






Elastic Job在Master节点时会可能多次调用bug
如果LiteJob有设置AbstractDistributeOnceElasticJobListener 监听器会在执行器调用各个节点的分配作业前后调用接口定义的两个方法: `
/**
-
弹性化分布式作业监听器接口.
-
@author zhangliang */ public interface ElasticJobListener {
/**
- 作业执行前的执行的方法.
- @param shardingContexts 分片上下文 */ void beforeJobExecuted(final ShardingContexts shardingContexts);
/**
- 作业执行后的执行的方法.
- @param shardingContexts 分片上下文 */ void afterJobExecuted(final ShardingContexts shardingContexts); } `
下面是执行器调用的时序图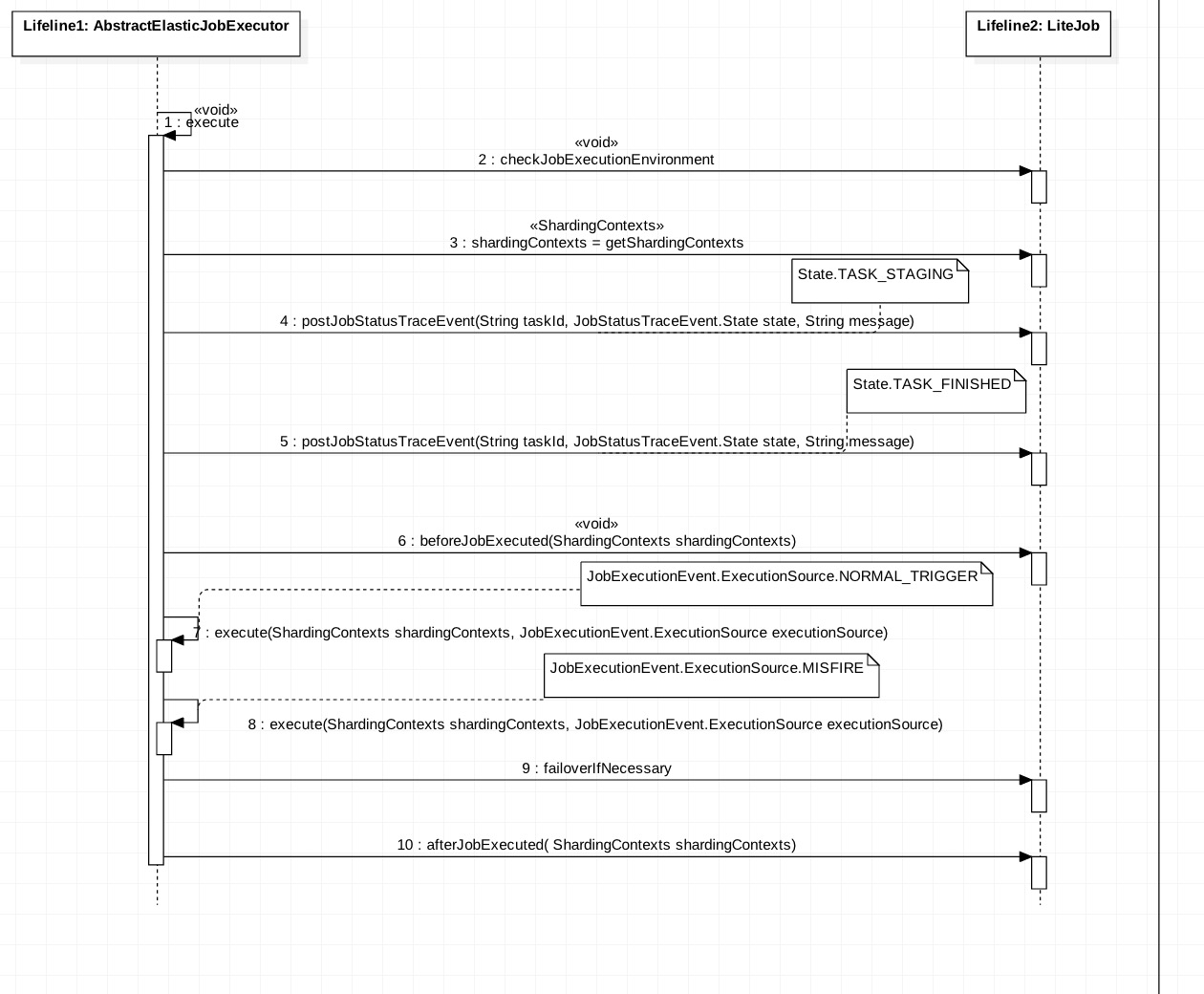
我在项目中设置了监听器,部署了两个Job节点,从官方文档看说只会在其中一个节点调用上述的两个方法,我在项目日志中方式有时会同时调用两个节点的上述两个方法,导致统计数据错误。
来看下Elastic Job是如何确保只有一个节点作为Master的:
` AbstractDistributeOnceElasticJobListener.java
public final void beforeJobExecuted(final ShardingContexts shardingContexts) { guaranteeService.registerStart(shardingContexts.getShardingItemParameters().keySet());
//在调用beforeJobExecuted之前,两个Job节点要将自己的分片信息保存到ZooKeeper中
if (guaranteeService.isAllStarted()) {
doBeforeJobExecutedAtLastStarted(shardingContexts);
guaranteeService.clearAllStartedInfo();
return;
}
......
}
GuaranteeService.java
public void registerStart(final Collection<Integer> shardingItems) {
//Job节点将自己的分片信息保存到ZooKeeper中
for (int each : shardingItems) {
jobNodeStorage.createJobNodeIfNeeded(GuaranteeNode.getStartedNode(each));
}
}
/**
* 判断是否所有的任务均启动完毕.
*
* [@return](https://my.oschina.net/u/556800) 是否所有的任务均启动完毕
*/
public boolean isAllStarted() {
//判断是否可用开始执行的条件是两个节点的分配信息是否都保存到ZooKeeper中
return jobNodeStorage.isJobNodeExisted(GuaranteeNode.STARTED_ROOT)
&& configService.load(false).getTypeConfig().getCoreConfig().getShardingTotalCount() == jobNodeStorage.getJobNodeChildrenKeys(GuaranteeNode.STARTED_ROOT).size();
}
` 从上面的代码中看出,只要两个节点同时将各自的分配信息保存到ZooKeeper中,就可能同时执行doBeforeJobExecutedAtLastStarted方法。 这里额外说明,Elastic Job的定时框架是Quartz,只要两个Job节点机器的时间一样,有很大可能会同时触发上述Bug
我在项目中采用分布式锁(Curator的InterProcessMutex)解决上述的问题。
这是一个坑,因为是在国庆前几天将Job迁移到Elastic Job,而且作业的cron是每5分钟一次,所以一开始上述的bug经常重现。
去了Github上看Elastic Job的issue,发现之前就已经有人提出这个bug,不过Elastic Job团队一直没有修复















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









