







1、一行代码实现1--100之和
利用sum()函数求和

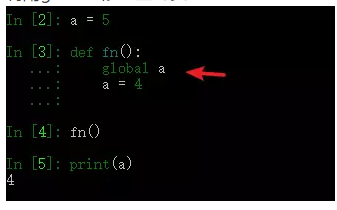
2、如何在一个函数内部修改全局变量
利用global 修改全局变量
4、字典如何删除键和合并两个字典
del和update方法

5、谈下python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
6、python实现列表去重的方法
先通过集合去重,在转列表

7、fun(*args,**kwargs)中的*args,**kwargs什么意思?


8、python2和python3的range(100)的区别
python2返回列表,python3返回迭代器,节约内存
9、一句话解释什么样的语言能够用装饰器?
函数可以作为参数传递的语言,可以使用装饰器
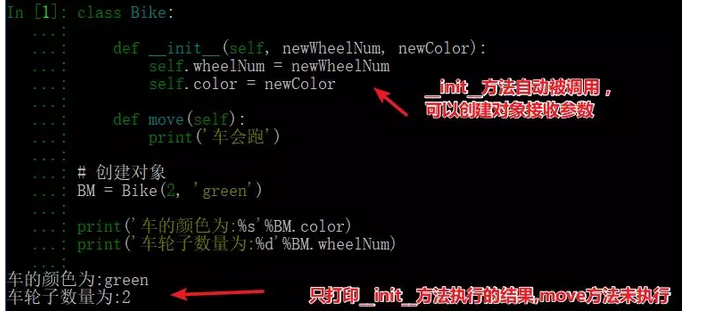
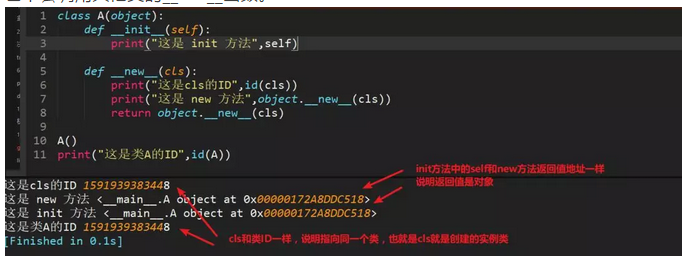
11、简述面向对象中__new__和__init__区别
__init__是初始化方法,创建对象后,就立刻被默认调用了,可接收参数,如图
1、__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
2、__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
3、__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
4、如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
12、简述with方法打开处理文件帮我我们做了什么?
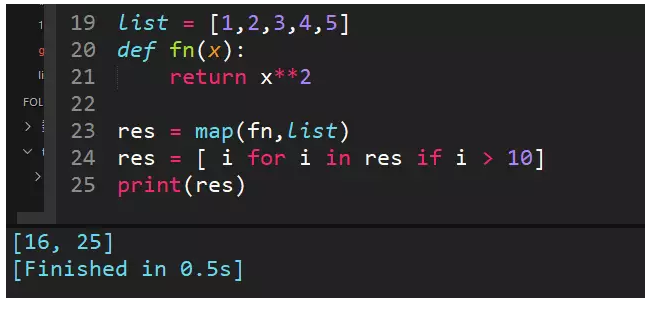
13、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
map()函数第一个参数是fun,第二个参数是一般是list,第三个参数可以写list,也可以不写,根据需求
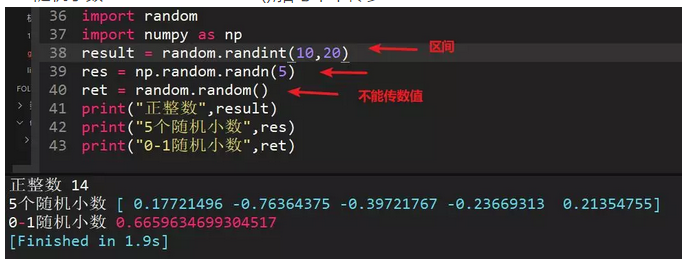
14、python中生成随机整数、随机小数、0--1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
0-1随机小数:random.random(),括号中不传参
15、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
18、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
19、10个Linux常用命令
ls pwd cd touch rm mkdir tree cp mv cat more grep echo
20、python2和python3区别?列举5个
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')
Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比如 print 'hi'
2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存
3、python2中使用ascii编码,python中使用utf-8编码
4、python2中unicode表示字符串序列,str表示字节序列
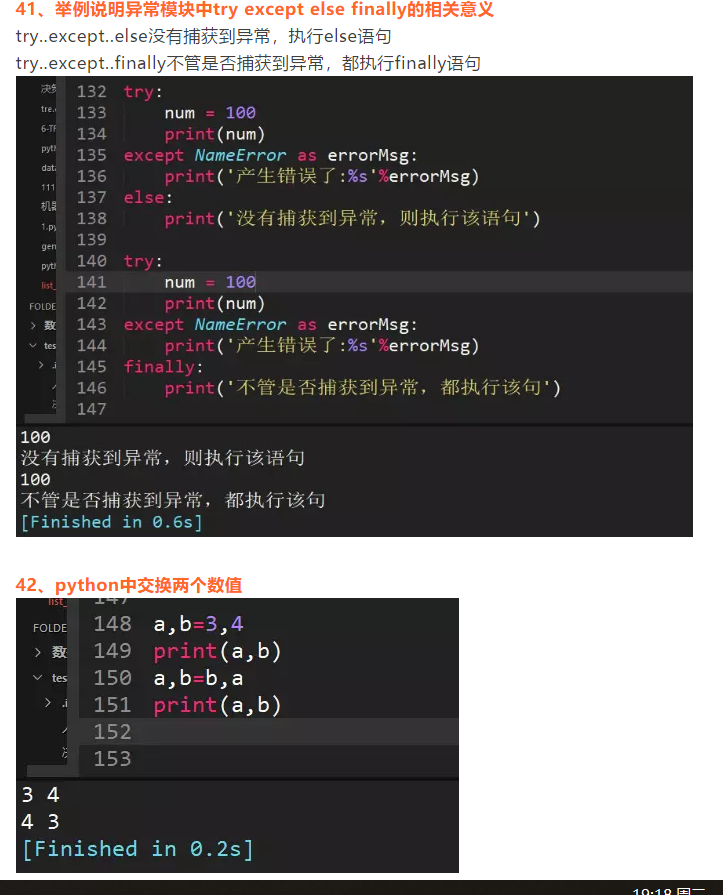
python3中str表示字符串序列,byte表示字节序列
5、python2中为正常显示中文,引入coding声明,python3中不需要
6、python2中是raw_input()函数,python3中是input()函数
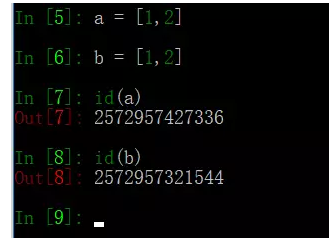
21、列出python中可变数据类型和不可变数据类型,并简述原理
不可变数据类型:数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id

可变数据类型:列表list和字典dict;
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。

32、用python删除文件和用linux命令删除文件方法
python:os.remove(文件名)
linux: rm 文件名

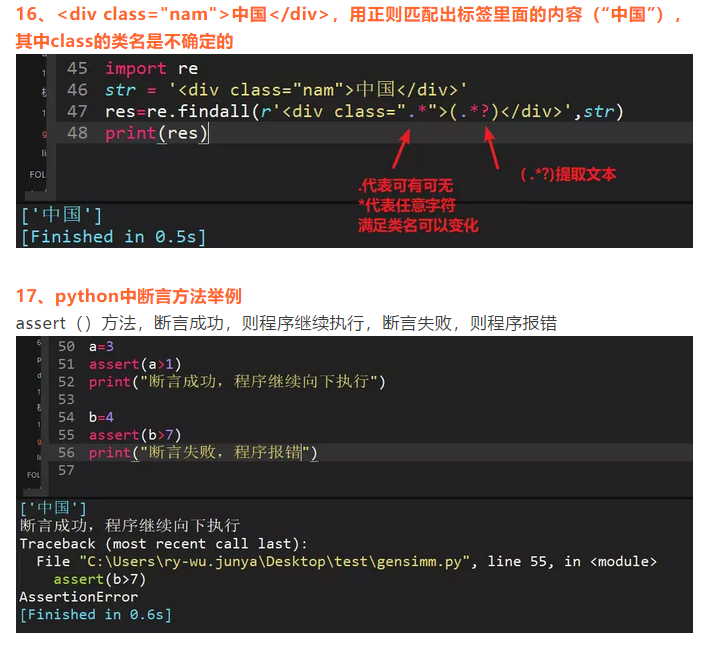
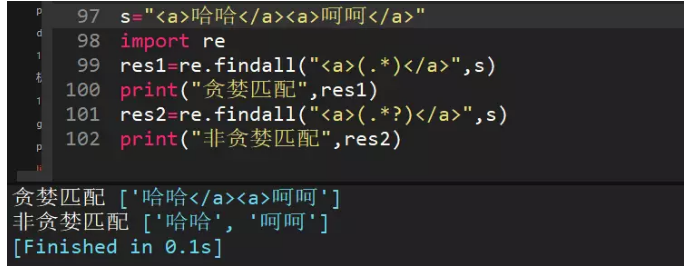
37、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
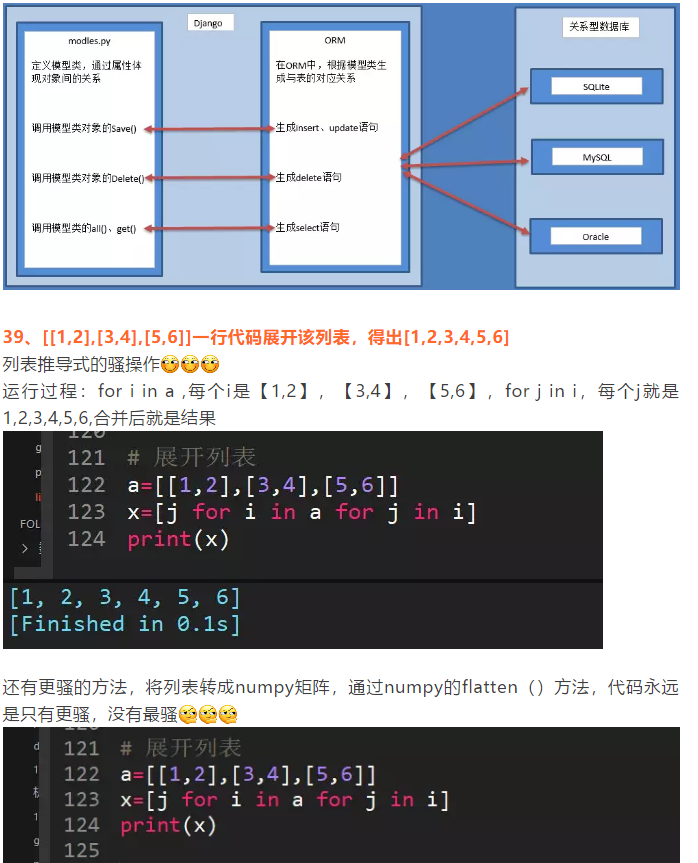
38、简述Django的orm
ORM,全拼Object-Relation Mapping,意为对象-关系映射
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程,orm操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySQL、Oracle、sqlite....,如果数据库迁移,只需要更换Django的数据库引擎即可
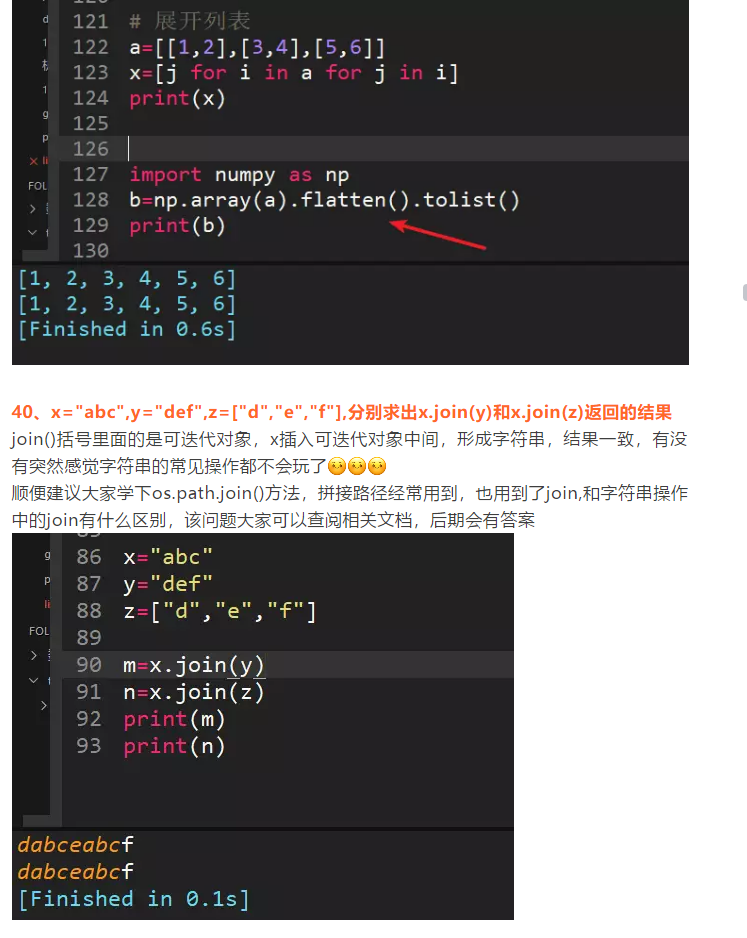
还有更骚的方法,将列表转成numpy矩阵,通过numpy的flatten()方法,代码永远是只有更骚,没有最骚![]()
![]()
![]()
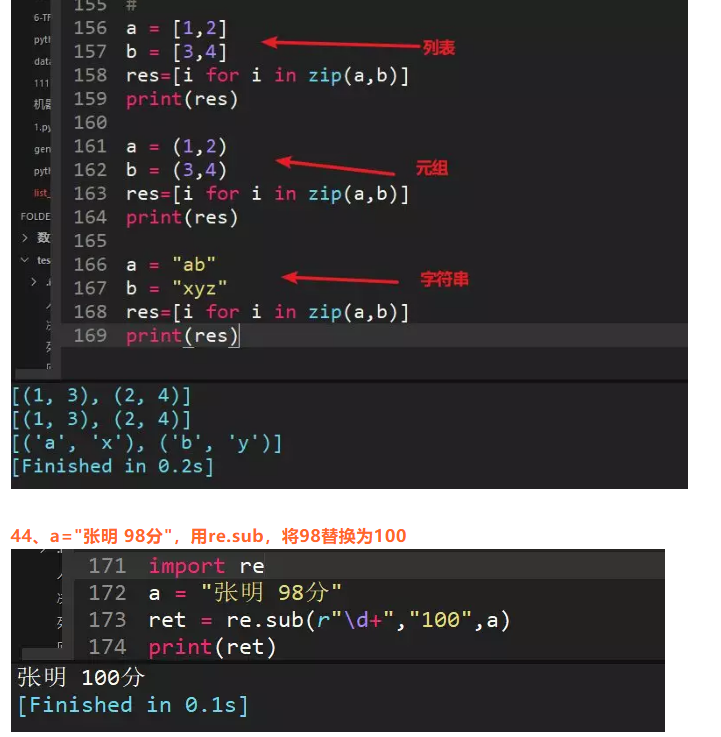
43、举例说明zip()函数用法
zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
45、写5条常用sql语句
show databases;
show tables;
desc 表名;
select * from 表名;
delete from 表名 where id=5;
update students set gender=0,hometown="北京" where id=5
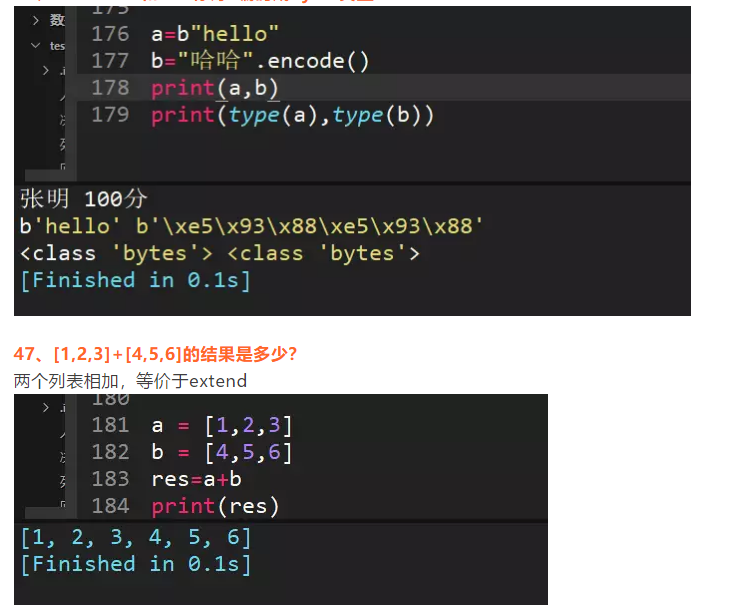
46、a="hello"和b="你好"编码成bytes类型
48、提高python运行效率的方法
1、使用生成器,因为可以节约大量内存
2、循环代码优化,避免过多重复代码的执行
3、核心模块用Cython PyPy等,提高效率
4、多进程、多线程、协程
5、多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
49、简述mysql和redis区别
redis: 内存型非关系数据库,数据保存在内存中,速度快
mysql:关系型数据库,数据保存在磁盘中,检索的话,会有一定的Io操作,访问速度相对慢
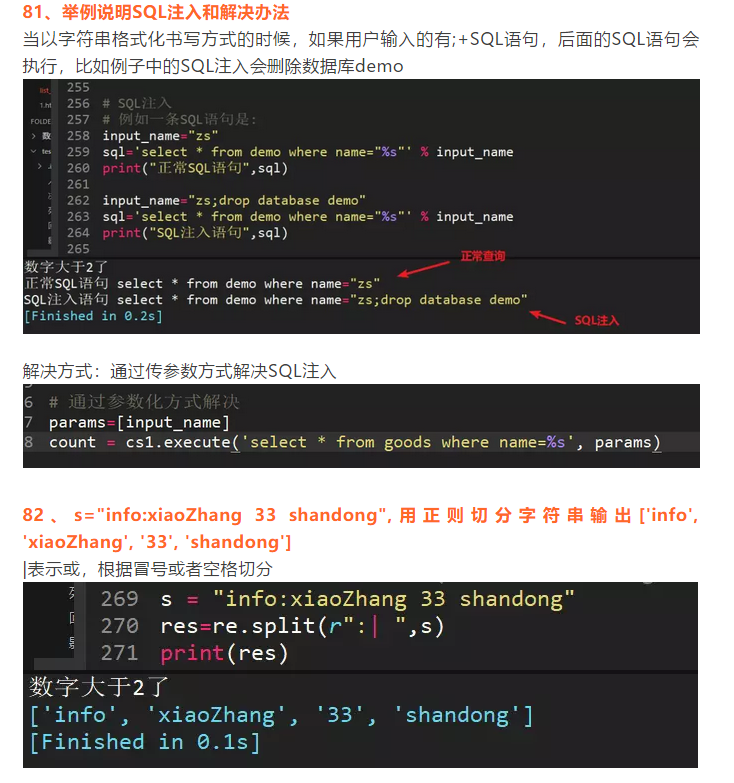
50、遇到bug如何处理
1、细节上的错误,通过print()打印,能执行到print()说明一般上面的代码没有问题,分段检测程序是否有问题,如果是js的话可以alert或console.log
2、如果涉及一些第三方框架,会去查官方文档或者一些技术博客。
3、对于bug的管理与归类总结,一般测试将测试出的bug用teambin等bug管理工具进行记录,然后我们会一条一条进行修改,修改的过程也是理解业务逻辑和提高自己编程逻辑缜密性的方法,我也都会收藏做一些笔记记录。
4、导包问题、城市定位多音字造成的显示错误问题
51、正则匹配,匹配日期2018-03-20
url='https://sycm.taobao.com/bda/tradinganaly/overview/get_summary.json?dateRange=2018-03-20%7C2018-03-20&dateType=recent1&device=1&token=ff25b109b&_=1521595613462'
仍有同学问正则,其实匹配并不难,提取一段特征语句,用(.*?)匹配即可
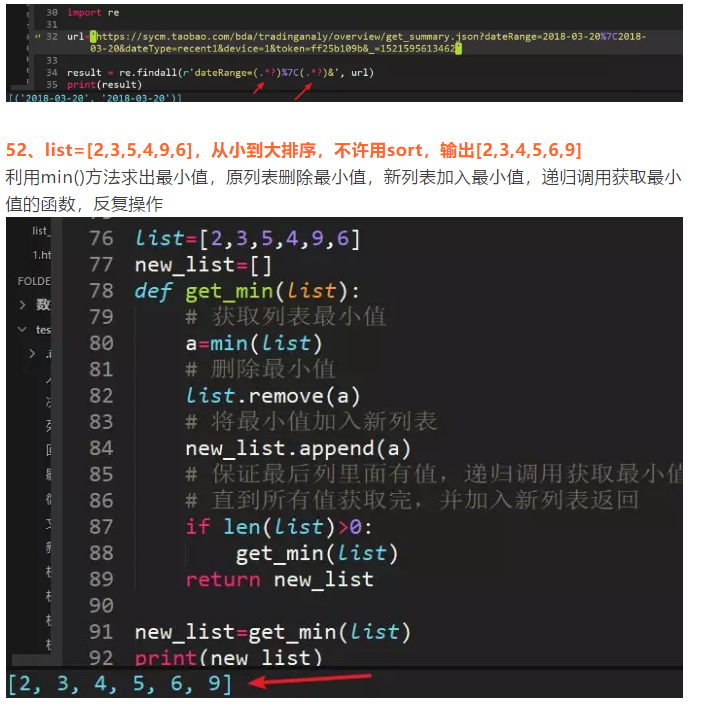
53、写一个单列模式
因为创建对象时__new__方法执行,并且必须return 返回实例化出来的对象所cls.__instance是否存在,不存在的话就创建对象,存在的话就返回该对象,来保证只有一个实例对象存在(单列),打印ID,值一样,说明对象同一个
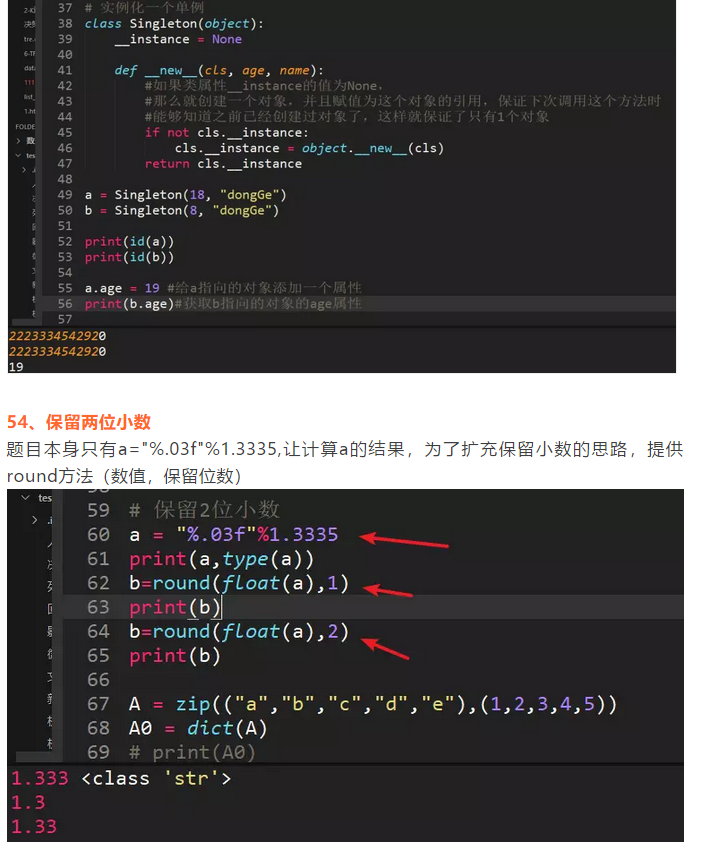
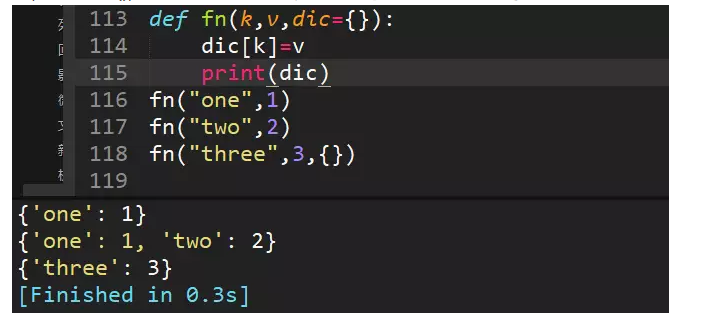
55、求三个方法打印结果
fn("one",1)直接将键值对传给字典;
fn("two",2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对
fn("three",3,{})因为传了一个新字典,所以不再是原先默认参数的字典
56、列出常见的状态码和意义
200 OK
请求正常处理完毕
204 No Content
请求成功处理,没有实体的主体返回
206 Partial Content
GET范围请求已成功处理
301 Moved Permanently
永久重定向,资源已永久分配新URI
302 Found
临时重定向,资源已临时分配新URI
303 See Other
临时重定向,期望使用GET定向获取
304 Not Modified
发送的附带条件请求未满足
307 Temporary Redirect
临时重定向,POST不会变成GET
400 Bad Request
请求报文语法错误或参数错误
401 Unauthorized
需要通过HTTP认证,或认证失败
403 Forbidden
请求资源被拒绝
404 Not Found
无法找到请求资源(服务器无理由拒绝)
500 Internal Server Error
服务器故障或Web应用故障
503 Service Unavailable
服务器超负载或停机维护
57、分别从前端、后端、数据库阐述web项目的性能优化
该题目网上有很多方法,我不想截图网上的长串文字,看的头疼,按我自己的理解说几点
前端优化:
1、减少http请求、例如制作精灵图
2、html和CSS放在页面上部,javascript放在页面下面,因为js加载比HTML和Css加载慢,所以要优先加载html和css,以防页面显示不全,性能差,也影响用户体验差
后端优化:
1、缓存存储读写次数高,变化少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
2、异步方式,如果有耗时操作,可以采用异步,比如celery
3、代码优化,避免循环和判断次数太多,如果多个if else判断,优先判断最有可能先发生的情况
数据库优化:
1、如有条件,数据可以存放于redis,读取速度快
2、建立索引、外键等
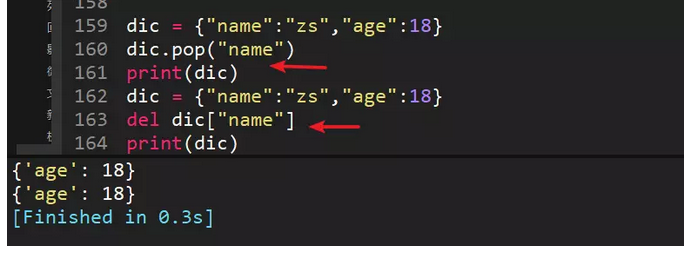
58、使用pop和del删除字典中的"name"字段,dic={"name":"zs","age":18}
59、列出常见MYSQL数据存储引擎
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。
MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。

61、简述同源策略
同源策略需要同时满足以下三点要求:
1)协议相同
2)域名相同
3)端口相同
http:www.test.com与https:www.test.com 不同源——协议不同
http:www.test.com与http:www.admin.com 不同源——域名不同
http:www.test.com与http:www.test.com:8081 不同源——端口不同
只要不满足其中任意一个要求,就不符合同源策略,就会出现“跨域”
62、简述cookie和session的区别
1,session 在服务器端,cookie 在客户端(浏览器)
2、session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效,存储Session时,键与Cookie中的sessionid相同,值是开发人员设置的键值对信息,进行了base64编码,过期时间由开发人员设置
3、cookie安全性比session差
63、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
64、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
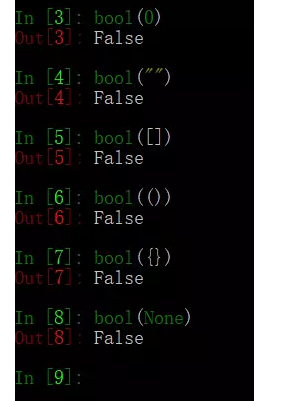
测试all()和any()方法

65、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
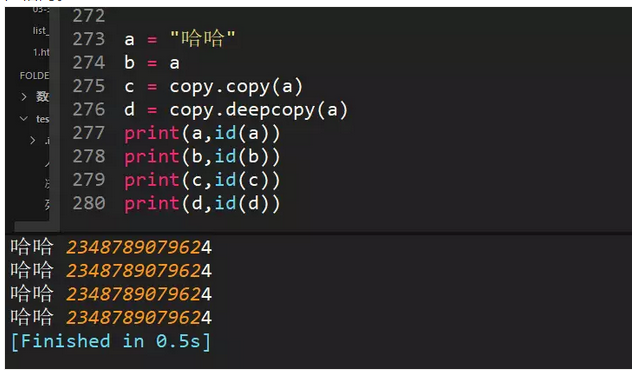
66、python中copy和deepcopy区别
1、复制不可变数据类型,不管copy还是deepcopy,都是同一个地址当浅复制的值是不可变对象(数值,字符串,元组)时和=“赋值”的情况一样,对象的id值与浅复制原来的值相同。
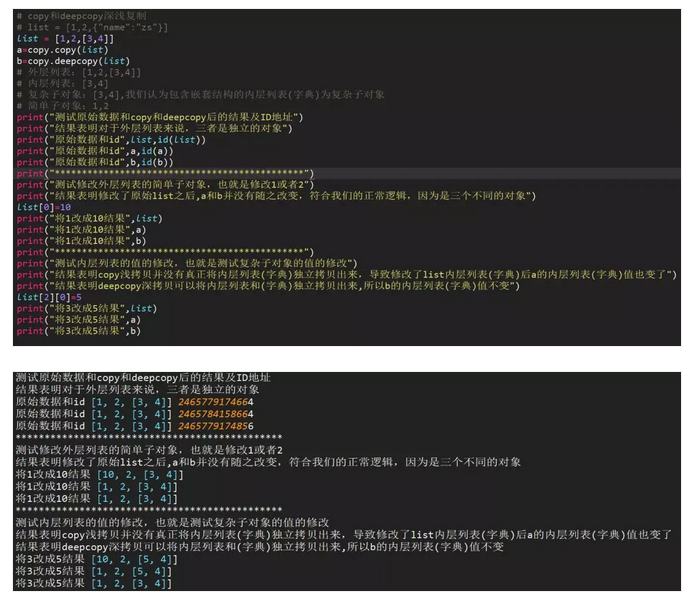
2、复制的值是可变对象(列表和字典)
浅拷贝copy有两种情况:
第一种情况:复制的 对象中无 复杂 子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有 复杂 子对象 (例如列表中的一个子元素是一个列表), 改变原来的值 中的复杂子对象的值 ,会影响浅复制的值。
深拷贝deepcopy:完全复制独立,包括内层列表和字典
67、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
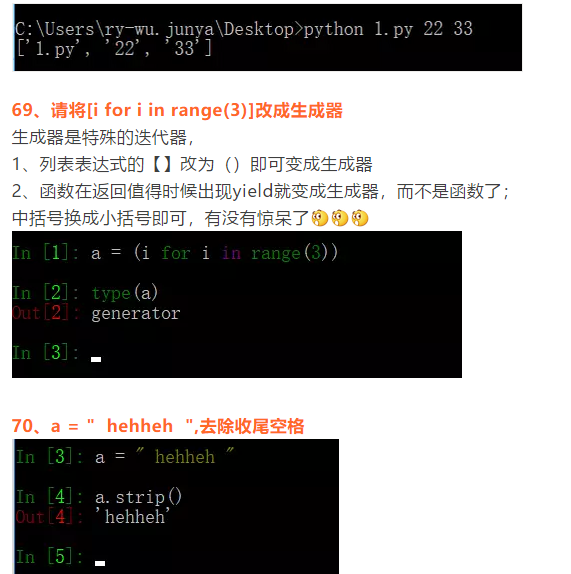
68、C:\Users\ry-wu.junya\Desktop>python 1.py 22 33命令行启动程序并传参,print(sys.argv)会输出什么数据?
文件名和参数构成的列表





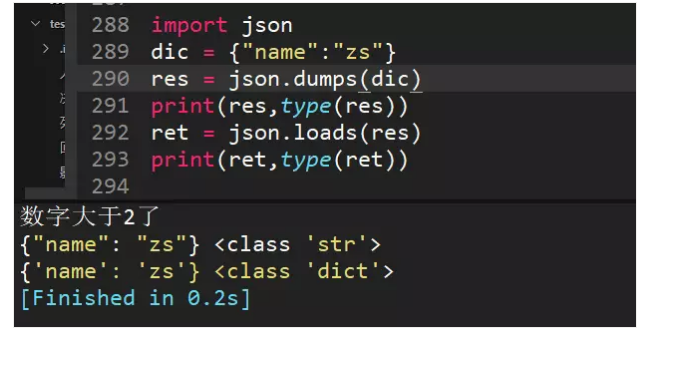
85、python字典和json字符串相互转化方法
json.dumps()字典转json字符串,json.loads()json转字典
86、MyISAM 与 InnoDB 区别:
1、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高
级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM
就不可以了;
2、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到
安全性较高的应用;
3、InnoDB 支持外键,MyISAM 不支持;
4、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM
表中可以和其他字段一起建立联合索引;
5、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重
建表;
87、统计字符串中某字符出现次数
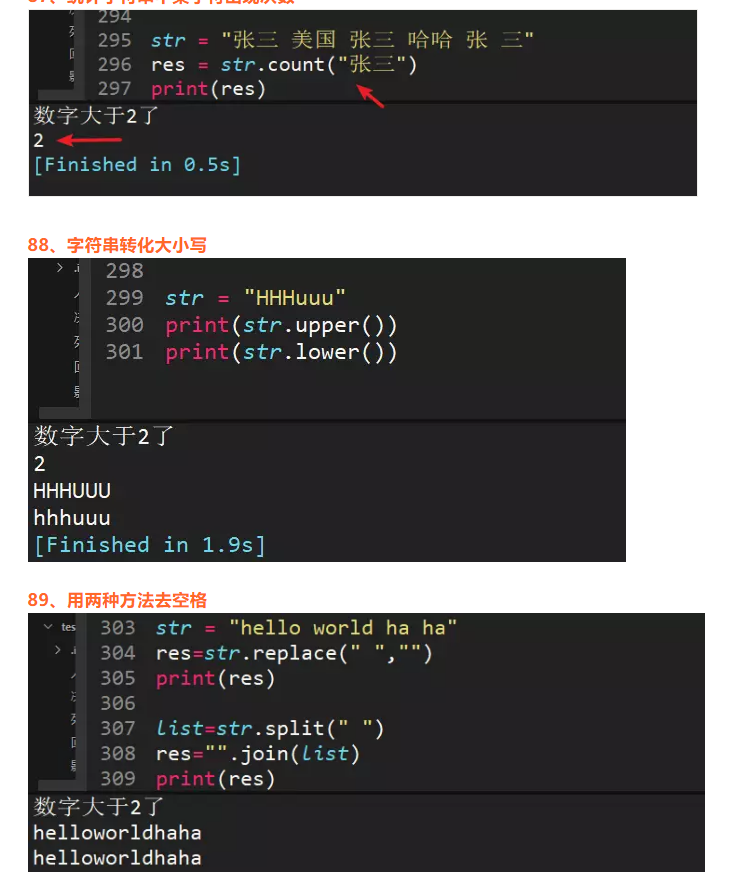
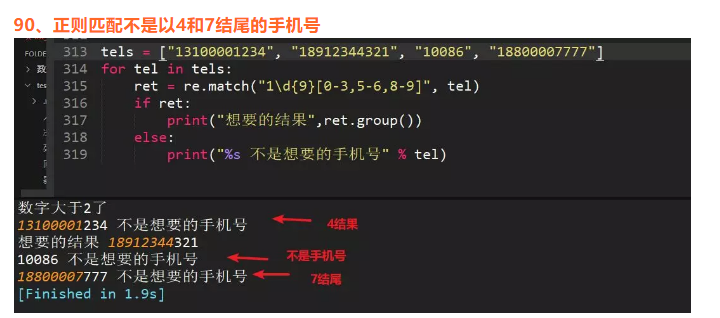
92、int("1.4"),int(1.4)输出结果?
int("1.4")报错,int(1.4)输出1
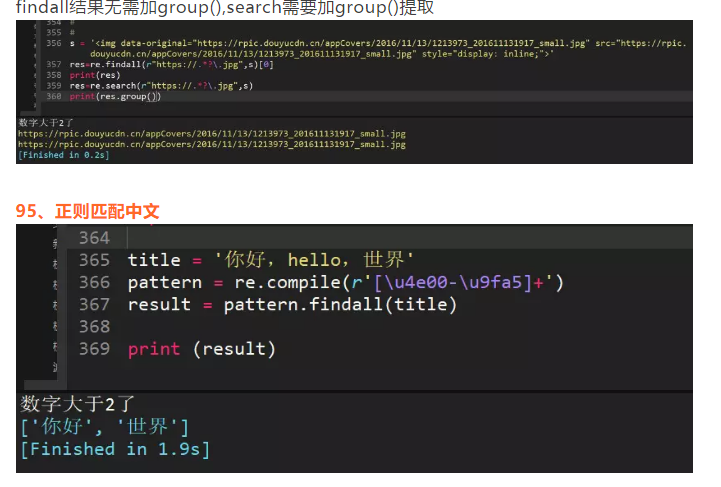
94、正则表达式匹配第一个URL
96、简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量
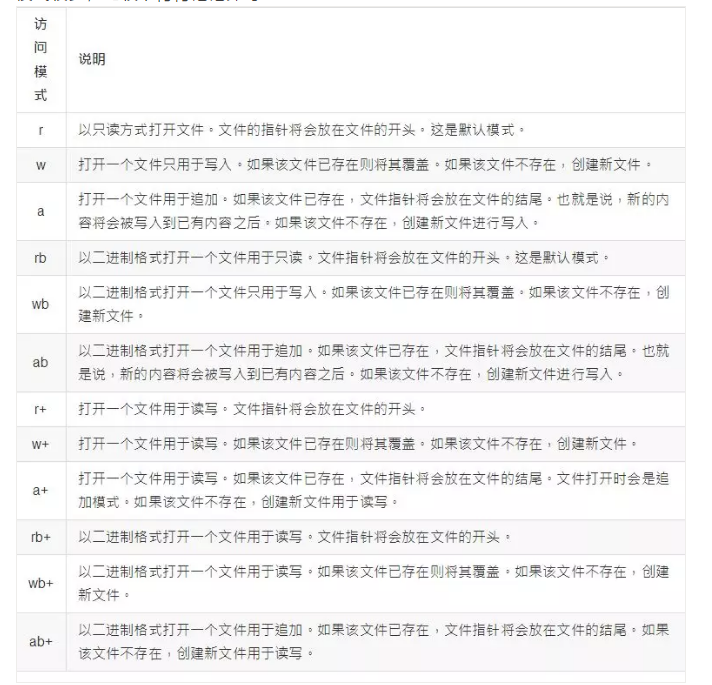
97、r、r+、rb、rb+文件打开模式区别
模式较多,比较下背背记记即可
98、Linux命令重定向 > 和 >>
Linux 允许将命令执行结果 重定向到一个 文件
将本应显示在终端上的内容 输出/追加 到指定文件中
> 表示输出,会覆盖文件原有的内容
>> 表示追加,会将内容追加到已有文件的末尾
用法示例:
将 echo 输出的信息保存到 1.txt 里echo Hello Python > 1.txt
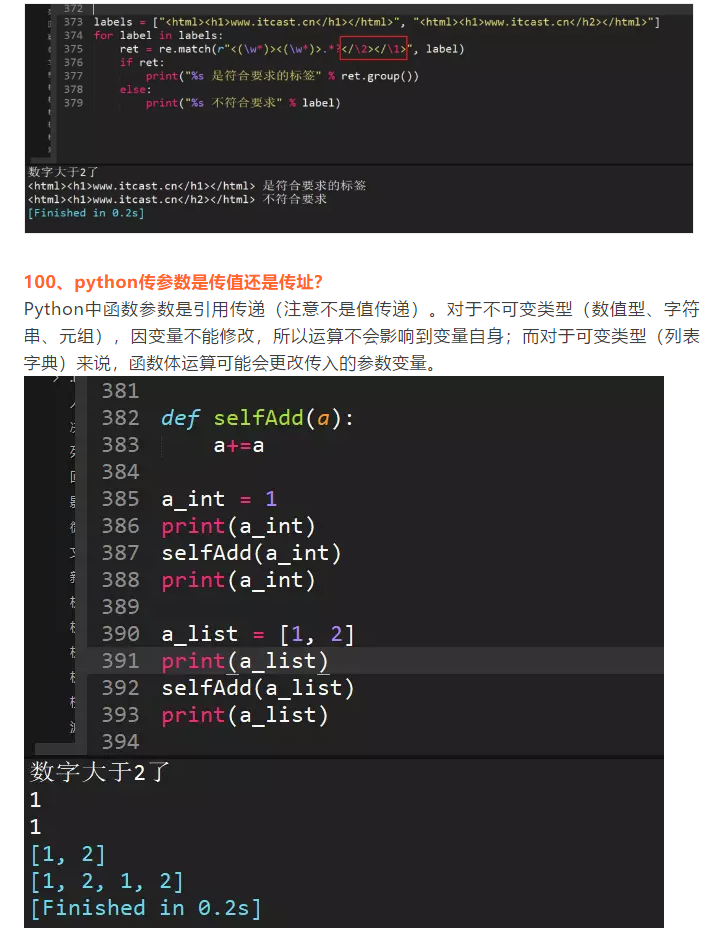
将 tree 输出的信息追加到 1.txt 文件的末尾tree >> 1.txt99、正则表达式匹配出<html><h1>www.itcast.cn</h1></html>
前面的<>和后面的<>是对应的,可以用此方法
109、简述多线程、多进程
进程:
1、操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
2、稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程:
1、CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
2、如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
应用:
IO密集的用多线程,在用户输入,sleep 时候,可以切换到其他线程执行,减少等待的时间
CPU密集的用多进程,因为假如IO操作少,用多线程的话,因为线程共享一个全局解释器锁,当前运行的线程会霸占GIL,其他线程没有GIL,就不能充分利用多核CPU的优势
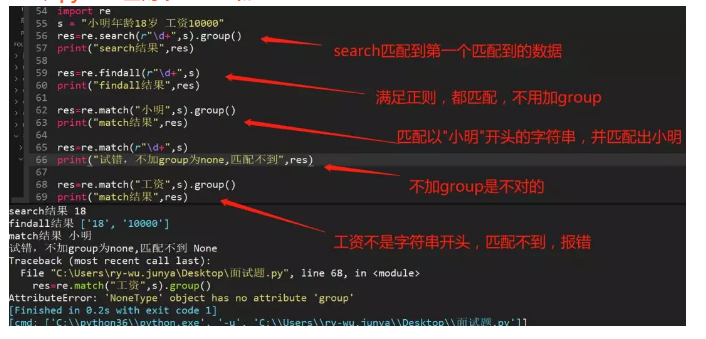
110、python正则中search和match














 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









