






模块须知:
1、首次导入模块,发生三件事:1)创建一个模块的名称空间
2)执行模块对应的文件,将产生的名字存放在1)中的名称空间
3)在当前执行文件中拿到一个模块名,该模块名指向1)的名称空间
2、模块的查找顺序:1)内存中已经加载的模块
2)内置模块
3)sys.path路径中包含的模块 【注:sys.path的第一个路径为当前执行文件所在的文件夹】
一、logging模块 【日志模块】===》爬虫需要(需要记录哪边错误,且不中断)
【注:下面都是了解!!!其实日志只要把它写到一个模块,以后每次使用导入该模块即可!!!】
【So:定义一个mylogger.py 以后直接把它当成模块使用!!!】
调用:import logging
1、日志分为5个级别:
| 日志分类 | 调用形式 | 含义 | 日志级别(用数字表示等级) |
| debug | logging.debug("debug......") | 调试信息 | 10 |
| info | logging.info("info......") | 程序正常运行级别的信息 | 20 |
| warning | logging.warning("warning......") | 警告,可以忽略 | 30 |
| error | logging.error("error......") | 错误 | 40 |
| critical | logging.critical("critical......") | 崩溃(严重) | 50 |
一般默认的日志级别为30,所以一般只打印:warning、error、critical
import logging
logging.debug('debug......')
logging.info('info......')
logging.warning('warning......')
logging.error('error......')
logging.critical('critical......')
"""
结果显示: #只打印warning、error、critical 【因为默认的日志级别为30】
WARNING:root:warning......
ERROR:root:error......
CRITICAL:root:critical......
"""
#切默认输出结果为:日志级别:日志名:自己输入的信息
2、需求:针对默认的日志输入,需要建立一些新的设置
需求:(1)自己设置日志级别 (2)自己设置日志格式 (3)日志打印到屏幕(默认)且保存到文件(自己设置)
使用:logging.basicConfig(**kwargs) 进行日志参数的设置
参数:(1)filename:指定文件的路径用于存放日志
(2)filemode:文件打开模式,可以为'a','w',默认是'a'
(3)日志显示格式:一般情况下为:
(4)datafmt:日志时间格式
(5)level:设置日志等级
(6)stream:一半为sys.stdout,表示往屏幕输出
注意点:(1)filename和stream不能同时设置 【问题!!!需要考虑!!!】
(2)logging.basicConfig(**kwargs)中没有设置编码encoding,日志文件默认编码是'gbk格式',但是pycharm使用'utf-8'编码
3、日志的小例子使用(自己设置logging.basicConfig(**kwargs))
import logging
logging.basicConfig(filename='access.log',format='%(asctime)s-%(name)s-%(levelname)s-%(module)s:%(message)s',datefmt='%Y-%m-%d %H:%M%S %p',level=10)
logging.debug('调试正常')
logging.info('正常运行')
logging.warning('警告')
logging.error('出错')
logging.critical('严重崩溃')
#此时出现文件夹:access.log,里面内容如下:
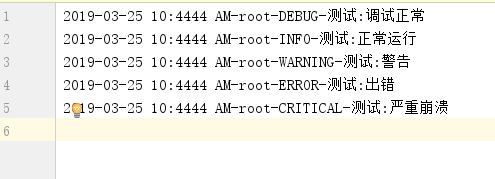 【但是要把编码设置为:‘gbk’,才可以查看】
【但是要把编码设置为:‘gbk’,才可以查看】
4、logging模块中的四类对象 【自己敲一遍,知道关系即可】
四类对象:logger filter handler formatter
假设现在整个日志模块的布局为: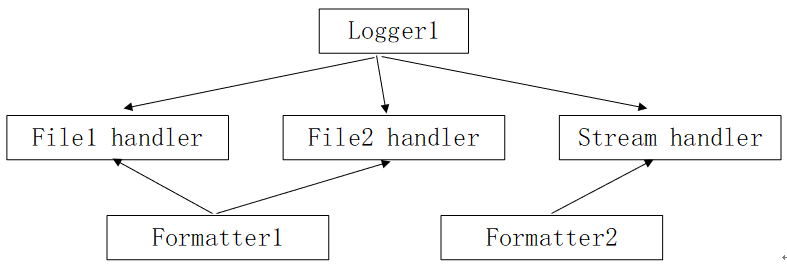
【建立日志:有两个输出到文件,有一个输出到屏幕;其中两个文件日志格式用formatter1,屏幕日志格式用formatter2】
(1)logger:负责生产日志
import logging
logger1=logging.getLogger('***')
注:***是日志的名称,自己设置
注:此时logger1有debug、info、warning、error、critical方法,可以用logger1产生日志
(2)filter:过滤日志(不常用)
(3)handler:控制日子打印到文件or终端
logging.Filehandler(filename,mode='a',encoding) #打印到文件【可以自己指定编码,指定文utf-8】
logging.Streamhandler() #打印到屏幕终端
fh1=logging.FileHandler('a1.log','a',encoding='utf-8') #打印到文件
fh2=logging.FileHandler('a2.log','a',encoding='utf-8') #打印到文件
sh=logging.StreamHandler() #打印到屏幕
(4)formatter:控制日志的格式 logging.Formatter(fmt,datefmt) 其中fmt是日志格式,datefmt是日期格式
formatter1=logging.Formatter(fmt='%(asctime)s-%(name)s-%(levelname)s-%(module)s:%(message)s',datefmt='%Y-%m-%d %H:%M:%S %p') formatter2=logging.Formatter(fmt='%(asctime)s-%(message)s')
根据上述日志布局,建立关系
#关系1:logger1把日志存储/显示到file1,file2和stream
【为logger对象绑定handler,利用addHandler()】
logger1.addHandler(fh1) logger1.addHandler(fh2) logger1.addHandler(sh)
#关系2:为handler绑定日志格式
【为logger对象绑定日志格式,利用setFormatter()】
fh1.setFormatter(formatter1) fh2.setFormatter(formatter1) sh.setFormatter(formatter2)
注:日志级别【涉及到两层关系】(第一层、第二层、第三层只是日志格式)
注:日志格式:两层关卡,必须都要通过,日志才能正常记录
logger1.setLevel(10) #第一层 fh1.setLevel(10) #第二层 fh2.setLevel(10) #第二层 sh.setLevel(10) #第二层
如此时:输入:logger1.debug('调试信息')
则:a1.log和a2.log文件formatter1格式:

终端显示formatter2格式:
5、通过字典导入配置 【重点!!!这边的my_logging.py就是以后我需要导入的模块】
分为两块:(1)my_logging.py【日志配置文件,以后直接复制粘贴】===》当模块使用
(2)test.py 在其中导入my_logging.py文件,然后直接使用
【!!!这个流程就是以后的流程!!!】
(1)my_logging.py文件 【!!!以后直接把它当做模块导入!!!】
import logging import logging.config #定义三种日志格式的输出 standard_format = '[%(asctime)s][%(threadName)s:%(thread)s][task_id:%(name)s][%(filename)s:%(lineno)d][%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' #定义日志文件的路径 LOG_PATH=r'access.log' # log配置字典 ---->日后要是用的话,直接照着这个字典里面填写信息即可。 #重要的就是 'formatters':{} 'handlers':{} 'loggers':{} LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, 'id_simple':{ 'format':id_simple_format }, }, #上述描述的三种日志格式 'filters': {}, #过滤,不重要 'handlers': { 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' #终端打印格式:选择simple--->简洁 },#打印到终端的日志 'default': { 'level': 'INFO', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', #文件打印格式:选择standard--->规范 'filename': LOG_PATH, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5,#针对:若access_psy.log满了,则每5M就切分一个,会出现:access_psy.log1 access_psy.log2 ......access_psy.log5用于存放之前的日志【老日志】 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 },#打印到文件的日志,收集info及以上的日志 }, #控制日志写到:文件or终端 【所以有两种】 'loggers': { #logging.getLogger(name)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': False, # True-->向上(更高level的logger)传递。通常设置为False }, #注:''是日志名,可以自己修改,一般设置为空,自己调用的时候设置名称 }#负责产生日志 } def load_my_logging_cfg(): #加载日志的配置 logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例,这里面的名字,自己设置 logger.info('It works!') # 记录该文件的运行状态
(2)test.py文件 在test.py文件中想调用这个设置好的log配置
import time
import logging
import my_logging # 导入自定义的logging配置
logger = logging.getLogger('psy') # 生成logger实例
def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文测试开始。。。")
for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文测试结束。。。")
if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加载自定义logging配置
demo()
此时右键run test.py
文件access.log显示:
终端屏幕显示: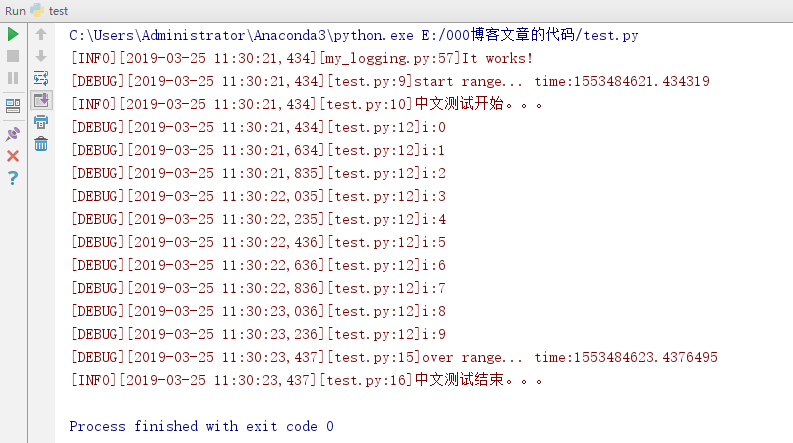
【注:这个要理解!!!!!!以后直接调用my_logging.py,把它当成模块导入即可!!!!】
二、json模块(序列化,反序列化)
序列化:内存中的数据结构====》转成一种中间格式====》存到文件中
反序列化:文件====》读取中间格式(字符串)====》eval转成内存中的数据格式
1、反序列化
之前:eval() 就是去掉两边引号【单引号或双引号】
x='[1,2,3]'
print(eval(x)) #[1, 2, 3]
y="[1,2,3]"
print(eval(y)) #[1, 2, 3]
z="[1,true,false,null]"
print(eval(z)) #报错 因为:python中没有true,false,null
所以eval()反序列化有局限性,所以使用json()
现在反序列化:json.loads()
import json
x="[1,true,false,null]"
print(json.loads(x)) #[1, True, False, None]
2、序列化 json.dumps()
import json
dic={'name':'psy','age':18}
print(json.dumps(dic)) #{"age": 18, "name": "psy"}















 73
73











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









