






1,万能表dual,由oracle自己维护
2,Oracle多表查询中的重要知识点:
左联接的缩写(下面是右联结)
SELECT * FROM emp t1,dept t2 WHERE t1.deptno(+) =t2.deptno;--有加号的一边是从表,这个表示右外连接!
全外连接(full,左右两边都有空的每一行值都会查出来!)
SELECT * FROM emp t1 FULL OUTER JOIN dept t2 ON t1.deptno =t2.deptno;
自查询(将自己分成两个表,查员工和员工上司)
SELECT * FROM emp t1, emp t2 WHERE t1.mgr=t2.empno;(隐式内链接)
SELECT * FROM emp t1 ,emp t2 WHERE t1.mgr=t2.empno(+);(左联接)
子查询中注意(子查询语句不能为空,只要子语句为空不管怎样 整个语句的结果都为空)
SELECT * FROM emp WHERE job !=(SELECT job FROM emp WHERE ename='Rose');
子查询的位置:可以放在主查询的where、select、having、from的后面。不可以放在主查询的group by后面。
最后,子查询出来的表也可以当作虚拟表来再次查询!
条件的使用顺序!(where--> group by --> having (having必须依赖group by使用)--> order by)
SELECT deptno,MAX(sal) FROM emp WHERE deptno IS NOT NULL GROUP BY deptno HAVING avg(sal)>2000 ORDER BY deptno DESC;
3,伪列:(根据rownum查询时候,不能rownum>=什么,它是查询的时候自然生成的【故不会随order by而改变顺序】,且从0开始往上加所以不能:rownum>=什么)
例:查询第四到六rownum值时
SELECT * FROM (SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM<=6) t1 WHERE r>=4;
--分页查询: 每页显示3条,当前第二页
pageNum=2;
pageSize=3;
firstIndex=(pageNum-1)pageSize
maxCount=pageSize;
mysql中分页:
SELECT * FROM emp LIMIT firstIndex,maxCount;
SELECT * FROM emp LIMIT 1,2;
oracle中分页:
pageNum=2;
pageSize=3;
StartRownum =(pageNum-1)*pageSize+1;
endRowNum=pageNum*pageSize;
SELECT * FROM (SELECT ROWNUM r,t.* FROM emp t WHERE ROWNUM<=StartRownum) t1 WHERE t1.r>=endRowNum;
伪列:ROWID的作用
这里列举两个常见的应用:
?I,去除重复数据。(因为它是插入数据时候就有的数据,当两条数据相同时候,他们的唯一标识就有且只有rowid了,所以可以通过以下方法去重复)--面试题—了解
--剔除重复数据
SELECT * FROM TEST WHERE ROWID NOT in(SELECT MIN(ROWID) FROM TEST GROUP BY NAME);
?II,在plsql Developer中,加上rowid可以更改数据。
3,如何避免笛卡儿积
在 WHERE 加入有效的连接条件。
4,如何解决高水位带来的查询效率问题呢?
I.将表数据备份出来,摧毁表再重建(truncate table),然后再将数据导回来。(释放空间)
II.收缩表,整理碎片,可使用变更表的语句:alter table 表名 move(不是放空间)rowid发生了变化。
5,索引:
作用:提升查询效率,提升服务器的i/o性能(减少了查询的次数)!
如果建立索引的时候,没有指定表空间,那么默认索引会存储在哪个表空间.会存储在所属用户默认的表空间
自动创建索引 非唯一,加速查询
生产环境下一般要将索引单独指定表空间(不要设置参数)。
create index idx_emp_ename on EMP (ename) tablespace USERS;
索引的创建场景!
l下列情况不要创建索引:
n表很小
n列不经常作为连接条件或出现在WHERE子句中
n表经常频繁更新(看需求,如果表经常不断的再更新,Oracle会频繁的重新改动索引,反 而降低了数据库性能。但如系统日志历史表,就必须增加索引,效率超高)
面试题:
1. 索引的作用是什么?
主要是提高查询效率,减少磁盘的读写,从而提高数据库性能。
2. 创建索引一定能提高查询速度么?
未必!得看你创建的索引的合理性。
3. 索引创建的越多越好么?
不是!索引也是需要占用存储空间的,过多的索引不但不会加速查询速度,反而还会降低效率。
6,plsql编程
引用型变量: v_ename emp.ename%TYPE;表的某个列
记录型变量: v_emp emp%ROWTYPE;表的一行的每一列( SELECT * INTO v_emp FROM emp WHERE empno=7839;)
流程控制:1,if判断:
判断emp表中记录是否超过20条,,10-20之间,10以下打印一句
| --判断emp表中记录是否超过20条,,10-20之间,10以下打印一句 DECLARE --用来存储数量 v_count NUMBER; BEGIN --查询数量赋值 SELECT COUNT(1) INTO v_count FROM emp ; --判断 IF v_count>20 THEN dbms_output.put_line('记录数超过20条:'||v_count); ELSIF v_count BETWEEN 10 AND 20 THEN dbms_output.put_line('记录数在10到20条之间:'||v_count); ELSE dbms_output.put_line('记录数不足10条:'||v_count); END IF; END; |
2,LOOP循环
打印数字1-
| --打印数字1-10 DECLARE --声明一个变量 v_num NUMBER :=1; BEGIN --循环并打印 LOOP EXIT WHEN v_num>10; --退出循环条件 dbms_output.put_line(v_num); --递增 --v_num++;--不支持 v_num :=v_num+1; END LOOP; END; |
7,游标:
从某个表中按照某种条件查出值,作为游标,在操作时候,打开游标 将取出的游标中的值 放进你声明的变量中,加一个退出条件,将它遍历放入!结果:变量可以可以得到我们所注入的一个结果集!
使用游标查询并打印某部门的员工的姓名和薪资,部门编号为运行时手动输入。
| -- Created on 2015/5/5 by CLARK ---查询10号部门的员工的姓名和薪资 declare --定义游标--带参数的游标:需要定一个形式参数 CURSOR c_emp(v_deptno emp.deptno%TYPE) IS SELECT ename,sal FROM emp WHERE deptno=v_deptno ;
--声明变量 v_ename emp.ename%TYPE; v_sal emp.sal%TYPE;
BEGIN --用 --打开游标 OPEN c_emp(10); --循环fetch LOOP --取出数据 FETCH c_emp INTO v_ename,v_sal; --退出条件 EXIT WHEN c_emp%NOTFOUND; --打印--写任何的逻辑 dbms_output.put_line('姓名:'||v_ename||',薪资:'||v_sal); END LOOP; --关闭 CLOSE c_emp; end;
--使用游标查询并打印某部门的员工的姓名和薪资,部门编号为运行时手动输入。 DECLARE --声明一个带参数的游标 CURSOR C_EMP(v_deptno emp.deptno%TYPE) IS SELECT * FROM EMP WHERE deptno=v_deptno; --记录型变量 v_emp emp%ROWTYPE;
BEGIN --打开游标,执行查询 --打开游标的时候需要传入参数 OPEN C_EMP(20); --使用游标,循环取值 LOOP --获取游标的值放入变量的时候,必须要into前后要对应(数量和类型) FETCH C_EMP INTO v_emp; EXIT WHEN C_EMP%NOTFOUND; --输出打印 DBMS_OUTPUT.PUT_LINE('员工的姓名:' || v_emp.ename || ',员工的工资' || v_emp.sal); END LOOP;
CLOSE c_emp ;--关闭游标,释放资源 END; |
8,存储过程:
作用:
为了一个特定的业务功能,会向数据库进行多次连接关闭(连接和关闭是很耗费资源)
业务放到PLSQL中:应用程序中只需要调用PLSQL就可以做到连接关闭一次数据库就可以实现我们的业务,可以大大提高效率.
java是不能直接调用plsql的,但可以通过存储过程这些对象来调用。
存储过程的调用方法:
Pl/sql调用:申明输入数据和输出数据类型,以及输入数据的传参
再打印你想要得到的值
Command窗口执行:打开服务 set serveroutput on;然后exec P_hello存储名(参数)(只有输入参数时可以,有输出的时候没有成功,方法此时用上面的)
Java程序调用:没试过!
【示例】
输入员工号查询某个员工(7839号员工)信息,要求,将薪水作为返回值输出,给调用的程序使用。
| ----输入员工号查询某个员工(7839号(老大)员工)信息,要求,将薪水作为返回值输出,给调用的程序使用。 CREATE OR REPLACE PROCEDURE p_queryempsal_out( i_empno IN emp.empno%TYPE,o_sal OUT emp.sal%TYPE) AS BEGIN --赋值:将薪水的值赋给输出的参数o_sal SELECT sal INTO o_sal FROM emp WHERE empno=i_empno;
END;
|
调用(使用plsql程序调用):
|
DECLARE --输入参数值 v_empno emp.empno%TYPE:=7839; --声明一个变量来接收输出参数 v_sal emp.sal%TYPE;
BEGIN
p_queryempsal_out(v_empno,v_sal);--第二个参数是输出的参数,必须有变量来接收!! --当上面的语句执行之后,v_sal就有值了。
dbms_output.put_line('员工编号为:'||v_empno||'的薪资为:'||v_sal); END; / |
注意:调用的时候,参数要与定义的参数的顺序和类型一致
9,触发器:
触发器就是在执行某个操作(增删改)的时候触发一个动作(一段程序)。
触发器分类:
| l 语句级触发器(表级触发器) 在指定的操作语句操作之前或之后执行一次,不管这条语句影响了多少行 。 l 行级触发器(FOR EACH ROW) 触发语句作用的每一条记录都被触发。在行级触发器中使用old和new伪记录变量, 识别值的状态。 |
语句级触发器和行级触发器区别:
1. 在语法上,行级触发器就多了一句话:for each row
2. 在表现上,行级触发器,在每一行的数据进行操作的时候都会触发。但语句级触发器,对表的一个完整操作才会触发一次。
简单的说:行级触发器,是对应行操作的;语句级触发器,是对应表操作的。
但是要注意:触发器会引起锁,降低效率!使用时要慎重。如无必要,尽量不要使用触发器。
行级触发器会引发行级锁(锁行数据)
语句级触发器可能会引起表级锁(锁表)
10,Sql优化:
【知识点】
SQL优化:(where条件特别多的情况下,就有效果了)
where条件的解析顺序:从右到左
对于and,应该尽量把假的放到右边。
对于or,应该尽量把真的放到右边。
有where子查询时,子查询放在最前;(where从右向左执行,故右边的条件先执行后再子查询可以缩小查询范围)
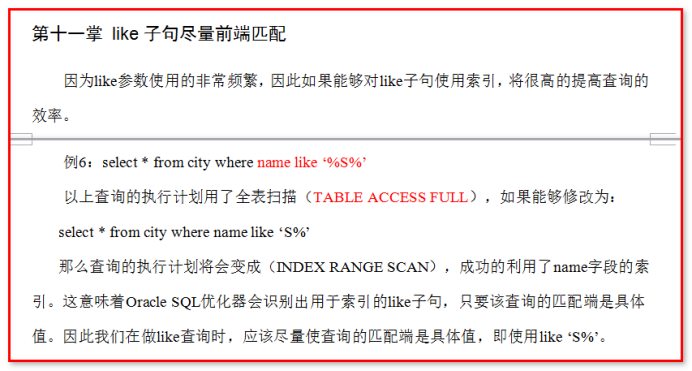
到底是使用upper还是使用lower呢?
一般根据需求来选择的。
如果将函数放到字段上,会每行的该字段都会转换,效率低一些。--sql优化
因此,一般情况下,建议将转换函数放到固定值上面(好处之一就是只需要转换一次,还有一个好处,就是你不知道用户到底输入的是大写还是小写还是混合写,更适应业务)。
能用where就用where别用having!!
使用having子句过滤,是先分组,再过滤,注意:分组的时候是全表扫描的,效率较低。
使用where子句过滤,是先过滤再分组,注意:分组的时候仅需要扫描部分数据,效率较高。
在查两个表时候,如果有相同字段,咱么要加上表前缀,这样可以提升性能!
即是:select语句中尽量避免使用*(执行时会把*依次转换为列名);
查两张以上表时,把记录少的放在右边;




用索引提高效率(代价是:索引需要空间,而且定期重构索引很有必要:ALTER INDEX<INDEXNAME> REBUILD<TABLESPACENAME);
先介绍下索引的原理,方便接下来对索引的优化的理解:
通过索引找到rowid,然后通过rowid访问表。但如果查询的列包括在index中,将不在执行第二部操作,因为检索数据保存在索引中,单单访问索引就可以完全满足查询要求。
前提提要:LODGING列有唯一索引;MANAGER列上有非唯一性索引。
索引范围查询(INDEX RANGE SACEN):
适用于两种情况:
1)基于一个范围的查询:
SELECT LODGING FROM LODGING WHERE LODGING LIKE 'M%'
(where字句条件包括一系列的值,oracle将通过索引范围查询方式查询LODGING_PK)
2) 基于非唯一性索引的检索:
SELECT LODGING FROM LODGING WHERE MANAGER = 'LI';
(此查询分两步:LODGING$MANAGER的索引范围查询得到所有符合条件记录的rowid,然后通过rowid访问表得到LODGING列的值。该索引为非唯一性索引,数据库不能对它执行索引唯一扫描)
where字句中,如果索引列所对应的值的第一个字符由通配符开始,索引将不被采用,而会全表扫描,如 SELECT..... WHERE MANAGER LIKE '%LI'
















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









