






目的:爬取下厨房分类中的所有菜谱
结果呈现:1)屏幕显示 2)文件夹中显示
【注:竟然........被反爬虫了......】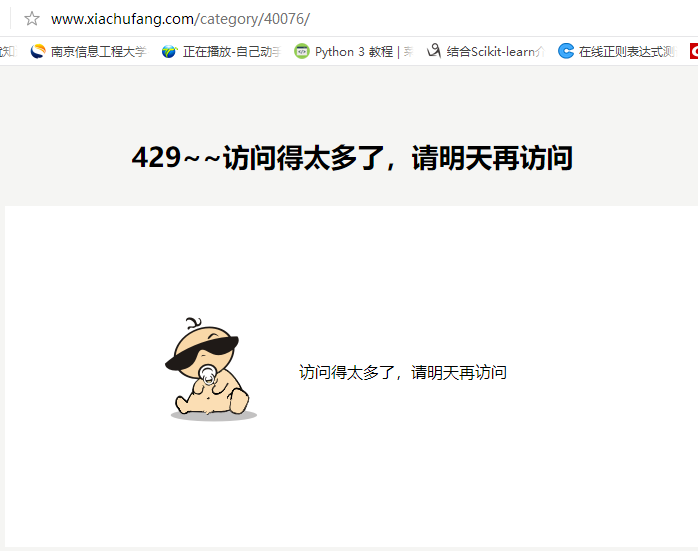
【我就是安安静静的爬个菜谱,,,还遇到这种事???】
【对不起,原谅我的无能,,,让我们一起静静的等一天吧,,,】
【???以为我真的会等一天???不可能!时间就是金钱啊!】------>武器出场“IP代理”
【PS:本人发现ip代理有免费的,也有收费的,好吧,我又一次因为抠,开始了我新的学习---->“代理的使用”---(我单独写了一章节,因为我真的是一点都没有接触过,从0开始学的)】
下厨房首页:http://www.xiachufang.com
国内高匿代理IP首页:https://www.xicidaili.com/nn/ 【注:一般爬取首页的IP地址就足够使用】
#下面为本实例的爬虫代码,若有问题可以给我留言,或者有更好的解决方法也可以私信我~
import random
import threading
import requests
from bs4 import BeautifulSoup
import os
base_url = 'http://www.xiachufang.com'
def get_proxy(total_page): #得到前20页的ip代理,并对其验证
proxy_list = []
for page in range(1,total_page):
url='http://www.xicidaili.com/nn/{}'.format(page)
headers={'user-agent':'Mozilla/5.0'}
proxies = { # 随便在网上找的一个高匿代理,以为这个地址爬多了,也被反爬了......
'http': 'http://' + '124.235.135.210:80',
'https': 'https://' + '124.235.135.210:80',
}
r=requests.get(url,headers=headers,proxies=proxies)
#print('正在爬取ip代理--->{}'.format(url))
soup=BeautifulSoup(r.text,'html.parser')
trs = soup.find('table', id='ip_list').find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
ip = tds[1].text.strip()
port = tds[2].text.strip()
proxy = ip + ':' + port
proxy_list.append(proxy)
#多线程检测
threads = []
for proxy in proxy_list:
thread = threading.Thread(target=thread_test_proxy, args=(proxy,))
threads.append(thread)
thread.start()
for thread in threads: # 阻塞主进程,等待所有子线程结束
thread.join()
def thread_test_proxy(proxy): #添加线程模式
url = 'http://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0', }
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
try:
r=requests.get(url,headers=headers,proxies=proxies,timeout=2)
if r.status_code == 200:
print('{}该代理IP可用'.format(proxy))
thread_write_proxy(proxy)
#else:
#print('{}该代理IP不可用'.format(proxy))
except:
#print('{}该代理IP无效'.format(proxy))
pass
def thread_write_proxy(proxy):
with open('useful_ip_proxy.txt','a+')as f:
f.write(proxy+'\n')
f.close()
def get_page(url):
useful_ip_proxy = []
with open('useful_ip_proxy.txt', 'r')as f:
info = f.readlines()
for line in info:
res = line.split('\n')[0]
useful_ip_proxy.append(res)
f.close()
try:
proxy = random.choice(useful_ip_proxy)
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
r=requests.get(url,proxies=proxies,timeout=5)
r.raise_for_status()
#r.encoding=r.apparent_encoding
return r.text
except Exception as e:
proxy = random.choice(useful_ip_proxy)
proxies = {
'http': 'http://' + proxy,
'https': 'https://' + proxy
}
r = requests.get(url, proxies=proxies, timeout=5)
r.raise_for_status()
# r.encoding=r.apparent_encoding
return r.text
def get_cate(url): #得到所有的分类
cate_url=[]
cate_name=[]
html=get_page(url)
soup=BeautifulSoup(html,'html.parser')
all_div=soup.find_all('div',{'class':{'cates-list-all'}})
for div in all_div:
big_cate=div('h4')[0].text.strip()
all_a=div.find_all('a',{'target':{'_blank'}})
for a in all_a:
small_cate=a.text.strip()
cate=big_cate+'_'+small_cate
href=a['href']
cate_url.append(base_url+href)
cate_name.append(cate)
return cate_url,cate_name
def get_recipe_url(url): #得到每个类别里面至少5页的上面所有菜谱的网址
recipe_url=[]
for i in range(1,6):
try:
url_t=url+'?page='+str(i)
html=get_page(url_t)
soup=BeautifulSoup(html,'html.parser')
info=soup.find('div',{'class':{'normal-recipe-list'}})
all_p=info.find_all('p',{'class':{'name'}})
for p in all_p:
href=p('a')[0]['href']
url_t=base_url+href
recipe_url.append(url_t)
except:
continue
return recipe_url
def get_info(url,cate): #得到每道菜谱的详细信息
html=get_page(url)
soup=BeautifulSoup(html,'html.parser')
title=soup.find('h1',{'class':{'page-title'}}).text.strip() #菜名
try:
ratingValue=soup.find('span',{'itemprop':{'ratingValue'}}).text.strip() #评分
except:
ratingValue=''
div1=soup.find('div',{'class':{'cooked'}})
cooked=div1('span')[0].text.strip() #做过这道菜的人
name=soup.find('span',{'itemprop':{'name'}}).text.strip() #作者名称
yl=[] #用料
all_tr=soup.find_all('tr',{'itemprop':{'recipeIngredient'}})
for tr in all_tr:
yl_name=tr('td')[0].text.strip()
yl_unit=tr('td')[1].text.strip()
if not yl_unit:
yl_unit='适量'
yl.append(yl_name+':'+yl_unit)
steps=[]
all_li=soup.find_all('li',{'itemprop':{'recipeInstructions'}})
for li in all_li:
steps.append(li('p')[0].text.strip())
try:
tip=soup.find('div',{'class':{'tip'}}).text.strip() #小贴士
except:
tip=''
ratingValue=yes_or_no(ratingValue)
cooked=yes_or_no(cooked)
name=yes_or_no(name)
yl=yes_or_no(yl)
steps=yes_or_no(steps)
tip=yes_or_no(tip)
save_recipe(title,ratingValue,cooked,name,yl,steps,tip,cate)
print('{}--❤--{}--❤--爬取完成!'.format(cate,title))
def yes_or_no(item): #判断是不是空的
if not item:
item='无'
return item
def save_recipe(title,ratingValue,cooked,name,yl,steps,tip,cate): #保存菜谱信息
big_cate=cate.split('_')[0]
small_cate=cate.split('_')[1]
path='./'+big_cate+'/'
if not os.path.exists(path):
os.makedirs(path)
path_name=path+small_cate+'.txt'
with open(path_name,'a+',encoding='utf-8')as f:
f.write('菜名:'+title+'\n')
f.write('综合评分:'+ratingValue+'\n')
f.write('做过的人数:'+cooked+'\n')
f.write('这道菜的原作者:'+name+'\n')
f.write('用料:'+'\n')
for item_yl in yl:
f.write(item_yl+' ')
f.write('\n')
f.write('步骤:' + '\n')
for item_steps in steps:
f.write(item_steps+'\n')
f.write('注意点:'+tip+'\n')
f.write('(#^.^#)❤(#^.^#)❤(#^.^#)❤这道菜(#^.^#)❤(#^.^#)❤(#^.^#)❤完成啦~')
f.write('\n\n')
f.close()
if __name__ == '__main__':
print('正在爬取http://www.xicidaili.com/nn的前1页的ip代理')
get_proxy(2) # 1页
print('第1页ip代理爬取以及检验完成,并存入useful_ip_proxy.txt文件中')
start_url='http://www.xiachufang.com/category/'
cate_url, cate_name=get_cate(start_url)
for i in range(len(cate_url)):
print('开始爬取{}分类'.format(cate_name[i]))
recipe_url=get_recipe_url(cate_url[i])
for j in range(len(recipe_url)):
try:
get_info(recipe_url[j],cate_name[i])
except:
continue
(1)屏幕显示【部分截图】---->若你不想屏幕显示,就把上述代码中的print()语句注释掉

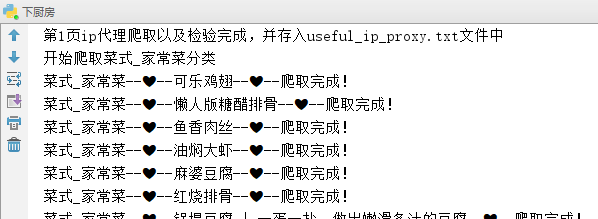
 ......【略】
......【略】
(2)文件夹显示
(2-1)生成的有效的ip代理
![]()
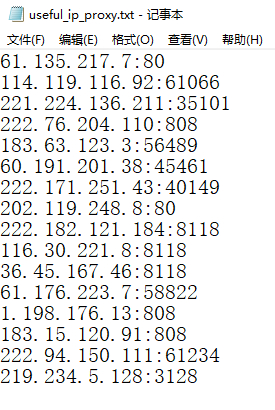
(2-2)生成的各种菜谱的文件夹【部分截图】
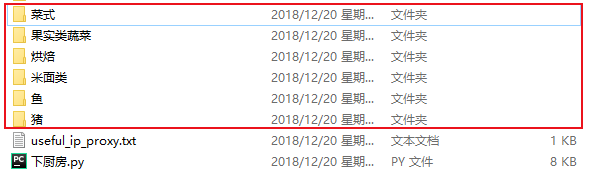
 ......【略】
......【略】
注:我就只是简单的爬虫,重点还是爬个菜谱,竟然被反爬虫?!这.......说出去都觉得丢脸......
But 幸亏的是自学 代理的使用 的知识解决了!【知识点见我的blog:https://my.oschina.net/pansy0425/blog/2990698 https://my.oschina.net/pansy0425/blog/2990702】
感悟:自己花时间去学习,去一点点的找知识,遇到的坑是真的多,但是遇到一个坑,就填一个坑~~~实在不行就蹦过去!!!٩(๑❛ᴗ❛๑)۶٩(๑❛ᴗ❛๑)۶٩(๑❛ᴗ❛๑)۶
注:反爬虫这块是很重要的!!!要进行知识总结!----->大型的bat公司都要求有反爬虫的经验!
今日鸡汤:在你做过最后一次尝试之前,永远别说自己失败了。而在你成功之前,永远别说这是你的最后一次尝试。
加油ヾ(◍°∇°◍)ノ゙

















 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









