






这篇教程是翻译MANU JEEVAN PRAKASH写的 Pandas 教程,作者已经授权翻译,这是原文
在Python中,Pandas 是一个很好地数据处理工具。在这篇文章中,我们将讨论最常用的一些方法,我们使用有关橄榄油的数据集,你可以从这个页面下载到实验数据。当你读完这篇文章后,我希望可能帮助你很快的进行数据处理。那我们开始学习吧。
1. 导入数据
这个橄榄油数据集由八个特征值(油中的脂肪酸水平)和九个类别(意大利地区)组成。如下是八个特征值:
palmitic 棕榈酸
palmitoleic 棕榈油酸
stearic 硬脂酸
oleic 油酸
linoleic 亚油酸
linolenic 亚麻酸
arachidic 花生酸
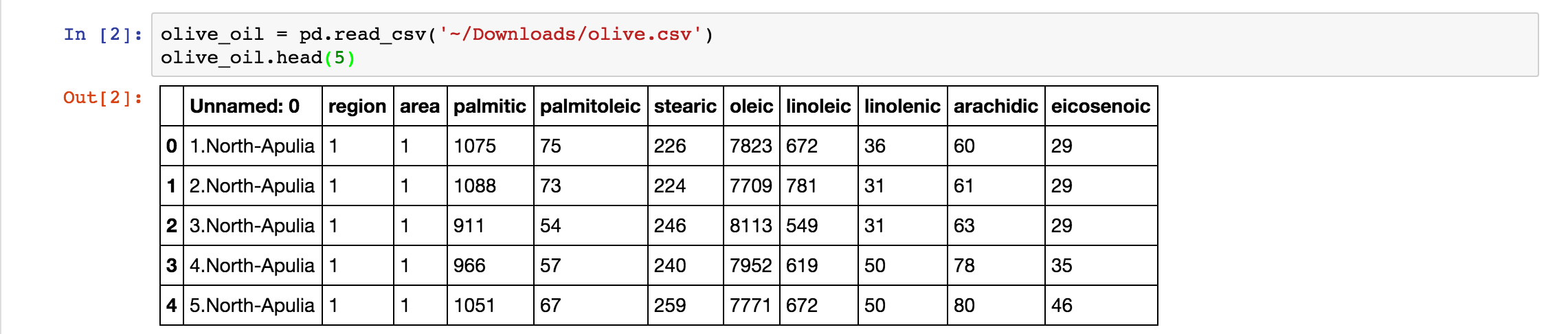
eicosenoic 二十碳烯酸我们使用 pd.read_csv() 命令来导入数据集,并且返回最上面的5行数据。如下图:
2. 重命名函数
我们计划将数据的第一列的名字 Unnamed: 0 修改为 area_Idili,那么我们可以使用重命名函数来实现这个操作。参数 inplace = True 表示你是否要修改。我们执行这个函数,得到如下结果:

3. Map操作
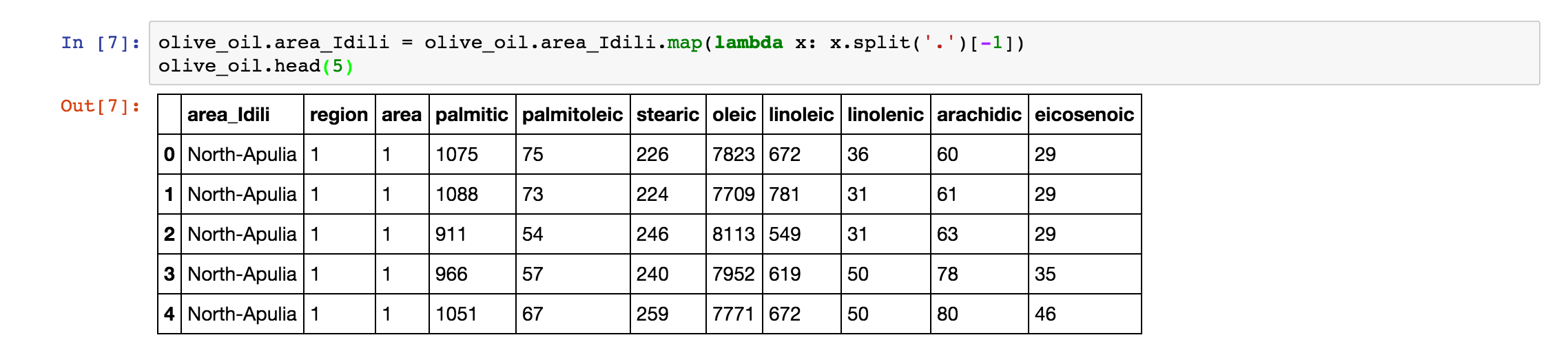
如果我要将 area_Idili 这一列的前面的数字标号去掉,那么我就会使用 map 函数来实现这个功能。map 函数将会遍历数据的每一行,如果你了解一点 MapReduce 的话,那么久很容易理解这一点了。我们运行这个操作,得到如下结果:
4. apply 函数
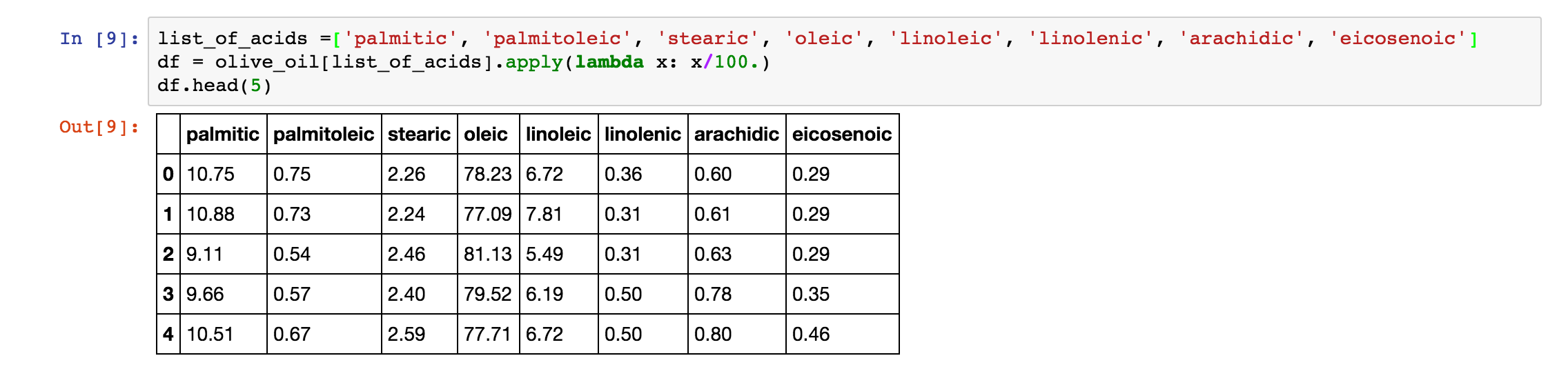
apply 函数是一个很灵活的函数,它能将函数应用到每一个列中。比如,我们想要把所有的酸的那一列的值缩小 100 倍,那么我们就可以使用这个函数,如下:
5. shape 和 columns 函数
shape 函数可以得到当前数据的维度,如下:

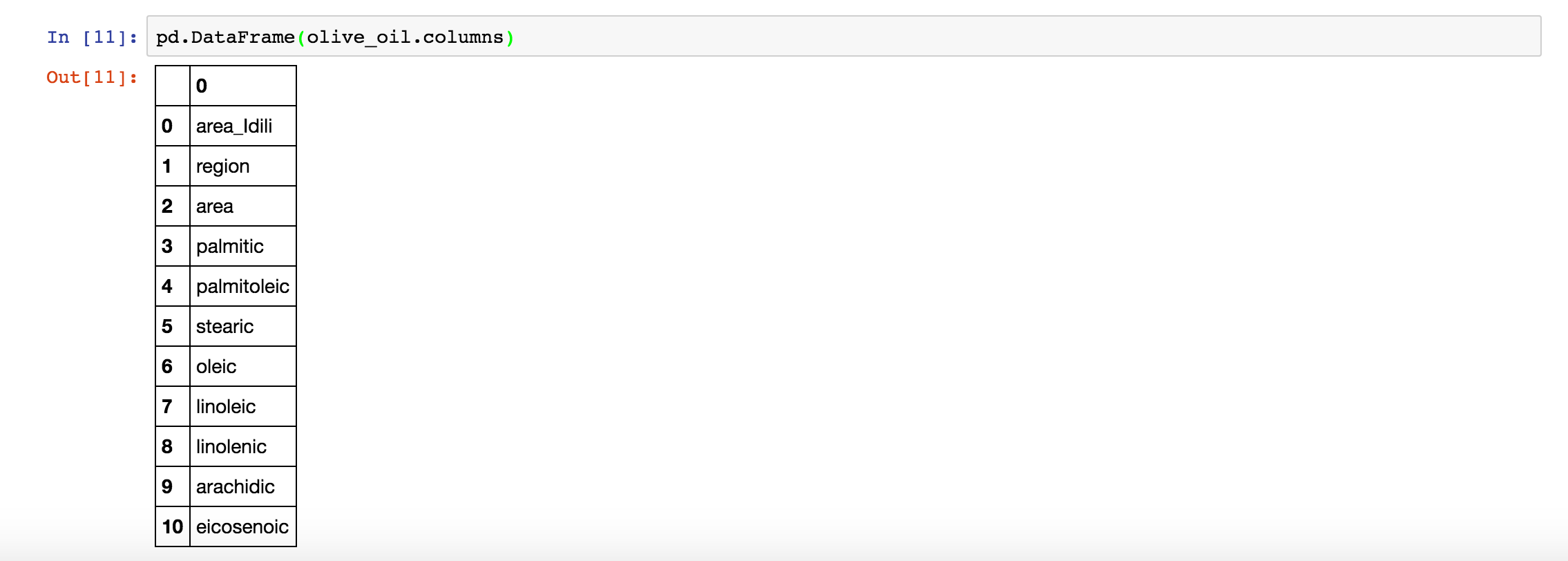
olive_oil.columns 函数将会返回每一列的列名,如下:
6. unique 函数
unique 函数是一个去重函数,我们应用 olive_oil.region.unique() 函数去得到一共有几个 region ,结果是 [1, 2, 3]应用 olive_oil.area.unique() 函数去得到一共有几个 area ,结果是 [1, 2, 3, 4, 5, 6, 9, 7, 8]。具体如下:

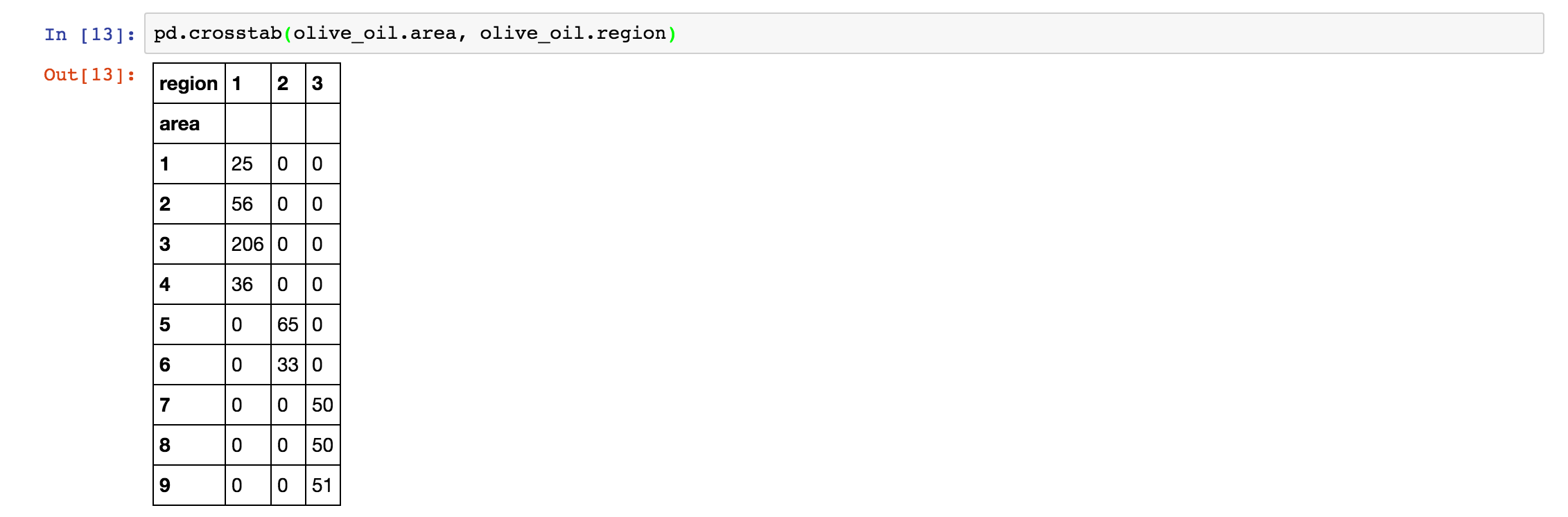
7. crosstab 函数
crosstab 函数能简单计算两个因子的交叉列表,比如我们将这个函数应用到 area 和 region 中,得到如下结果:
8. 访问数据的子集
如果我们只想访问数据的某几个子列,而不是全部列,那么可以使用如下方法:
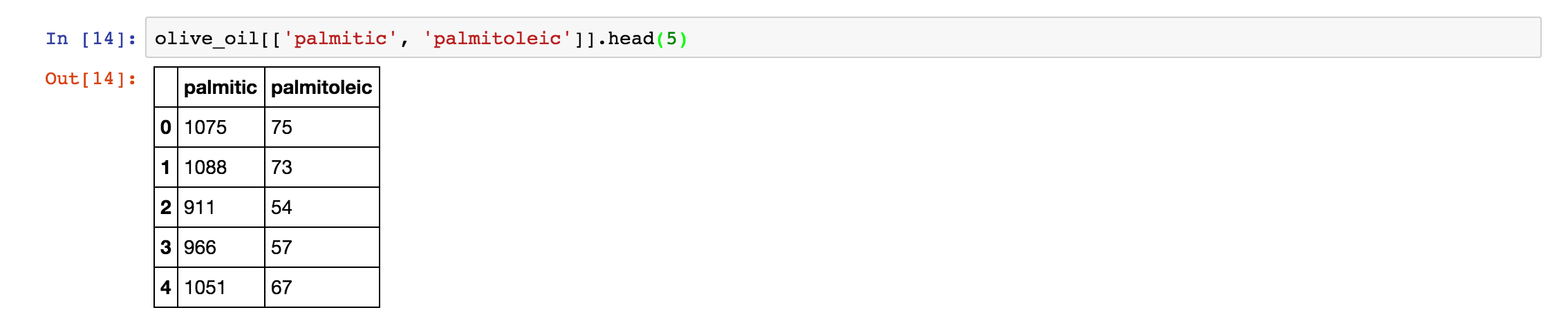
如果我们只想访问其中的一个列,那么可以使用 olive_oil['palmitic'] 或者 olive_oil.palmitic 。
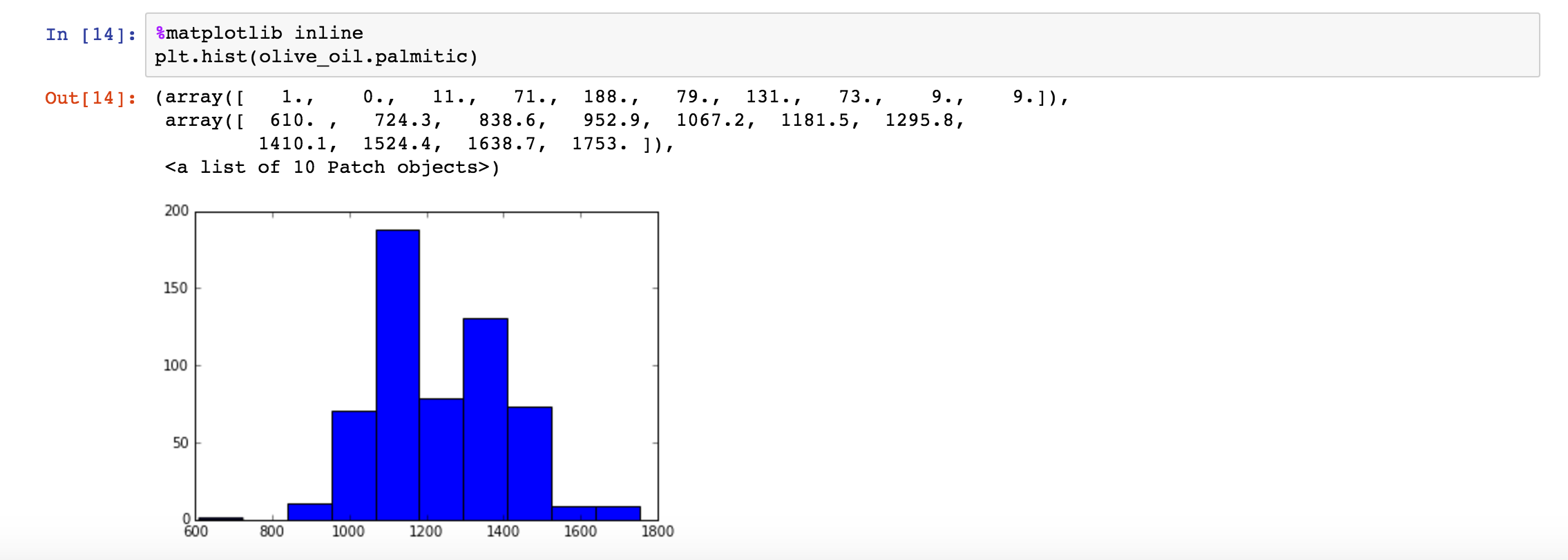
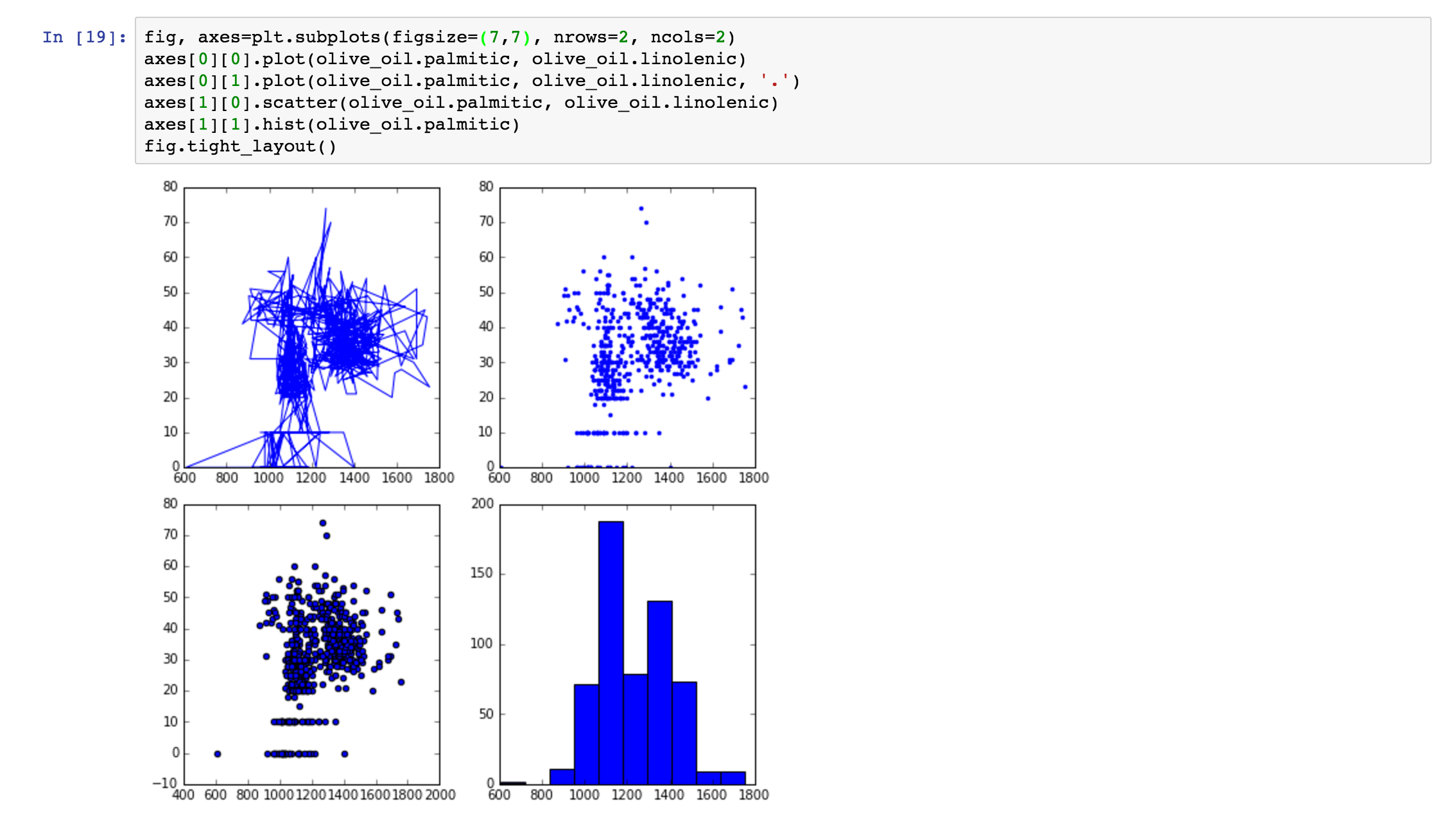
9. 可视化
plt.hist 函数可以实现可视化,具体如下:
10. groupby 和 statistic 函数
groupby 函数可以按照键值将元素进行一个聚合,比如我们聚合 region 1, 2, 3,可以使用函数 olive_oil.groupby('region') 。并且我们使用 describe 函数来做一个简单的分析,具体结果如下:

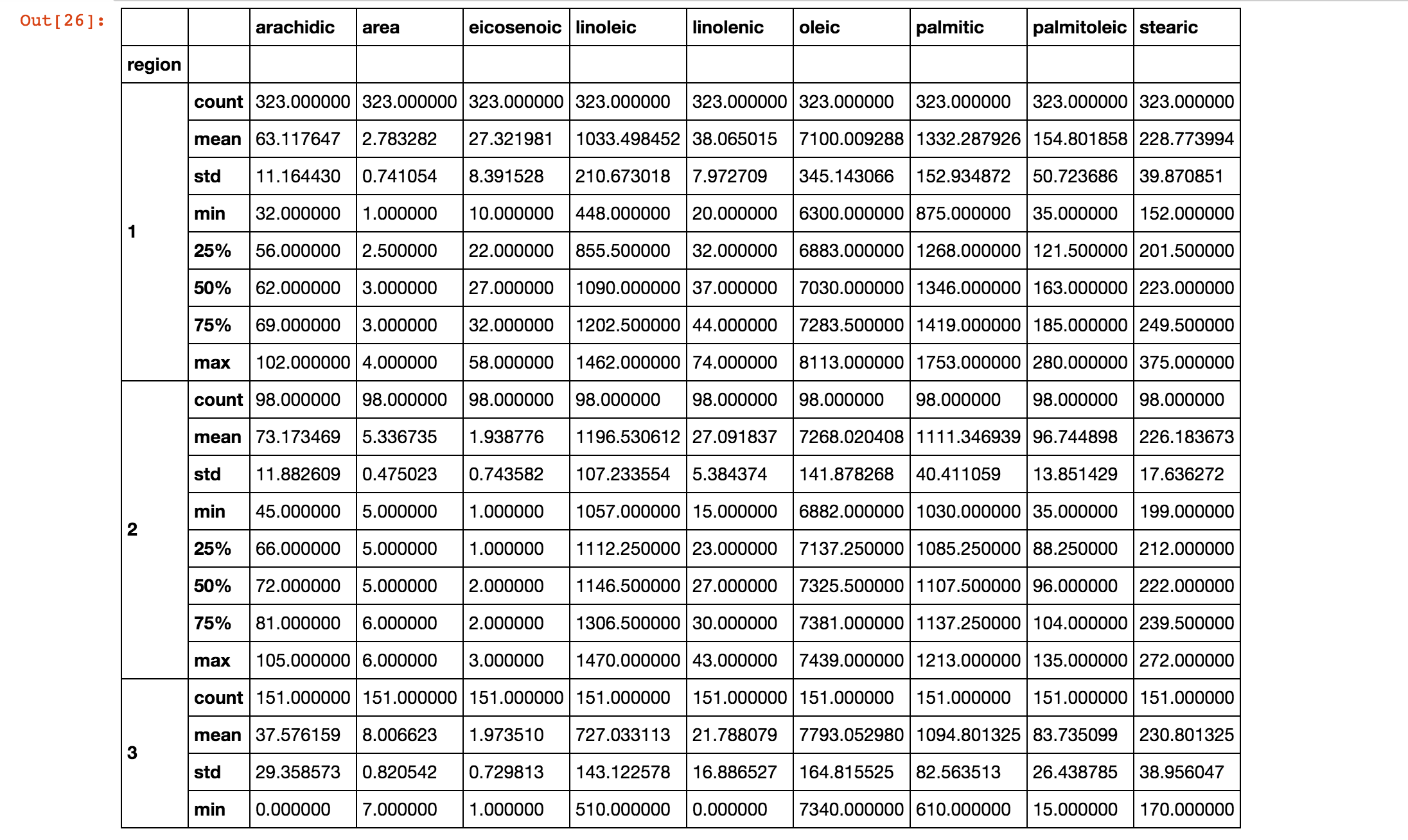
你也可以使用 olive_oil.groupby('region').std() 函数来计算标准偏差,具体如下:

11. aggregate 函数
aggregate 函数可以对数据做一个聚合操作,让数据看起来更加方便,比如我们将经过 groupby 的数据中的 mean 进行一个聚合,得到如下结果:

12. join 函数
我们先对数据进行一个重命名,具体如下:
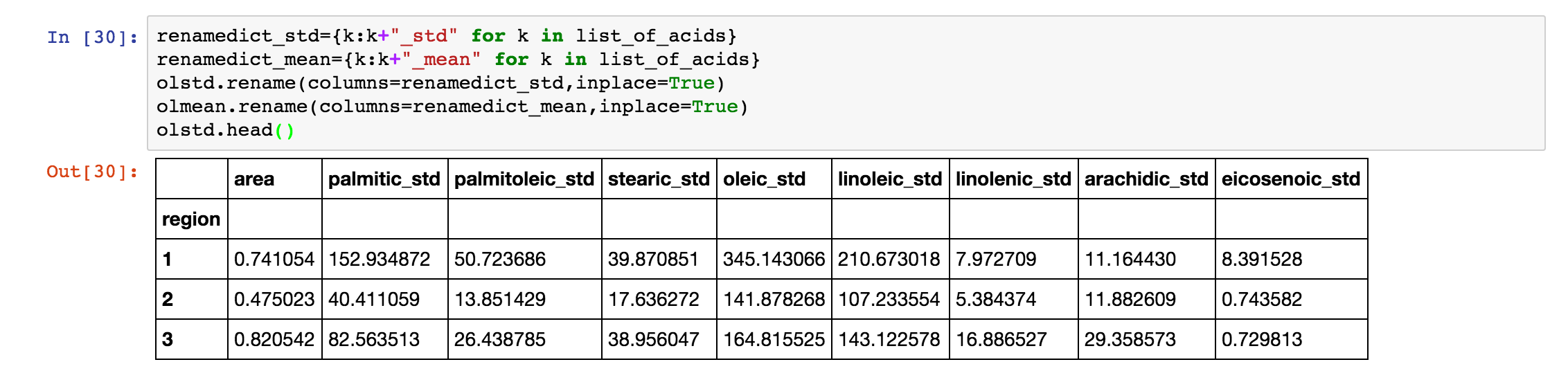
之后,我们做一个 join 操作,具体如下:

13. 元素比较操作
你还可以对数据的特定部分进行屏蔽。
如果我们要去检查数据中的 eicosenoic 列中的元素是否小于 0.05 ,那么我们就可以使用这个操作 olive_oil.eicosenoic < 0.05 ,如果数据是小于 0.05 的,那么操作将返回 true ,如果数据不是,那么操作将返回 false 。具体结果如下:
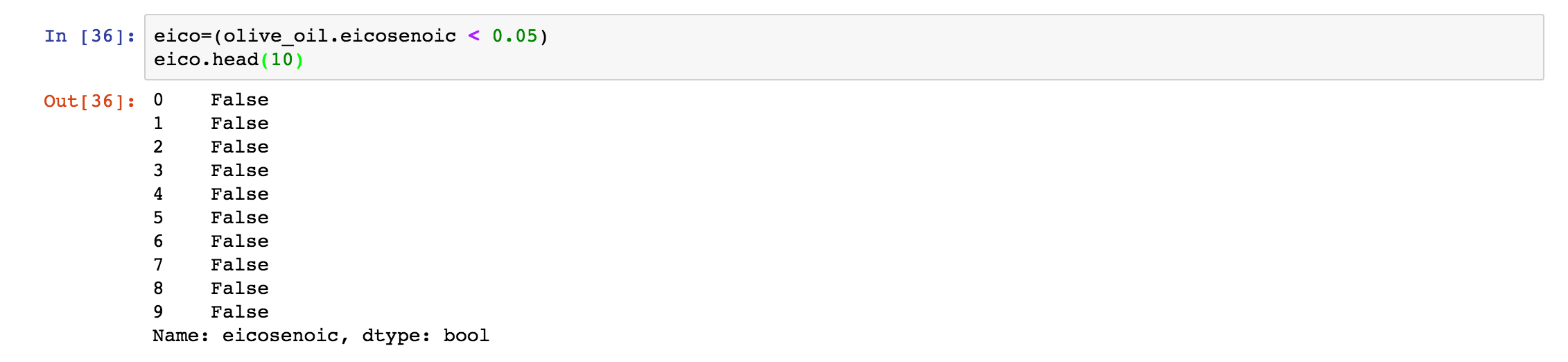
14. 处理缺失数据
在很多真实数据集中,数据缺失是一个很常见的问题。那么我们经常做的两种方法是丢失缺失的数据或者补全缺失的数据。
我们先创建一个数据集,如下:
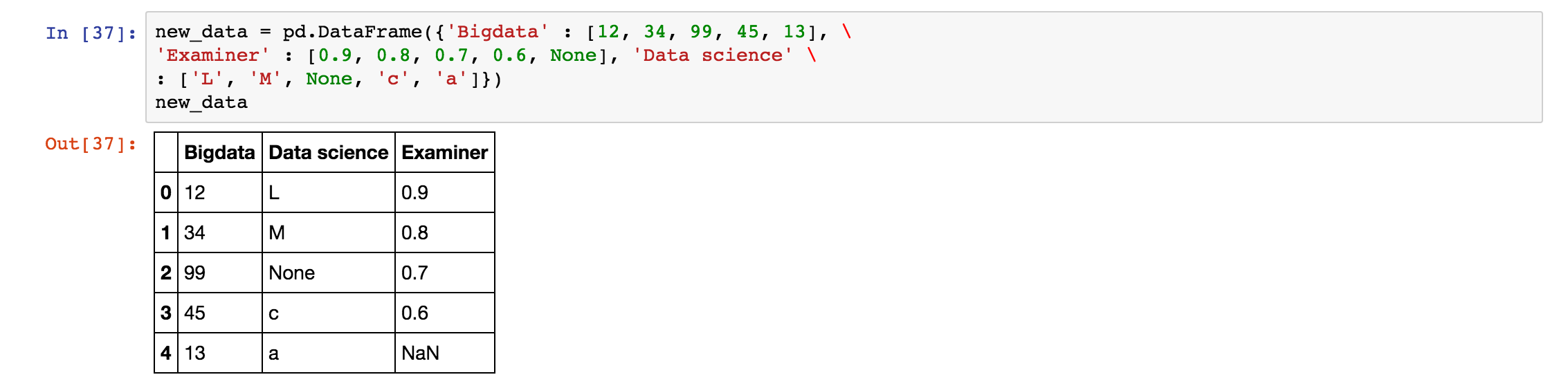
dropna 函数可以去除含有缺失元素的数据行,保留完整数据。具体结果如下:

fillna 函数可以补全缺失的数据元素。首先,我们先来创建一个新的数据集,具体如下:
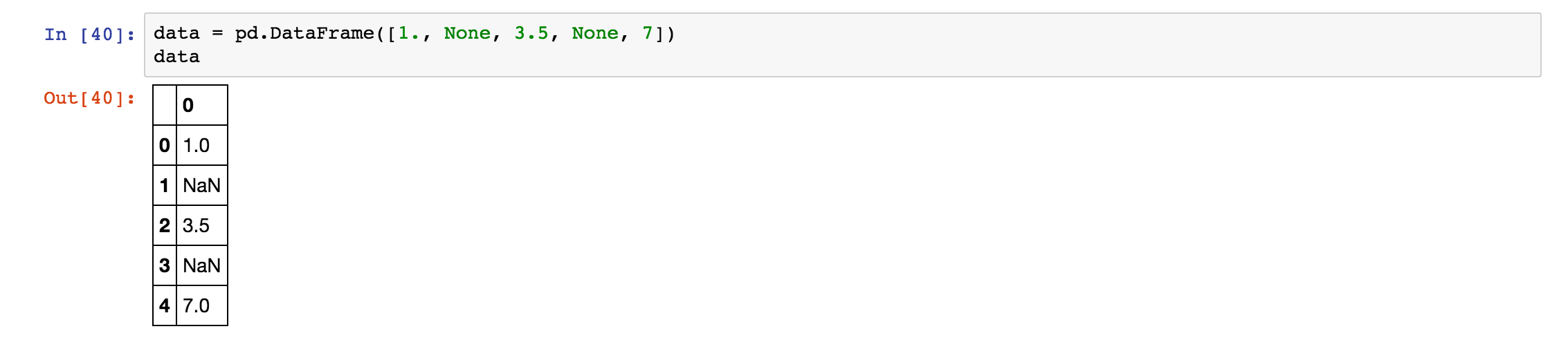
之后,我们来使用 fillna 函数来补全里面的缺失值,具体结果如下:
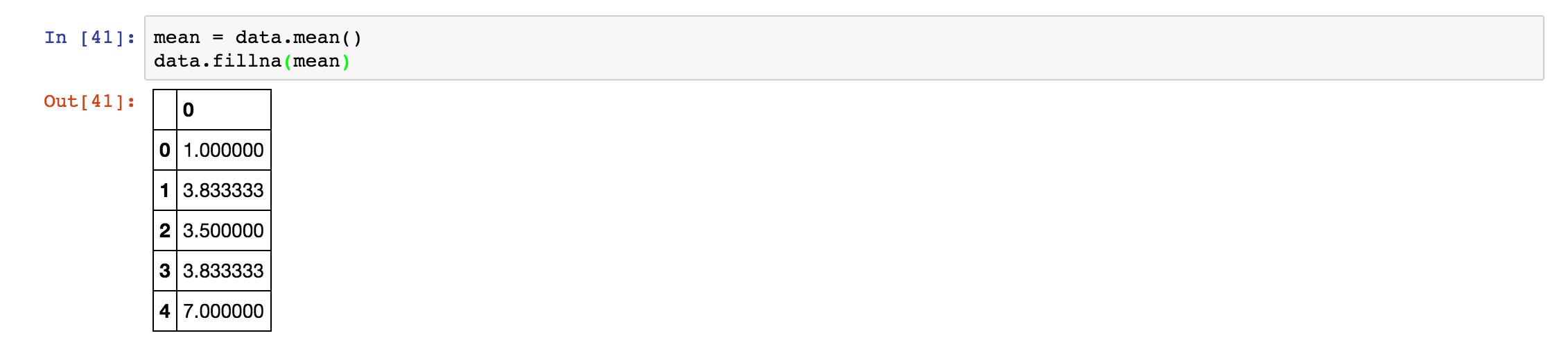
至此,我们学习完了 14 个常用的方法。如果你想深入学习,那么我推荐你可以去学习这本书 Python for Data Analysis。

















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









