






1.概述
在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。堆其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。我们一般称管理堆的那部分程序为堆管理器。
堆管理器处于用户程序与内核中间,主要做以下工作
1).响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
2).管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
2.内存分配背后的系统调用
无论是 malloc 函数还是 free 函数,我们动态申请和释放内存时,都经常会使用,但是它们并不是真正与系统交互的函数。这些函数背后的系统调用主要是 (s)brk 函数以及 mmap, munmap 函数。
3.数据结构
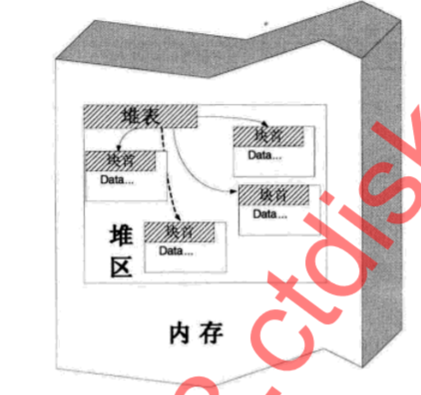
1).堆块
堆块分为块首和块身,块首是一个堆块头部的几个字节,用于标识这个堆块自身的信息。
块首大小为8字节
2).堆表(空表和快表)
位于堆区的起始位置,堆表分为两种空闲双向链表Freelist(空表 128条)和快速单向链表Lookaside(快表 最多只有四项)
空表:双向回环链表
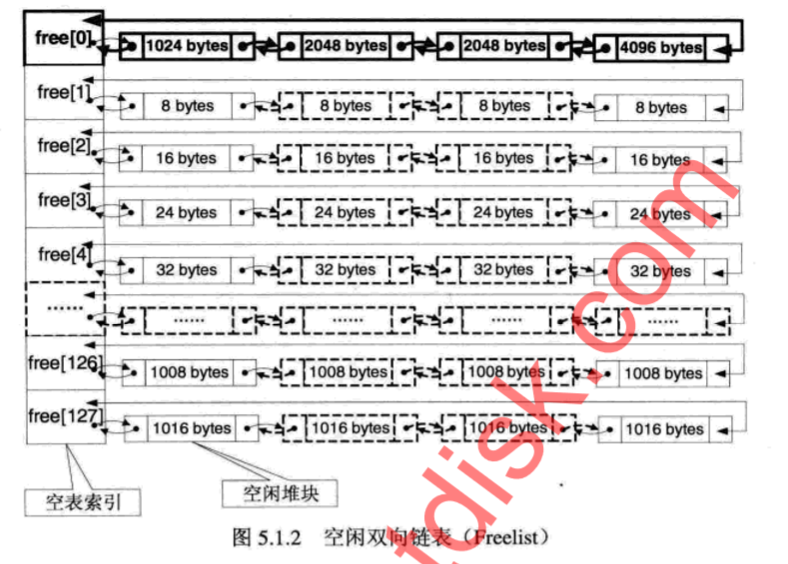
快表:单向链表

堆区一开始的堆表区中有一个128项的指针数组(看到有人说把它看成队列的),被称作空表索引。该数组的每一项包含两个指针,用于表示一条空表。
free[1] 标识了所有堆中所有大小为8字节的空闲堆块,之后每个索引指示的空闲堆块递增8个字节。即:
free[2]标识了16个字节的空闲堆块。
free[k] 标识了 k * 8 个字节的空闲堆块。
区别
a) 以上两个都为128大小的指针数组 (空表每一项有两个指针,快表每一项有一个指针)
b) 快表最多只有四个节点
c) 空表除了数组的第一个元素外其他分别链接:数组下标*8 大小的堆块,数组的第一个元素链接着大于1kb的堆块,并升序排序
d) 快表的堆块处于占用状态,不会发生堆块合并
e) 快表的只存在精确分配,快表优先空表分配
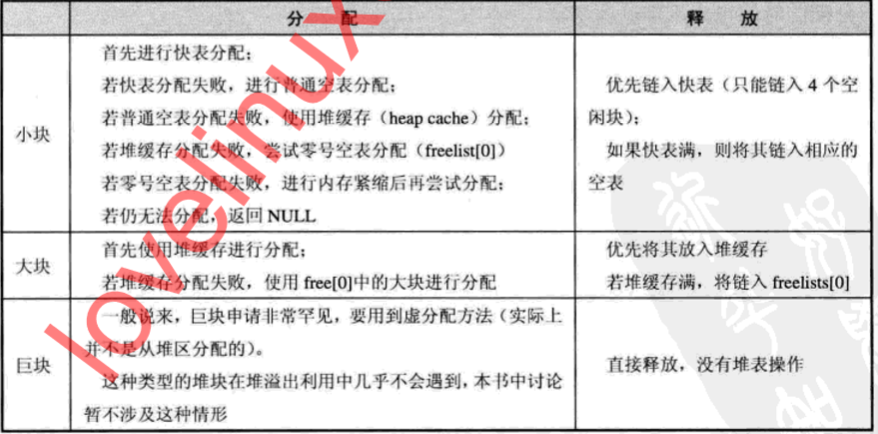
3).内存块的大小
小块(小于1kb)分配方式:优先快表,其次空表非零元素(free[0]),然后堆缓存,最后空表零元素
大块(大于1kb小于512kb)分配方式:优先堆缓存,其次空表零元素
巨快(大于512kb)分配方式:虚分配
4.堆块申请使用释放
1).堆块分配
堆块分配可以分为三类:快表分配、普通空表分配和零号空表(free[0]分配)。
从快表中分配堆块比较简单,包括寻找到大小匹配的空闲堆块、将其状态修改为占用态、把它从堆表中"卸下"、最后返回一个指向堆块快身的指针给程序使用。
普通空表分配时首先寻找最优的空闲块分配,若失败,则寻找次优的空闲块分配,即最小的能满足要求的空闲块.零号空表中按照大小升序链着大小不同的空闲块,故在分配时先从free[0]反向查找最后一个块(即最大块),看能否满足要求,如果满足要求,再正向搜索最小能满足要求的空闲堆块进行分配。
当空表中无法找到匹配的"最优"堆块时,一个稍大些的块会被用于分配,这种次优分配发生时,会先从大块中按请求的大小精确地"割"出一块进行分配,然后给剩下的部分重新标注块首,链入空表。由于快表只有在精确匹配才会分配,所以不存在上述现象。
2).堆块释放
释放堆块的操作包括将堆块状态改为空闲,链入相应的堆表。所有的释放块都链入堆表的末尾,分配的时候也先从堆表末尾拿。
另外需要强调,快表最多只有4项。
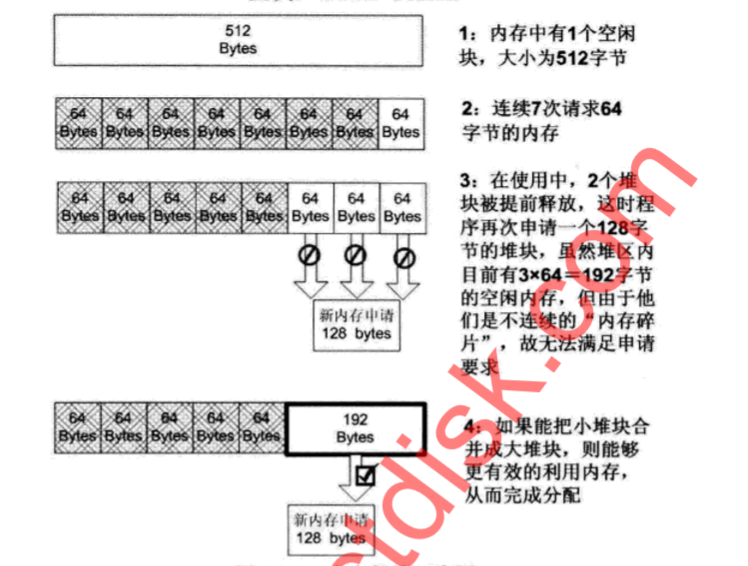
3).堆块合并
当堆管理系统发现两个空闲堆块相邻时,就会进行堆块合并操作,包括,将堆块从链表中卸下、合并、调整新堆块块首信息、重新链入空表。
堆区还有一种操作叫内存紧缩,类似磁盘碎片整理,会对整个堆进行调整,尽量合并可用碎片。
5.堆的调试
#include <windows.h>
main()
{
HLOCAL h1,h2,h3,h4,h5,h6;
HANDLE hp;
hp = HeapCreate(0,0x1000,0x10000);
__asm int 3
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,3);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,5);
h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,6);
h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,19);
h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);
//free block and prevent coaleses
HeapFree(hp,0,h1); //free to freelist[2]
HeapFree(hp,0,h3); //free to freelist[2]
HeapFree(hp,0,h5); //free to freelist[4]
HeapFree(hp,0,h4); //coalese h3,h4,h5,link the large block to freelist[8]
return 0;
}
太懒了,调试参考:《0Day安全》之堆溢出
6.堆溢出利用
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块。
不难发现,堆溢出漏洞发生的基本前提是
- 程序向堆上写入数据。
- 写入的数据大小没有被良好地控制。
堆溢出是一种特定的缓冲区溢出(还有栈溢出, bss 段溢出等)。但是其与栈溢出所不同的是,堆上并不存在返回地址等可以让攻击者直接控制执行流程的数据,因此我们一般无法直接通过堆溢出来控制 EIP 。
利用堆溢出策略:
1.覆盖与其物理相邻的下一个 chunk 的内容。
2.利用堆中的机制(如 unlink 等 )来实现任意地址写入( Write-Anything-Anywhere)或控制堆块中的内容等效果,从而来控制程序的执行流。
(在程序的执行过程中,我们称由 malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构体来表示。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。)
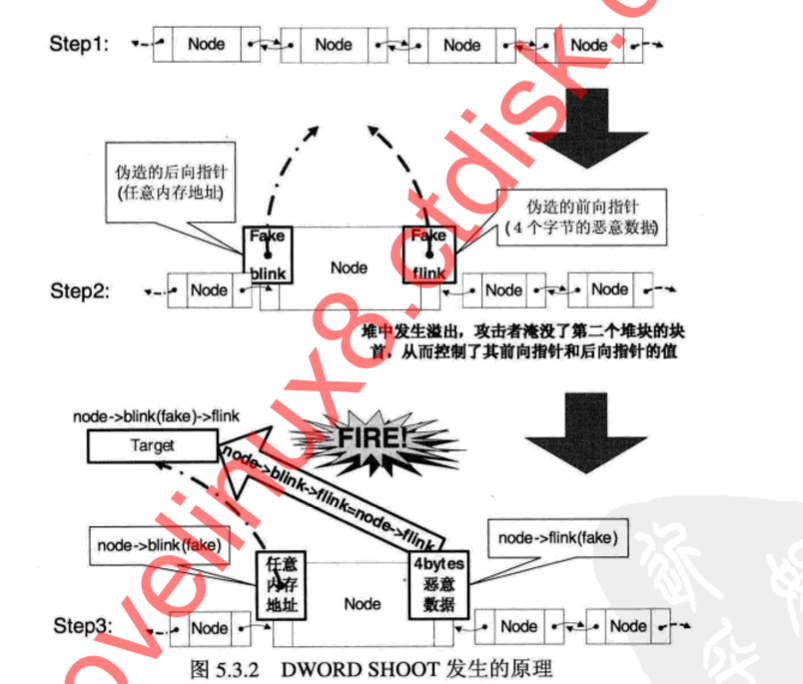
7.DWORD SHOOT
堆溢出利用的精髓是用精心构造的数据去溢出下一个块的块首,改写块首中的前向指针和后向指针,这种能够向内存任意位置写入任意数据的机会叫DWORD SHOOT。
将一个结点从双向链表卸下如下:
int remove (ListNode * node)
{
node ->blink ->flink = node ->flink;
node ->flink ->blink = node ->blink;
return 0;
}
8.Off-By-One
off-by-one 是指单字节缓冲区溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,当然也不排除写入的 size 正好就只多了一个字节的情况。其中边界验证不严通常包括
- 使用循环语句向堆块中写入数据时,循环的次数设置错误(这在 C 语言初学者中很常见)导致多写入了一个字节。
- 字符串操作不合适
一般来说,单字节溢出被认为是难以利用的,但是因为 Linux 的堆管理机制 ptmalloc 验证的松散性,基于Linux堆的 off-by-one 漏洞利用起来并不复杂,并且威力强大。
int my_gets(char *ptr,int size)
{
int i;
for(i=0;i<=size;i++)
{
ptr[i]=getchar();
}
return i;
}
int main()
{
void *chunk1,*chunk2;
chunk1=malloc(16);
chunk2=malloc(16);
puts("Get Input:");
my_gets(chunk1,16);
return 0;
}数据发生了溢出覆盖到了下一个堆块的 prev_size 域,具体可gdb调试分析。
9.后记
常见的危险函数如下
- 输入
- gets,直接读取一行,忽略
'\x00' - scanf
- vscanf
- gets,直接读取一行,忽略
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到
'\x00'停止 - strcat,字符串拼接,遇到
'\x00'停止 - bcopy
- strcpy,字符串复制,遇到
一个常见的误区是malloc的参数等于实际分配堆块的大小,但是事实上 ptmalloc 分配出来的大小是对齐的。这个长度一般是字长的2倍,比如32位系统是8个字节,64位系统是16个字节。但是对于不大于2倍字长的请求,malloc会直接返回2倍字长的块也就是最小chunk,比如64位系统执行malloc(0)会返回用户区域为16字节的块。















 3142
3142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









