






摘要:正在学习TensorFlow,利用效率不够高?不懂TensorFlow里面的奥秘?看大神如何一步步教你如何高效使用TensorFlow!
Tensorflow基础知识:
Tensorflow和其他数字计算库(如numpy)之间最明显的区别在于Tensorflow中操作的是符号。这是一个强大的功能,这保证了Tensorflow可以做很多其他库(例如numpy)不能完成的事情(例如自动区分)。这可能也是它更复杂的原因。今天我们来一步步探秘Tensorflow,并为更有效地使用Tensorflow提供了一些指导方针和最佳实践。
我们从一个简单的例子开始,我们要乘以两个随机矩阵。首先我们来看一下在numpy中如何实现:

现在我们使用Tensorflow中执行完全相同的计算:

与立即执行计算并将结果复制给输出变量z的numpy不同,tensorflow只给我们一个可以操作的张量类型。如果我们尝试直接打印z的值,我们得到这样的东西:

由于两个输入都是已经定义的类型,tensorFlow能够推断张量的符号及其类型。为了计算张量的值,我们需要创建一个会话并使用Session.run方法进行评估。
要了解如此强大的符号计算到底是什么,我们可以看看另一个例子。假设我们有一个曲线的样本(例如f(x)= 5x ^ 2 + 3),并且我们要估计f(x)在不知道它的参数的前提下。我们定义参数函数为g(x,w)= w0 x ^ 2 + w1 x + w2,它是输入x和潜在参数w的函数,我们的目标是找到潜在参数,使得g(x, w)≈f(x)。这可以通过最小化损失函数来完成:L(w)=(f(x)-g(x,w))^ 2。虽然这问题有一个简单的封闭式的解决方案,但是我们选择使用一种更为通用的方法,可以应用于任何可以区分的任务,那就是使用随机梯度下降。我们在一组采样点上简单地计算相对于w的L(w)的平均梯度,并沿相反方向移动。
以下是在Tensorflow中如何完成:
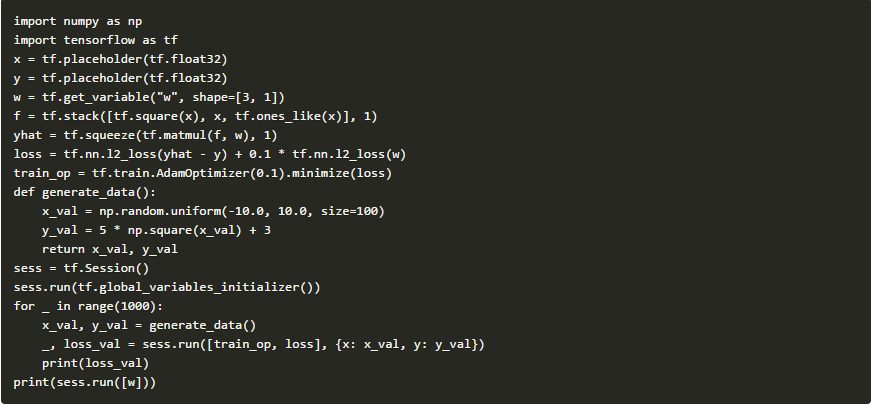
通过运行这段代码,我们可以看到下面这组数据:
[4.9924135, 0.00040895029, 3.4504161]
这与我们的参数已经相当接近。
这只是Tensorflow可以做的冰山一角。许多问题,如优化具有数百万个参数的大型神经网络,都可以在Tensorflow中使用短短的几行代码高效地实现。而且Tensorflow可以跨多个设备和线程进行扩展,并支持各种平台。
理解静态形状和动态形状的区别:
Tensorflow中的张量在图形构造期间具有静态的形状属性。例如,我们可以定义一个形状的张 量[None,128]:

这意味着第一个维度可以是任意大小的,并且将在Session.run期间随机确定。Tensorflow有一个非常简单的API来展示静态形状:

为了获得张量的动态形状,你可以调用tf.shape op,它将返回一个表示给定形状的张量:

我们可以使用Tensor.set_shape()方法设置张量的静态形状:

实际上使用tf.reshape()操作更为安全:

这里有一个函数可以方便地返回静态形状,当静态可用而动态不可用的时候。

现在想象一下,如果我们要将三维的张量转换成二维的张量。在TensorFlow中我们可以使用get_shape()函数:

请注意,无论是否静态指定形状,都可以这样做。
实际上,我们可以写一个通用的重塑功能来如何维度之间的转换:
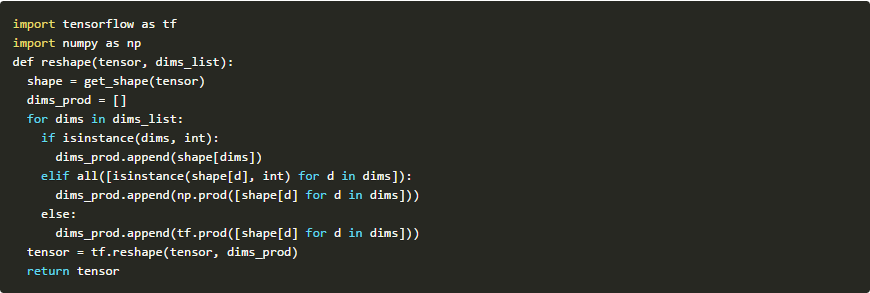
然后转化为二维就变得非常容易了:

广播机制(broadcasting)的好与坏:
Tensorflow同样支持广播机制。当要执行加法和乘法运算时,你需要确保操作数的形状匹配,例如,你不能将形状[3,2]的张量添加到形状的张量[3,4]。但有一个特殊情况,那就是当你有一个单一的维度。Tensorflow隐含地功能可以将张量自动匹配另一个操作数的形状。例如:

广播允许我们执行隐藏的功能,这使代码更简单,并且提高了内存的使用效率,因为我们不需要再使用其他的操作。为了连接不同长度的特征,我们通常平铺式的输入张量。这是各种神经网络架构的最常见模式:

这可以通过广播机制更有效地完成。我们使用f(m(x + y))等于f(mx + my)的事实。所以我们可以分别进行线性运算,并使用广播进行隐式级联:
pa = tf.layers.dense(a, 10, activation=None)

实际上,这段代码很普遍,只要在张量之间进行广播就可以应用于任意形状的张量:

到目前为止,我们讨论了广播的好的部分。但是你可能会问什么坏的部分?隐含的假设总是使调试更加困难,请考虑以下示例:

你认为C的数值是多少如果你猜到6,那是错的。这是因为当两个张量的等级不匹配时,Tensorflow会在元素操作之前自动扩展具有较低等级的张量,因此加法的结果将是[[2,3],[3,4]]。
如果我们指定了我们想要减少的维度,避免这个错误就变得很容易了:

这里c的值将是[5,7]。
使用Python实现原型内核和高级可视化的操作:
为了提高效率,Tensorflow中的操作内核完全是用C ++编写,但是在C ++中编写Tensorflow内核可能会相当痛苦。。使用tf.py_func(),你可以将任何python代码转换为Tensorflow操作。
例如,这是python如何在Tensorflow中实现一个简单的ReLU非线性内核:
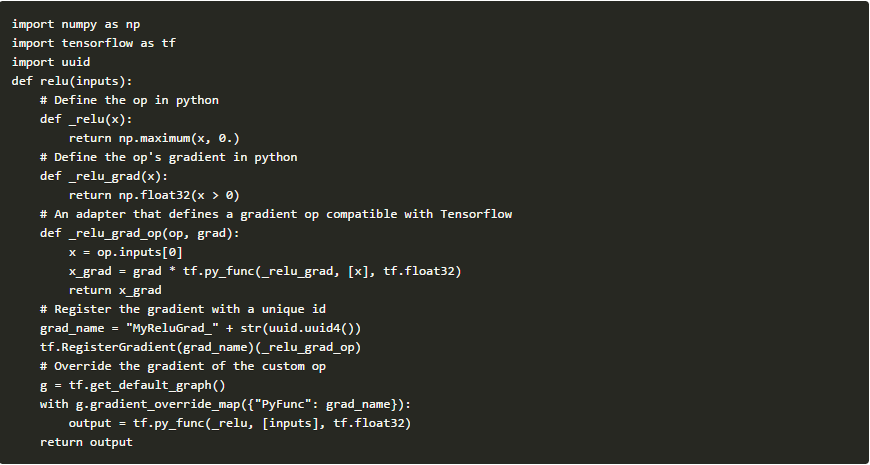
要验证梯度是否正确,你可以使用Tensorflow的梯度检查器:

compute_gradient_error()是以数字的方式计算梯度,并返回与渐变的差异,因为我们想要的是一个很小的差异。
请注意,此实现效率非常低,只对原型设计有用,因为python代码不可并行化,不能在GPU上运行。
在实践中,我们通常使用python ops在Tensorboard上进行可视化。试想一下你正在构建图像分类模型,并希望在训练期间可视化你的模型预测。Tensorflow允许使用函数tf.summary.image()进行可视化:

但这只能显示输入图像,为了可视化预测,你必须找到一种方法来添加对图像的注释,这对于现有操作几乎是不可能的。一个更简单的方法是在python中进行绘图,并将其包装在一个python方法中:
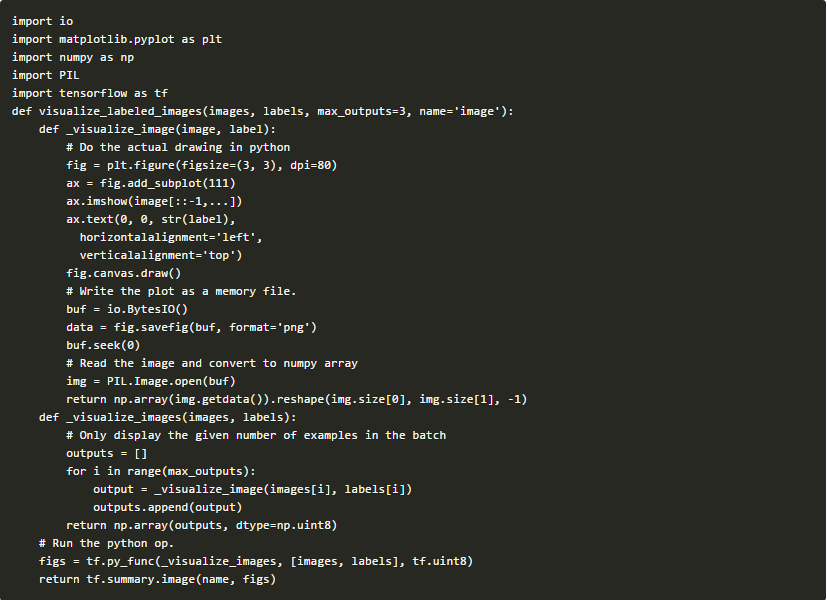
请注意,由于概要通常只能在一段时间内进行评估(不是每步),因此实施中可以使用该实现,而不用担心效率。
本文由北邮@爱可可-爱生活老师推荐,@阿里云云栖社区组织翻译。
文章原标题《Effective Tensorflow - Guides and best practices for effective use of Tensorflow》
作者:Vahid Kazemi 作者是google的件工程师,CS中的博士学位。从事机器学习,NLP和计算机视觉工作。
译者:袁虎















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









