






Flask 框架学习目录
1. 概述
Flask框架没有像Django一样,预置ORM包。因此,我们可以有多种选择。
差不多每一种数据库产品都有其Python访问包,比如对于sqlite数据库, 可以使用内置的sqlite3包;对于MySQL数据库,可以使用MySQL-python包; 对于MongoDB,可以使用pymongo包...
这种方式是最灵活的,可以支持几乎全部类型的数据库,无论SQL还是NOSQL, 而且可以进行最大限度的性能挖掘。
不过在本课程内,我们将选择性地忽略这种数据库访问方式,而是将关注点放 在一般性框架中常见的ORM产品上 —— 在Flask中,我们使用SQLAlchemy。
在本节课程内,对Flask框架中应用ORM的讲解主要从以下几个方面着眼:
-
ORM的思想与来源
-
应用ORM的一般步骤
-
如何配置ORM的数据库连接?
-
如何在ORM中定义对象模型?
-
如何在ORM中创建或删除数据表?
-
如何在ORM中持久化对象?
-
如何在ORM中载入对象?
-
如何在ORM中修改对象属性?
-
如何在ORM中删除对象?
2. ORM :对象-关系映射
ORM的全称是Object Relational Mapping,即对象-关系映射,是面向对象/OO 理念向数据持久化方向的自然延伸,是OO和SQL两股思潮在最高点的自然媾和。
还得站在OO拥护者的角度看ORM的诞生。当一切应用都以OO的思想被分解为一个 一个对象以后,设计者突然发现,这些对象只能存活在内存中,插头一拔,什么 都没了。
要硬盘!要永生!
上世纪90年代OO高潮的时候,恰巧关于数据存储的关系理论也大行其道,硬盘 是关系理论三范式的天下。各种关系数据库产品,做的相当好的一点是其操作 语言基本统一到SQL标准上了,
OO界在搞自己的OO数据库未果后,决定联姻关系数据库,实现对象永生的目标。 ORM粉墨登场。
ORM的一般性思路
ORM的目的是持久化对象,比如你定义一个User类,创建了一堆User对象:
class User:
def __init__(self,id,name,age):
self.id = id
self.name = name
self.age = age
user1 = User(1,'Zhang3',20)
user2 = User(2,'Li4',30)
user3 = User(3,'Wang5',40)
`ORM希望你能这样把上面三个对象持久化到硬盘里:
user1.save()
user2.save()
user3.save()然后,第二天上班开机,重新启动程序,可以再把这三个对象找回来:
user1 = User.load(id=1)
user2 = User.load(id=2)
user3 = User.load(id=3)一旦对象找回来,重新进入内存,就是OO的地盘了,无论加加减减都能应付。
3. 配置数据库信息
Flask没有自己的ORM实现,我们可以使用开源包SQLAlchemy。当然可以 直接应用SQLAlchemy包,不过Flask-SQLAlchemy已经将SQLAlchemy集成进了 Flask体系,简化了不少工作。因此,我们将基于Flask-SQLAlchemy开始 Flask框架的ORM之旅。
在进行一切持久化相关的工作之前,需要首先在应用中配置数据库的信息,比如:
-
使用的数据库是MySQL还是PostgreSQL
-
数据库的具体连接信息:IP地址、端口、账号、口令...
Flask-SQLAlchemy使用数据库访问URL来统一的表示这些配置信息,比如一些常见 的数据库的访问URL举例如下:
-
MySQL - mysql://username:password@hostname/database
-
Postgre - postgresql://username:password@hostname/database
-
SQLite - sqlite:absolute/path/to/database
在下面的示例中,我们告诉SQLAlchemy使用应用目录下的sqlite数据库文件data.sqlite作为对象持久化的引擎,然后创建SQLAlchemy对象:
app = Flask(__name__)
basedir = os.path.abspath(os.path.dirname(__file__))
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir,'data.sqlite')
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
db = SQLAlchemy(app)Flask-SQLAlchemy在Flask应用中,定义了两个配置项进行ORM的数据库设置:
-
SQLALCHEMY_DATABASE_URI - 声明ORM底层所用数据库的访问URL
-
SQLALCHEMY_COMMIT_ON_TEARDOWN - 当关闭数据库连接时是否自动提交事务
4. 定义对象模型
别忘了ORM是搞OO的人发起的,所以,和通常的数据库应用开发从E-R数据模型开始 不同,使用ORM是从定义对象模型开始的。
在下面的示例中,我们定义一个类User。请注意User类是从db.Model继承来的:
class User(db.Model):
__tablename__ = 'ezuser'
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(64),unique=True,index=True)
age = db.Column(db.Integer)上面的示例中,你应该注意到了,成员变量被定义为db.Column类的实例:
-
id - id被定义为整型、主键
-
name - name被定义为字符串类型、建立唯一索引
-
age - age简单的被定义为整型
User类的成员变量tablename定义了这个对象对应的数据表名。这个变量是 可选的,默认情况下,SQLAlchemy将使用类名作为表名。
SQLAlchemy支持的常见的字段数据类型如下:
-
db.Integer - 32位整型,对应于Python的int
-
db.Float - 浮点型,对应于Python的float
-
db.String - 变长字符串,对应于Python的str
-
db.DateTime - 日期时间型,对应于Python的datetime.datetime
看到这里,可能你大约明白了。通过这样的定义方法,SQLAlchemy已经搜集到 足够的信息进行数据库操作了:表名、字段名、字段类型、字段约束(主键信息、 索引信息...)
5. 维护数据表
当对象模型定义完成、数据库信息配置完毕后,就可以在数据库中创建对象 对应的数据表了。
理论上,ORM能够根据采集到的类型信息自动地创建数据表。但出于稳妥考虑, 这个工作通常还是手动地触发。很简单,只要执行SQLAlchemy对象的一个方法 create_all():
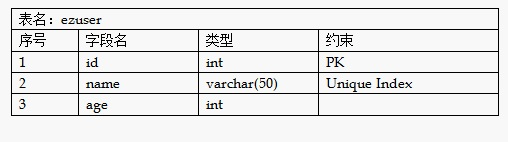
db.create_all()现在,数据库里已经妥妥地存在了一张数据表,它的结构如下:
删除表
如果你修改了对象模型定义,那么需要删除已经存在的表,然后重新创建。和创建数据表类似,删除表也只需要执行SQLAlchemy对象的一个方法drop_all():
db.drop_all()6. 对象持久化
持久化就是将Python对象存入数据库中,在ORM中,这通常包括两个步骤:
第一、在数据库会话上执行添加操作
一个会话对象代表一个数据库的事务。可以在会话对象上添加一个对象:
db.session.add(obj)也可以调用all_all()方法一次添加多个对象:
db.session.add_all([obj1,obj2,obj3])第二、提交数据库会话
当在会话上执行完所有操作后,调用commit()方法提交本次事务:
db.session.commit()如果其中任何一个操作失败,整个事务将全部失败。
现在停电也不怕了。
一点额外的思考
现在考虑一下,为什么不使用更直观的调用方式来执行持久化操作?比如:
user.save()这和上面提到的事务/Tranasction有关。考虑一个经典的银行转账场景, 你从一个账户转出100块,同时向另一个账户转入100块,写成代码大约是:
account1.balance = account1.balance - 100
account2.balance = account2.balance + 100
account1.save()
account2.save()通常这些代码不会出错。不过,万一执行完第3行代码之后,系统突然崩溃了, 会怎么样?
这100块永远的消失了 —— 它离开了账户1,却没来得及进入账户2.
关系数据库中的事务/Transaction就是来解决这个问题的,如果你将几个 对数据库的操作放到一个事务里执行,关系数据库确保这几个操作要么同时成功、 要么同时失败。这类似于:
__begin_transaction__
account1.save()
account2.save()
__commit_transaction__ORM使用会话session封装了事务的处理,所以,执行add()方法相当于把 修改数据库的操作加入了一个事务,commit()相当于提交了这个包含多个操作 的事务。
7. 载入对象
如果你需要操作所有的对象,比如,在内存中进行统计。那么应当一次性从持久化机构 中载入全部对象。
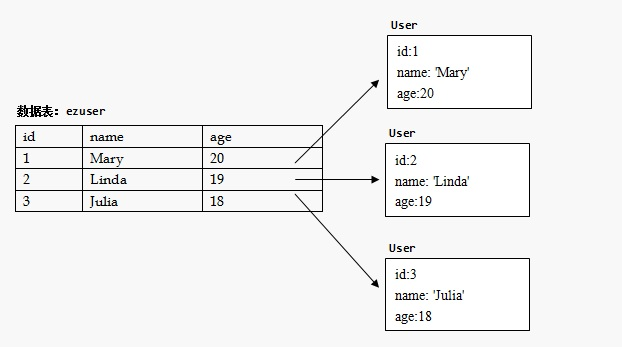
使用之前建立的对象模型类(继承自SQLAlchemy.model)的静态变量query,执行其all() 方法将提取数据库中的全部记录并转化为对象模型类的实例列表:
users = User.query.all()现在users变量是一个包含所有User对象的列表了:
载入特定对象
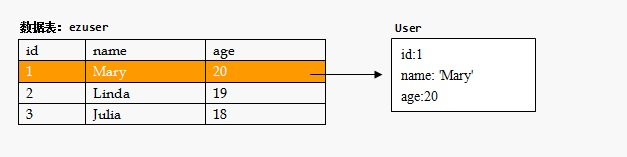
要载入某一个特定对象,需要指定一个唯一标识用户的信息。User对象的id字段 是唯一的,我们可以使用它从持久化机构中载入特定的对象:
user = User.query.filter_by(id = 1).first()filter_by()方法相当于在数据表ezuser中进行了一次行级过滤,根据过滤 条件的不同,它可能返回多个对象,因此,我们使用first()方法定位到第一个对象:
8. 永久移除对象
永久移除对象,意味着从数据库中删除对应的记录。
和持久化类似,移除一个对象会改变数据库,因此我们需要在数据库会话上进行 删除操作,然后提交数据库会话:
db.session.delete(user)
db.session.commit()在ORM内部,移除指定的对象实际包括两个步骤:
-
根据对象主键在数据表中定位记录
-
从数据表中删除定位的数据记录
9. 对象变化持久化
如果我们改变了对象的一些属性,还需要把这些变化同步到持久化机构中。
对于熟悉SQL的人来讲,ORM的处理可能稍有意外:还是在数据库会话上执行添加 操作。
下面的示例修改user对象的年龄,然后重新持久化:
user.age=21
db.session.add(user)
db.session.commit()很显然,ORM层根据应用提交的对象主键做了一个判断:
-
当数据库中没有该主键的对象时,ORM构造一个INSERT语句;
-
当数据库中存在该主键的对象时,ORM构造一个UPDATE语句。
Reference:















 3704
3704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









