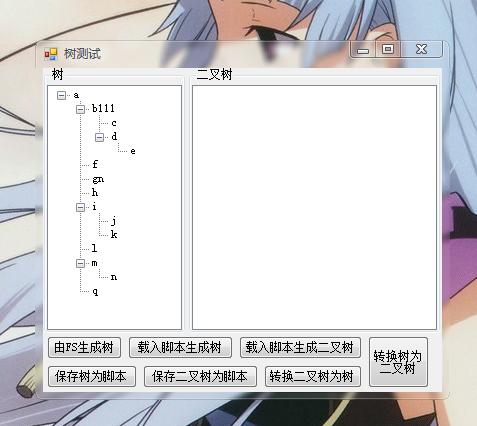
接下来编译运行测试这段代码:
a{//根结点
//子树
b111{
c;
//子树中的子树
d{
e;
}
}
//单个的节点
f;
gn;
h;
//还是子树
i{
j;
k;
}
l;
//仍然是子树
m{
n;
}
q;
}
在按钮事件中编写代码:
//读取脚本
var s = LoadScript();
if (s == null)
return;
//直接用节点名当作节点数据
Tree<string> t = Tree<string>.Parse(s, (n) => { return n; });
treeView.Nodes.Clear();
treeView.ShowTree(t);
运行后的结果:















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









