







环境配置
#一、下载镜像
#安装docker 环境
yum install docker*
docker pull elasticsearch:7.8.0
#二、修改系统内核参数
#root用户修改/etc/security/limits.conf,添加如下,提高进程及资源使用限制上线
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
source /etc/profile
#修改/etc/systemd/system.conf,添加如下
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
systemctl daemon-reload
systemctl daemon-reexec
vi /etc/sysctl.conf
#添加参数
vm.max_map_count = 262144
sysctl -p
#创建数据目录
mkdir -p /home/es{1..3}
#配置文件权限
chmod 777 -R /home/es{1..3}
#创建专用docker网络
docker network create es --subnet 1.1.1.0/24yml配置文件elasticsearch.yml,此文件放置到es1、es2、es3目录下面
#集群名称 所有节点名称一致
cluster.name: es-clusters
#当前该节点的名称,每个节点不能重复es-node-1,es-node-2,es-node-3
node.name: es-node-1
#当前该节点是不是有资格竞选主节点
node.master: true
#当前该节点是否存储数据
node.data: true
#设置为公开访问
network.host: 0.0.0.0
#设置其它节点和该节点交互的本机器的ip地址,三台各自为
network.publish_host: 1.1.1.10
# 设置映射端口
http.port: 9200
# 内部节点之间沟通端口
transport.tcp.port: 9300
#支持跨域访问
http.cors.enabled: true
http.cors.allow-origin: "*"
#配置集群的主机地址
discovery.seed_hosts: ["1.1.1.10", "1.1.1.20", "1.1.1.30"]
#初始主节点,使用一组初始的符合主条件的节点引导集群
cluster.initial_master_nodes: ["es-node-1", "es-node-2","es-node-3"]
#节点等待响应的时间,默认值是30秒,增加这个值,从一定程度上会减少误判导致脑裂
discovery.zen.ping_timeout: 30s
#配置集群最少主节点数目,通常为 (可成为主节点的主机数目 / 2) + 1
discovery.zen.minimum_master_nodes: 2
#配置集群最少正常工作节点数
#gateway.recover_after_nodes: 2
#禁用交换内存,提升效率
#bootstrap.memory_lock: true其中,需要配置3个yml文件,network.publish_host分别指定不同的IP:1.1.1.10,20,30; node.name分别指定不同的节点名:es-node-1,2,3
启动集群
docker run -d --name es-node-1 --hostname es-node-1 -p 19200:9200 -p 19300:9300 --network es --ip 1.1.1.10 -v /home/es1/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/es1:/usr/share/elasticsearch/data -e ES_JAVA_OPTS="-Xms1g -Xmx1g" --privileged elasticsearch:7.8.0
docker run -d --name es-node-2 --hostname es-node-2 -p 29200:9200 -p 29300:9300 --network es --ip 1.1.1.20 -v /home/es2/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/es2:/usr/share/elasticsearch/data -e ES_JAVA_OPTS="-Xms1g -Xmx1g" --privileged elasticsearch:7.8.0
docker run -d --name es-node-3 --hostname es-node-3 -p 39200:9200 -p 39300:9300 --network es --ip 1.1.1.30 -v /home/es3/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/es3:/usr/share/elasticsearch/data -e ES_JAVA_OPTS="-Xms1g -Xmx1g" --privileged elasticsearch:7.8.0使用华为浏览器或者谷歌浏览器,安装elastic插件,访问es数据库
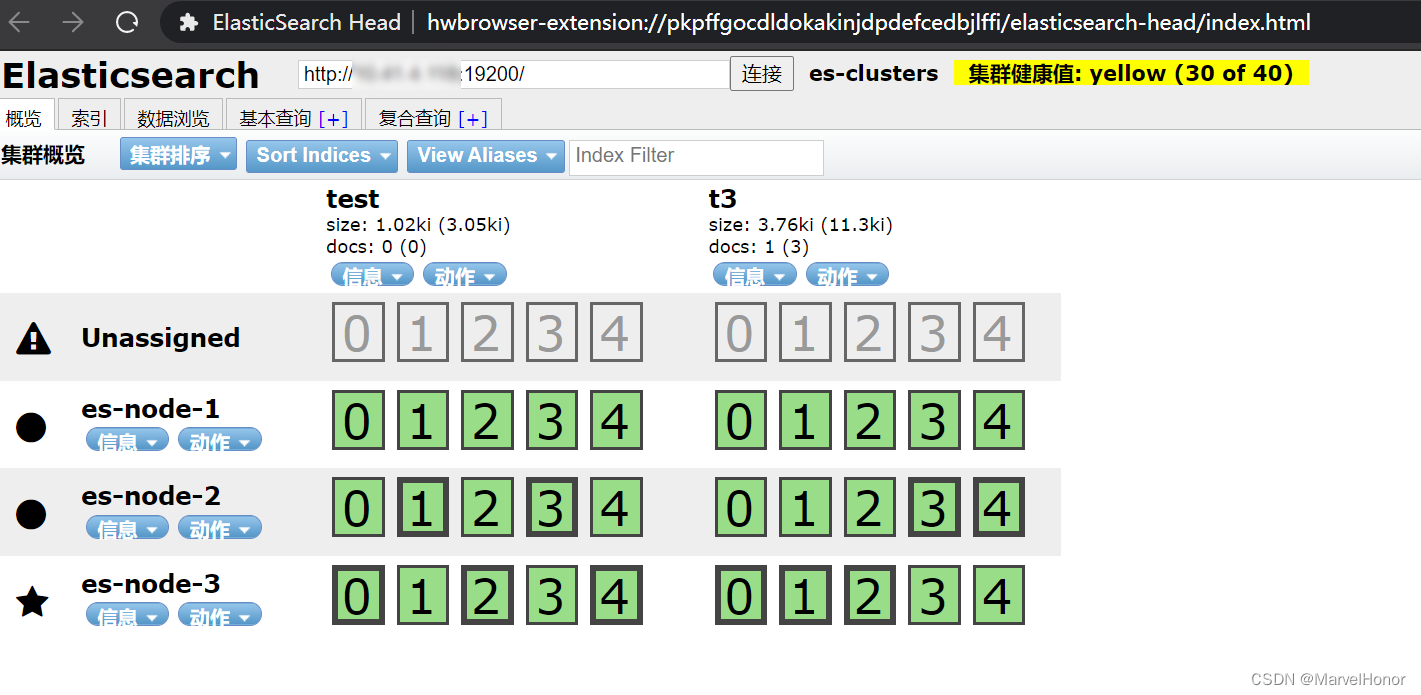
创建新的索引,配置为5个切片,3个副本。
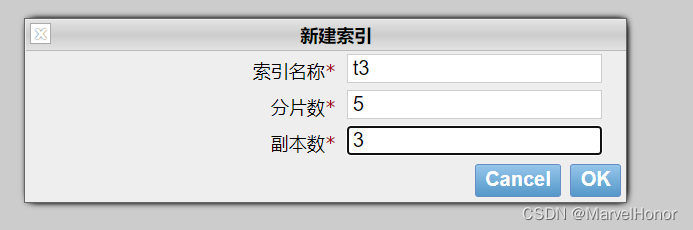
如上,可见集群选择了es-node-3为主节点,我们把3个节点都配置成了管理与数据节点。同时副本在3个节点上都成功同步了。
我们写入一条数据
curl http://127.0.0.1:19200/t3/doc/1 -X PUT -d '{"value":100}' --header 'content-type:application/json'
在5个分片中查询到了数据。
成功!
备注,我在部署的过程中出现了有个节点无法加入集群的问题,其实这个问题很好解决,我遇到的是es-node-1无法加入,只需要把es-node-1的持久化层/home/es1目录删除,重新启动es-node-1容器即可。
知识:
1、es的节点分为管理节点、数据节点,节点可以只做管理元数据或者传输,也可以只做数据存储与读取,也可以两者角色都做。
2、节点与副本是两个概念,比如3个节点可以做3副本,也可以做2副本。但副本不可以超过数据节点数量
3、分片是指把数据切片,分布式的存储在数据节点上,一般默认为5个分片
4、es的节点并不是简单的复制关系,不同的节点上保存的数据是不一样的,存储着不同的副本与切片
5、主节点挂机后,集群会自动选举一个主节点
6、节点数据必须3或者以上,否则无法进行选举















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









