






一、判断大型网站的标准
1、pv(page views)网页的浏览量
概念:一个网站所有的页面,在24小时内被访问的总的次数。千万级别,百万级别,
2、uv值(unique vistor)独立访客
概念:一个网站,在24小时内,有多少个用户来访问我们的网站。达到10万
3、独立ip
概念:一个网站,在24小时内,有多少个ip来访问我们的网站。
uv值约等于独立ip.如果要考虑局域网,uv值略大于独立ip
二、大型网站带来的一些问题
1、大的并发
并发量:在同一时间点(1秒内),有多少个用户同时访问我们的网站。对同一个网址,同时刷新浏览器。达到500,就非常大了。
假如并发量是500,pv值是多少。500*3600*10
2、大流量
网站需要的大的带宽。10G.
3、大的存储
网站中的数据库,表的容量成海量趋势,GT级别,如何快速的查找出想要的数据。
三、大并发的解决方案
要对网站的服务器重新架构,采用分层,负载均衡的架构。
1、负载均衡器
硬件:f5-bigip 性能比较好,立竿见影,价格昂贵,一般适合于大型网站公司,网游公司。
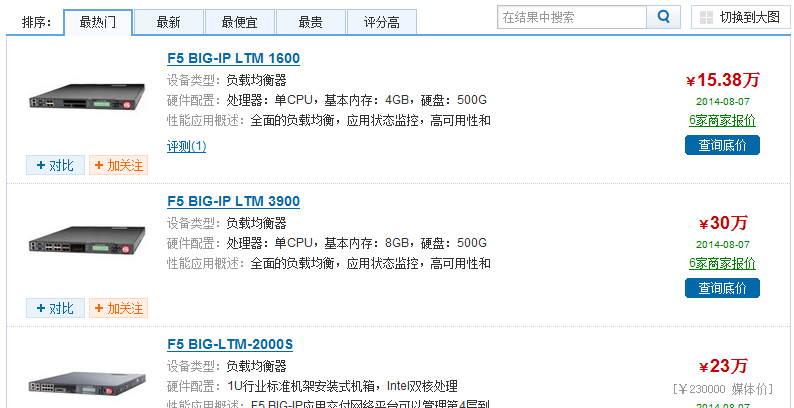
软件:
lvs(linux virtual server)linux虚拟服务,加入到linux的内核中。
nginx:可以做web服务器(apache),还可以做负载均衡。
2、负载均衡实现的方式
轮询技术:客户端请求服务器轮流转发。
ip哈希:同一ip地址的客户端,始终请求同一台服务器。
最少连接:把请求转发给最空闲的服务器。
3、集群
主要是解决计算机单点故障,在一个集群中的计算机,只有一台计算机工作,其他计算机处于休眠状态,监视正在工作的计算机,当正在工作的计算机出现问题,则休眠的计算机立刻接替工作。
四、大流量解决方案
1、防止我们的网站资源被盗链
可以采用一些非技术手段防止被盗链,在图片上添加水印

2、减少http请求
主要手段就是合并js文件,css文件,背景图片的文件。将浏览器需要的样式文件或者js文件,合并成一个样式文件或js文件。比如通过背景图片举个例子。
 具体的代码:
具体的代码:
3、启用压缩
减少数据传输的数据量,常见的压缩格式是:gzip,deflate,compress以及google、chrome正在推的sdcn
 原理:
原理:
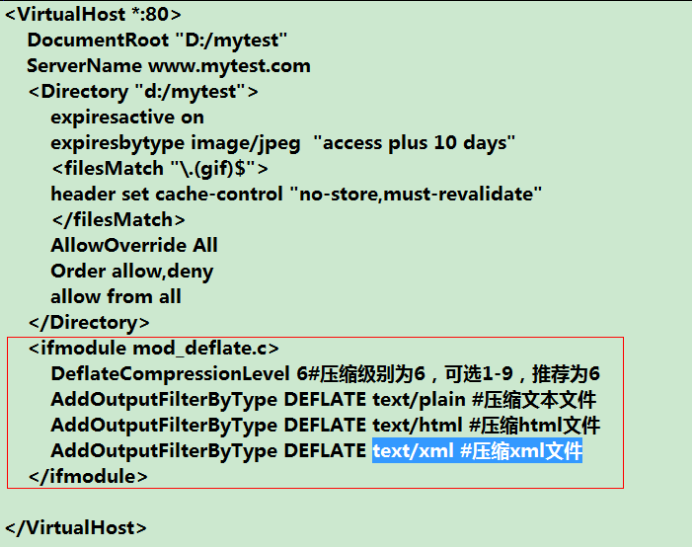
(1)在httpd.conf中开启压缩配置:LoadModule deflate_module modules/mod_deflate.so。apache中默认是deflate压缩
(2)在虚拟主机里面配置如下:
4、通过浏览器缓存数据内容
在网站中有一些资源,比如js文件,css文件,一些图片文件,更新的频率比较少。通过设置http的cache-control expires属性来进行设置缓存,可以设置缓存的文件类型,设置缓存的缓存周期
(1)打开apache的主配置文件(httpd.conf)开启缓存模块
打开apache的expires扩展:LoadModule expires_module modules/mod_expires.so
利用该扩展控制图片,css,html等文件控制缓存是否缓存,及缓存声明周期。
(2)配置选项设置
ExpiresActive On //开启缓存设置
//具体的针对文件类型设置缓存规则
ExpiresDefault "<base> [plus] {<num> <type>}*"//默认设置
ExpiresByType type/encoding "<base> [plus] {<num> <type>}*"//针对不同文件类型进行设置

(3)针对jpeg格式图片缓存配置步骤:
①新建一个虚拟主机: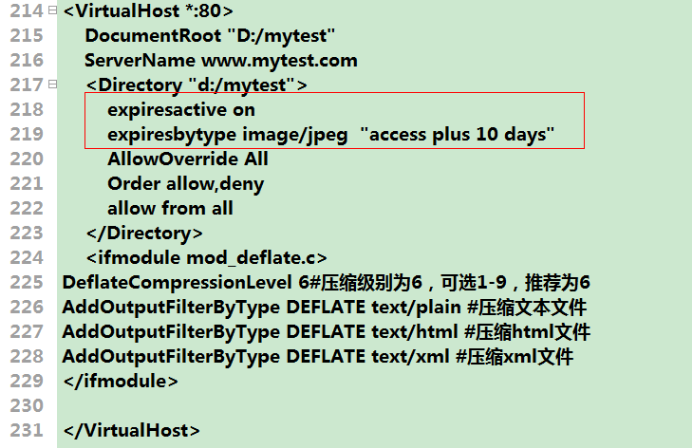 ②查看缓存效果:
②查看缓存效果: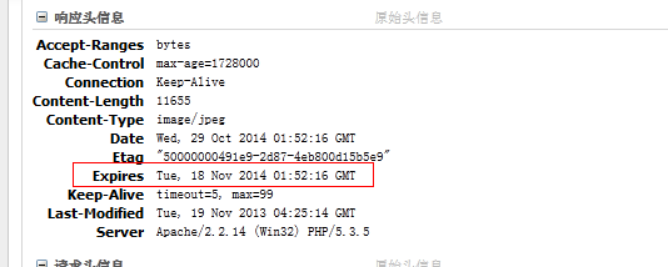
(4)针对js文件配置缓存周期
只需要把上图中虚拟主机配置image/jpeg换成application/javascript
(5)针对某些文件,不让他缓存,始终从服务器中获取内容。比如不缓存gif文件。
思路:打开apache主配置文件中header模块,配置该选项:cache-control:no-store,must-revalidate
具体步骤:
①在httpd.conf中开启header模块:LoadModule headers_module modules/mod_headers.so
②在虚拟主机里面通过正则进行如下配置:

5、可以把比较占用流量的一些资源,单独组建一个服务器
比如图片服务器,视频服务器等。
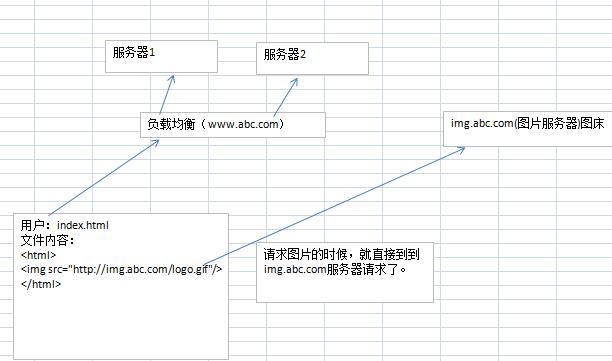
要注意:资源服务器的配置:
存储资源的服务器:主要要求是硬盘的容量,读写速度。
可以组建磁盘阵列。
raid0
raid1
磁盘阵列的存储技术:
分布存储:至少是两块硬盘
复制存储:至少是两块硬盘

6、花钱买带宽
五、大存储解决方案
1、缓存技术
通过缓存技术,达到不查询数据库或者少查询数据库的目的。
计算机的访问速度,内存》硬盘文件》数据库
缓存技术主要有:
磁盘缓存(页面静态化),把一个查询数据库的页面变成一个不查询数据库的页面
内存缓存:把经常查询的数据保存到内存里面,下次查询数据时候直接在 内存里面查询。
(memcache/redis/mysql的memory引擎)
2、在设计表的时候,要满足3范式
第一范式是:原子性,字段不能再分割了。只要是关系型数据库就自动满足第一范式:
数据库的分类:
关系型数据库:有行和 列的概念,二维表格。常见的关系型数据库:mysql,sql server,oracle,db2,
非关系型数据库(nosql)面向集合和 文档的,没有行和列的概念常见的有redis/mongodb等。
第二范式:在一个表中不能有完全相同的记录。可以通过设置一个主键。
第三范式:表中的字段不能冗余存储。

3、要给表添加适当的索引:索引非常重要的,可以提高查询速度
常见索引有:主键索引,唯一索引,普通索引,全文索引,
4、要创建适当的存储过程,函数,触发器等
5、读写分离(主从服务器)
6、分表技术(垂直分割和水平分割)
垂直分割:
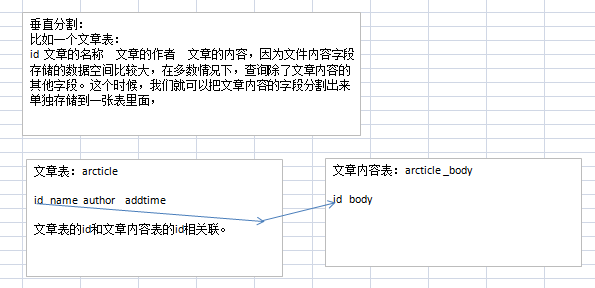
水平分割:
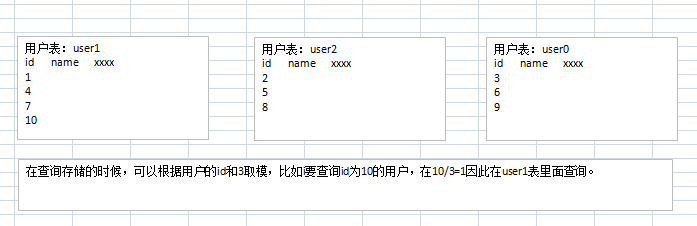
7、分区技术
把一个表的数据内容,在不同的 区域存储
8、升级mysql服务器(添加配置:加大内容,64位)
9、要对sql语句进行调优
select * from tablename 该语句不要使用,要按需查询。需要哪个字段的数据,就查询哪个字段的数据。
10、对配置文件进行优化配置
比如配置mysql数据库的并发量: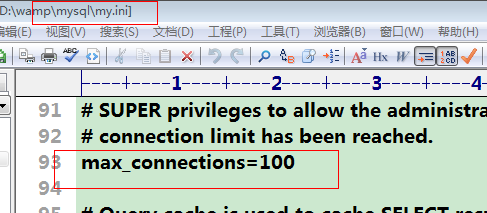
六、网页静态化的内容
主要有两种:
真静态:就是把一个动态(查询数据库)的页面,转换成一个静态的页面html页面
优点: 1. 速度快 2. 安全性高 3. 利于seo
缺点:就是占有磁盘空间., 如果过大,对磁盘响应速度有影响
在什么情况下,建议不要使用真静态
- 页面的数据更新频繁,最好不要使用真静态(比如股票,基金,等实时报价系统)
- 会生成海量页面(比如大型论坛 bbs ,csdn)
- 查询该页面一次后,以后再也不查询该页面.
- 不愿意被搜索引擎抓取的页面.
- 访问量小的页面.
伪静态:从形式上看url地址是一个静态的页面,实际上还是要查询数据库的。
比如http://www.abc.com/news-soprt-id100.html实际上对应http://www.abc.com/news.php?type=sport&id=100
1、网页静态化的使用原理

2、了解几个概念
动态的网址:一般来说,该页面有查询数据库的功能,比如后缀是:(php|asp|aspx|jsp)
特点:查询数据库,访问速度慢,可能sql注入,不是很安全,不是利于seo
静态的网址:一般来说就是html页面。
特点:不查询数据库,访问速度快,安全,利于seo
伪静态网址:从形式上看是一个静态网址,实际上是一个动态页面,
特点:查询数据库,安全,利于seo
比如:http://localhost/1028/demo.php/goods_id100.html
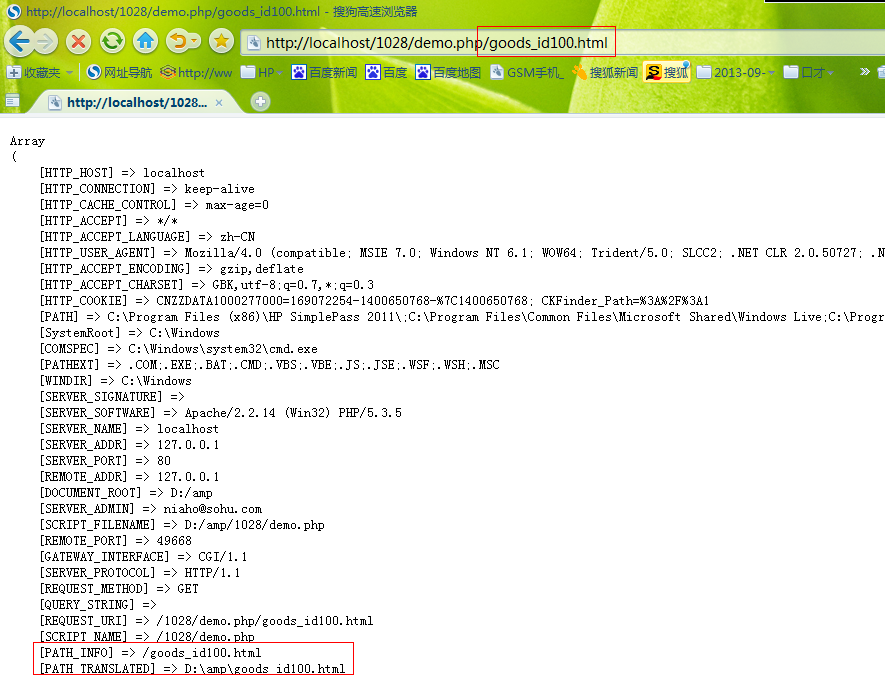
3、实现静态化的方式
真静态实现方式:
(1)通过ob缓存技术来实现
①概念:什么是ob缓存:
ob缓存:output_buffering:输出缓存,我们请求一个php页面,实际上是通过三个缓存的。
ob缓存(如果开启)---》程序缓存------》浏览器缓存,要注意:程序缓存和浏览器缓存必须存在的。
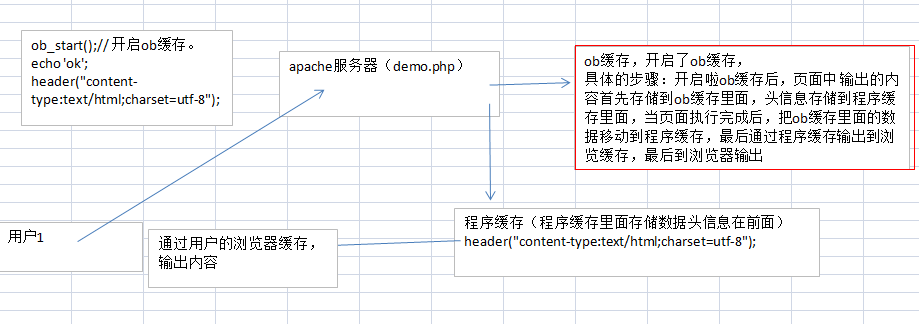
②如何开启ob缓存:
第一种方式:通过ob_start()函数,只对当前页面有效
第二种方式:通过php.ini文件中: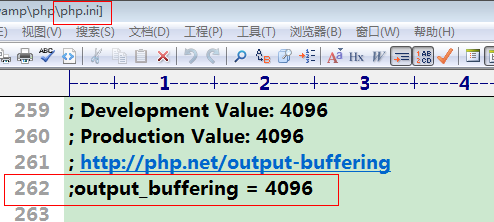
③学习几个函数来讲解
ob_clean();清除ob缓存里面的数据,并不关闭ob缓存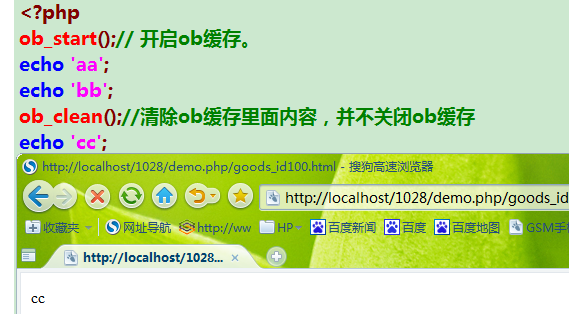
ob_end_clean():清除ob缓存里面的数据,并关闭ob缓存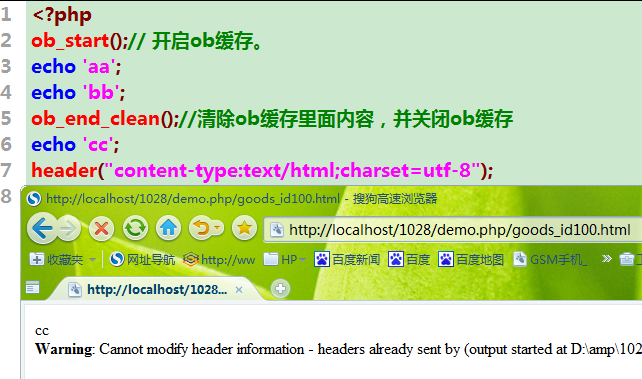
ob_flush();把ob缓存里面的数据刷新到程序缓存,并不关闭ob缓存。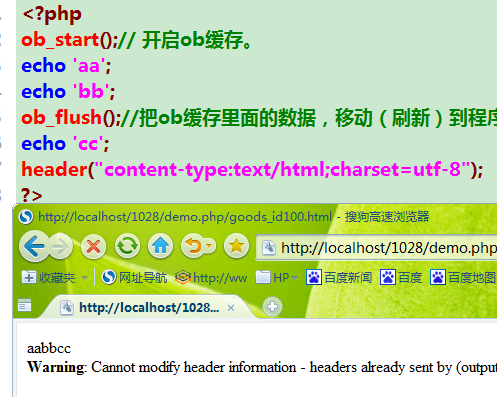
ob_end_flush():把ob缓存里面 的数据移动到程序缓存,并关闭ob缓存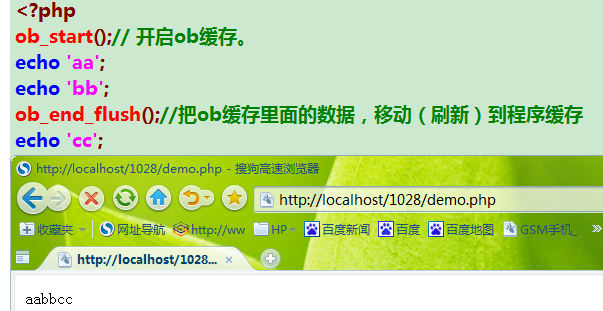
ob_get_contents();获取ob缓存里面数据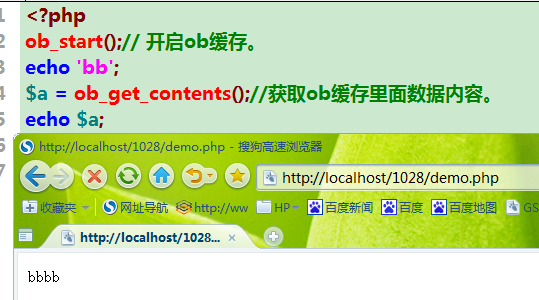
④利用ob缓存完成一个真静态案例
思路:判断该页面对应的静态页面,是否存在,若存在的直接访问静态页面,不存在则通过数据库查询出数据,并生成一个静态页面。
具体的代码:
<?php
header("content-type:text/html;charset=utf-8");
$filename="index.html";
//思路:判断该页面对应的静态页面,是否存在,
if(file_exists($filename)){
include $filename;exit;
}
//连接数据库的操作:
$conn = mysql_connect("localhost",'root','root');
mysql_query("use itdede");
mysql_query("set names utf8");
$sql="select title from dede_archives limit 10";
$res = mysql_query($sql,$conn);
$list=array();
while($row=mysql_fetch_assoc($res)){
$list[]=$row;
}
ob_start();
//echo 'ok';
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN">
<head>
<title>新建网页</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="description" content="" />
<meta name="keywords" content="" />
<script type="text/javascript"></script>
<style type="text/css"></style>
</head>
<body>
<table width="500" border="1" >
<tr><td>电影名称</td><td>操作</td></tr>
<?php foreach($list as $v){?>
<tr><td><?php echo $v['title']?></td><td>电影 详情</td></tr>
<?php }?>
</table>
</body>
</html>
<?PHP
$contents = ob_get_contents();
file_put_contents($filename,$contents);
?>
⑤案例扩展,要给生成对应的静态页面一个有效期
判断条件:对应的静态页面要存在,而且在有效期内,就可以直接读取静态页面。
如何计算在有效期内:对应静态页面的修改的时间戳+有效期>当前的时间戳
filemtime($filename)+300>time();
假如一个网站并发是1000,不缓存的话。60秒之内查询数据库多少次。 60000次
假如一个网站并发是1000,缓存60秒的话,60秒之内查询数据库多少次。 1次
具体的代码:
<?php
header("content-type:text/html;charset=utf-8");
$filename="index.html";
//思路:判断该页面对应的静态页面,是否存在,
if(file_exists($filename) && filemtime($filename)+10>time()){
include $filename;exit;
}
//连接数据库的操作:
$conn = mysql_connect("localhost",'root','root');
mysql_query("use itdede");
mysql_query("set names utf8");
$sql="select title from dede_archives limit 10";
$res = mysql_query($sql,$conn);
$list=array();
while($row=mysql_fetch_assoc($res)){
$list[]=$row;
}
ob_start();
echo time();
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN">
<head>
<title>新建网页</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="description" content="" />
<meta name="keywords" content="" />
<script type="text/javascript"></script>
<style type="text/css"></style>
</head>
<body>
<table width="500" border="1" >
<tr><td>电影名称</td><td>操作</td></tr>
<?php foreach($list as $v){?>
<tr><td><?php echo $v['title']?></td><td>电影 详情</td></tr>
<?php }?>
</table>
</body>
</html>
<?PHP
$contents = ob_get_contents();
file_put_contents($filename,$contents);
?>
该案例重点是:理清如下思路即可
//思路:判断该页面对应的静态页面,是否存在,
if(file_exists($filename) && filemtime($filename)+10>time()){
include $filename;exit;
}
(2)通过模板替换技术来实现
①新建一个模板文件,tpl.html:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN">
<head>
<title>新建网页</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="description" content="" />
<meta name="keywords" content="" />
<script type="text/javascript"></script>
<style type="text/css"></style>
</head>
<body>
<h1>新闻的详情页面</h1>
<h3>%title%</h3>
<hr>
<div>%content%</div>
</body>
</html>
②创建生成的静态页面的路径,创建数据库中filename字段的存储路径
<?php
$act = isset($_GET['act'])?trim($_GET['act']):"";
$conn = mysql_connect("localhost",'root','root');
mysql_query("use php");
mysql_query("set names utf8");
//添加新闻
if($act=='add'){
//接收表单提交过来数据
$title = $_POST['title'];
$content = $_POST['content'];
$sql="insert into news(title,content) values('$title','$content')";
$res = mysql_query($sql,$conn);
$id = mysql_insert_id($conn);
if(!$id){
die("添加失败");
}
$dir = date("Ym/d");
$file="news_id".$id.'.html';//表示生成的静态文件的名称
$dir_path="../a/".$dir;
//要判断$dir_path目录是否存在,如果不存在则创建。
if(!is_dir($dir_path)){
mkdir($dir_path,0777,true);
}
$filename =$dir_path.'/'.$file; //生成的静态文件的完整路径;
$filename_path="./a/".$dir.'/'.$file;//存储到数据库filename字段中的静态页面的路径:
//打开模板文件
$tpl_ph=fopen('tpl.html','r');
//创建对应的静态页面。
$file_ph=fopen($filename,'w');
//完成替换
//feof()函数,返回文件指针是否到文件的末尾,如果到则返回的真。
while(!feof($tpl_ph)){
$row=fgets($tpl_ph);//fgets()函数是读取一行内容
$row=str_replace('%title%',$title,$row);//str_replace()该函数返回替换之后的结果
$row=str_replace('%content%',$content,$row);
fwrite($file_ph,$row);//把替换之后的内容,写入到$filename文件中。
}
fclose($tpl_ph);//关闭文件指针
fclose($file_ph);//关闭文件指针
//把生成的对应静态页面的路径存储到数据库里面的filename字段
$sql="update news set filename='$filename_path' where id=$id";
$res = mysql_query($sql);
$num = mysql_affected_rows($conn);
if(!$num){
die("失败");
}
echo '添加成功';
echo "<a href='index.php'>返回首页</a>";
}
?>
③新建一个makehtml.php页面完成,前台首页的生成。
<?php
$conn = mysql_connect("localhost",'root','root');
mysql_query("use php");
mysql_query("set names utf8");
$sql="select id,title,filename from news";
$list=array();
$res = mysql_query($sql,$conn);
while($row=mysql_fetch_assoc($res)){
$list[]=$row;
}
ob_start();
?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN">
<head>
<title>新建网页</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="description" content="" />
<meta name="keywords" content="" />
<script type="text/javascript"></script>
<style type="text/css"></style>
</head>
<body>
<h1>新闻列表页面</h1>
<table width="500" border="1">
<tr><td>新闻标题</td><td>新闻详情</td><td>操作</td></tr>
<?php foreach($list as $v){?>
<tr><td><?php echo $v['title']?></td><td><a href="<?php echo $v['filename']?>">新闻详情</a></td><td>操作</td></tr>
<?php }?>
</table>
</body>
</html>
<?php
$str = ob_get_contents();
file_put_contents("../index.html",$str);
ob_clean();
echo "首页已经已经生成 <a href='../index.html'>返回前台首页</a>";
?>
伪静态实现方式:
(1)通过正则表达式,匹配替换
<?php
$path_info = $_SERVER['PATH_INFO'];//获取到 地址中:news_id1.html
$patt = '/news_id(\d{1,3})\.html$/';
preg_match($patt,$path_info,$a);//$a用于存储匹配到的内容。
$id = $a[1];
$conn = mysql_connect("localhost",'root','root');
mysql_query("use php");
mysql_query("set names utf8");
$sql="select title,content from news where id = $id";
$res = mysql_query($sql,$conn);
$row=mysql_fetch_assoc($res);
?>
(2)通过服务器的rewrite机制
①打开apahce的主配置文件(httpd.conf),开启rewrite模块:
LoadModule rewrite_module modules/mod_rewrite.so
②请求abc.html转换成请求123.php,虚拟机配置如下:
方法一: 
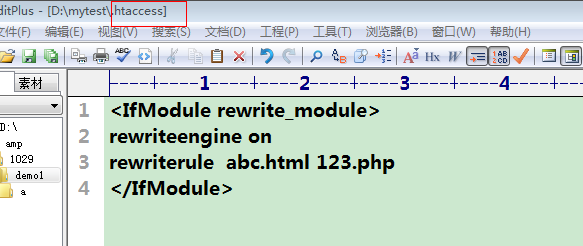
方法二:新建一个.htaccess文件配置重写规则,要注意:要使该文件有效,则必须在虚拟主机里面设置。AllowOverride All

③虚拟机中常用配置
#配置是否显示文件目录:[indexes|none]
Options indexes FollowSymLinks //配置显示文件目录,如果没有配置欢迎页面 
如果配置成 options none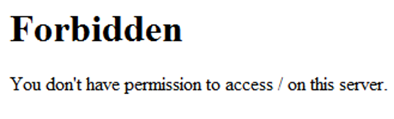
#配置错误跳转页面。主要防止用户请求的页面不存在,如果用户访问的页面不存在,则给一个友好的提示

#配置网站的欢迎页面:DirectoryIndex abc.html
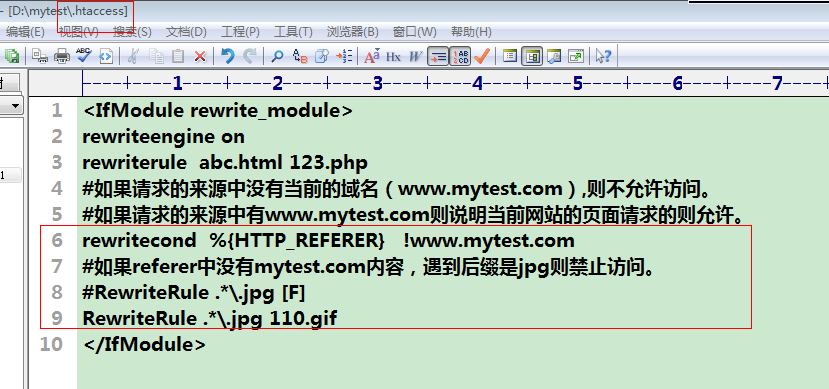
④使用rewrite机制利用referer头信息完成防盗链
七、apache并发工具测试
1、ab.exe测试
我们做好一个网站后,要测一下当前网站架构,能够支持并发情况。
测试工具:
可以使用apache自带的一个工具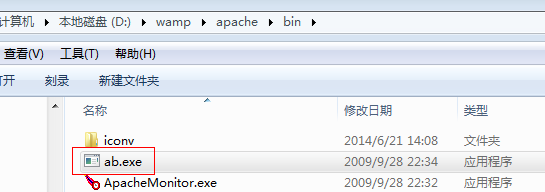
并发测试的工具有很多,常用的压力测试软件:
ab : 优点:可以模拟各种请求 缺点:最大只能支撑1000的并发
webbench: 优点:30000万的 并发 缺点:只能模拟GET请求
loadrunner : 非常专业的压力测试软件
winrunner:专业的压力测试软件。
ab.exe -n访问的总的次数 -c用户并发数量(有多少人同时访问)网站的地址。
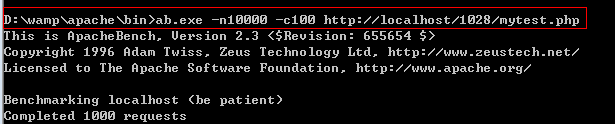
测试结果:
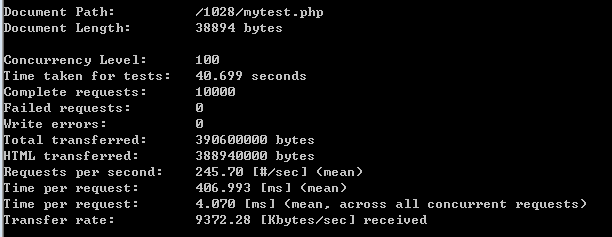
请求的时间越短越好。
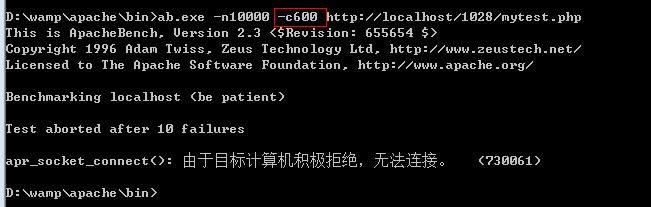
把同时请求的人数调整到600则出现了问题。实际上,在默认情况下,apahce最高支持150并发。
2、要调整apache的并发配置,要清楚处理多并发的方式
首先搞清楚当前apache是什么MPM(多路处理模块), 通俗讲就是apache处理多并发的方式,
常见的有三种
(1)perfork(预派生模式) 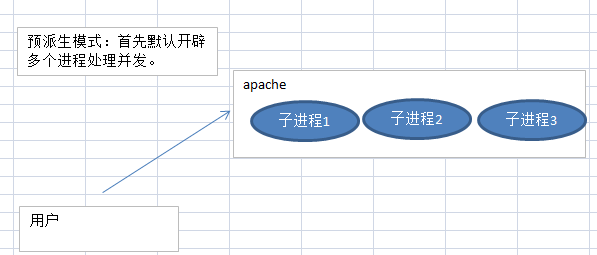
(2)worker(工作者模式) 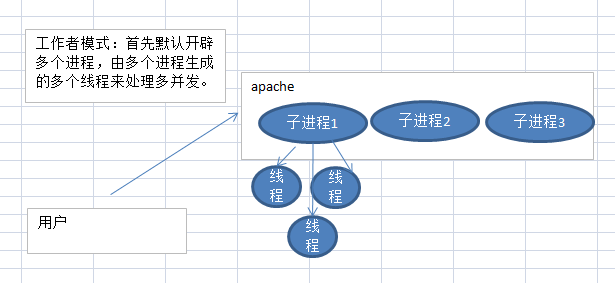
(3)winnt模式(windows下默认的模式)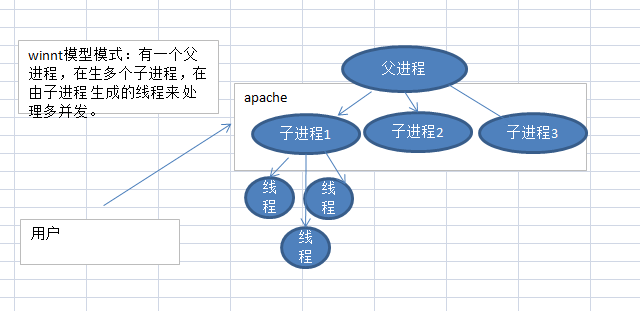
3、如何知道,当前apache服务器是使用哪一种方式处理并发
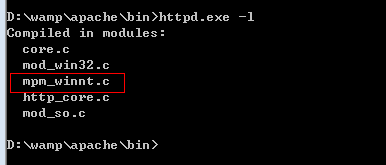
4、如何配置MPM(多路处理模块)的问题,调整最大的并发量。
(1)打开apache的配置文件 httpd.conf,开启多路处理模型
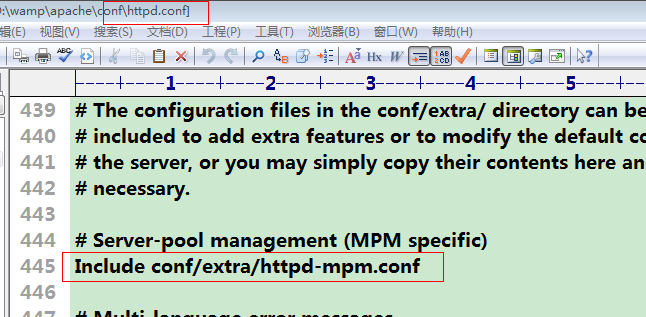
(2)打开extra目录下面的httpd-mpm.conf辅助配置文件。
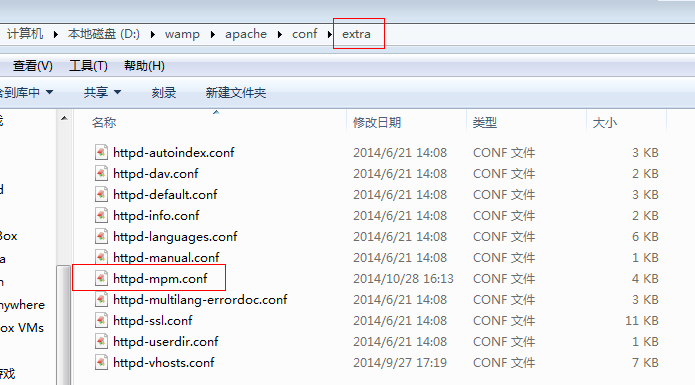
(3)根据当前apache的mpm的方式进行调整如下:

测试如下:
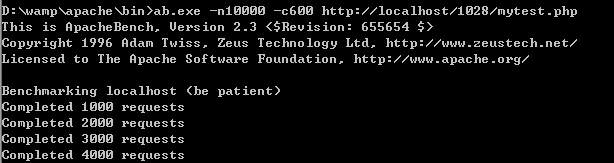
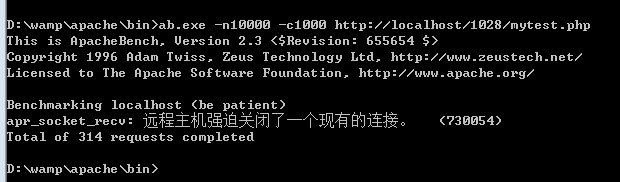
还要注意:虽然调整成了1000但是测试无法完成,原因是,还要和当前服务器的环境配置有关系,并不是说调整成1000,就能支持到1000.
5、一般在linux系统下面,apache的mpm方式是预派生模式。有一个推荐的配置
在linux下一般是perfor模式
给大家一个合理的建议配置. 对大部分网站,中型网站,配置:
<IfModule mpm_prefork_module>
StartServers 5 #预先启动
MinSpareServers 5
MaxSpareServers 10 #最大空闲进程
ServerLimit 1500 #用于修改apache编程参数
MaxClients 1000 #最大并发数
MaxRequestsPerChild 0 #一个进程对应的线程数,对worker 更有效果。如果是0则不让进程死掉。
</IfModule>
如果你的网站pv值 百万
ServerLimit 2500 #用于修改apache编程参数
MaxClients 2000 #最大并发数
总结:
1大型网站的标准(pv,uv,独立ip)
2、带来的问题:大并发,大流量,大的存储
3、大并发解决。网站服务器架构调整(负载均衡,集群,数据库的读写分离)
4、大流量的解决:防止被盗链,启用压缩,启用缓存,减少http请求,增加带宽。
5、大存储的解决:缓存,表要符合三范式,添加索引,存储过程,对sql语句调优,分表和分区,服务器的配置加强。
6、静态化,真静态,伪静态,
真静态实现方式:ob缓存,模板替换技术
伪静态:正则替换,rewrite机制。
7、ab.exe 工具使用。
ab.exe –n 访问的总的次数 -c并发量 页面地址。
mpm(多路 处理模块)并发的处理方式
常见的有:预派生,工作者,winnt,
如何查看自己的mpm是哪种模式:httpd.exe –l















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









