






本文基于实验室已经搭建好的Hadoop平台而写,使用Python调用hdfs来操作HDFS
HdfsCLI官方文档:https://hdfscli.readthedocs.io/en/latest/
1.安装
pip install hdfs
2.配置
(1)使用hdfs这个用户登录到hdfs服务器,创建用户,并修改权限

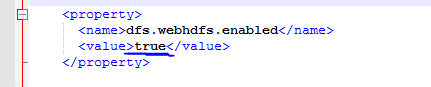
(2)集群中所有节点的hdfs-site.xml文件增加如下内容
(3)配置hosts文件:这个配置非常重要。
如果想在集群外的其他节点(此处可以理解为你自己的工作节点)通过WebHDFS REST API访问集群,需要配置hosts文件
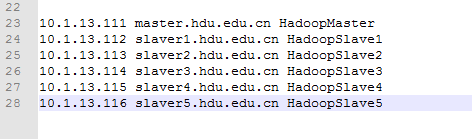
本人使用的是Windows7 64位系统,hosts文件在C:\Windows\System32\drivers\etc目录下。在hosts文件中配置集群中节点的ip和名称,如下:
此处如果不配置,读写操作都无法完成,会出现如下错误:
File "C:\Python27\lib\site-packages\hdfs\util.py", line 99, in __exit__
raise self._err # pylint: disable=raising-bad-type
requests.packages.urllib3.exceptions.NewConnectionError: <requests.packages.urllib3.connection.HTTPConnection object at 0x0000000003B3C400>: Failed to establish a new connection: [Errno 10060]
3.连接
from hdfs import InsecureClient
hdfs_client = InsecureClient('http://10.1.13.111:50070', user='liulin')
print hdfs_client.list('.') # 列出当前目录下的所有文件
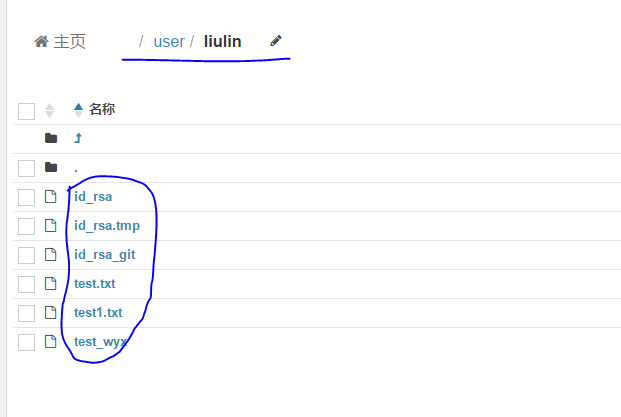
通过hue可以看到目前user/liulin下的文件情况如下:
程序运行之后的结果如下:

4.读文件:read()方法提供了一个类似于文件的接口,用于从HDFS读取文件。
它必须在with上下文管理器中使用。
(1)将文件加载到内存
# 将文件加载到内存
with client.read('test.txt') as reader:
data = reader.read()
print data
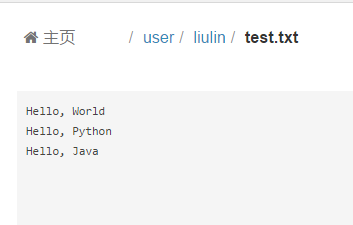
通过hue可以看到test.txt的内容如下:
程序运行之后的结果如下:
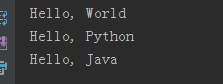
(2)对于json文件,可以直接反序列化
# 直接将json对象反序列化
with client.read('model.json', encoding='utf-8') as reader:
from json import load
model = load(reader)
print model
(3)如果设置了chunk_size这个参数,with上下文管理器将返回一个chunk_size 字节的生成器,
而不是返回一个类文件对象,除非同时也设置了delimiter参数。
# 流文件
with client.read('test.txt', chunk_size=8) as reader:
for chunk in reader:
print chunk
(4)类似的,如果设置了delimiter这个参数,with上下文管理器将返回一个生成器,该生成器遇到delimiter 就会生成数据。设置该参数的时候,必须同时设置encoding参数。
# 通过设置定界符来读取数据,必须与encoding参数同时使用
with client.read('test.txt', encoding='utf-8', delimiter='\n') as reader:
for line in reader:
print line
5.写文件:通过write()方法向HDFS写入文件,该方法返回一个可写的类文件对象
(1)创建一个新文件,并向文件中写入数据
# 向文件写入数据,会创建一个新的文件
data = '''
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
'''
with client.write('test_liulin.txt') as writer:
writer.write(data)
(2)通过设置append参数向一个已经存在的文件追加写入数据
# 通过设置append参数,向一个已经存在的文件追加写入数据
with client.write('test_liulin.txt', append=True) as writer:
writer.write('You succeed!')
(3)通过设置overwrite参数向一个已经存在的文件覆盖写入数据
# 写入文件的一部分, 可以用作文件
with client.read('test_liulin.txt', delimiter='\n', encoding='utf-8') as reader, \
client.write('test_liulin.txt', overwrite=True) as writer:
for line in reader:
print line
if line.find('is') != -1:
writer.write(line + '\n')
(4)向json文件写入数据
# 编写序列化的json对象
sample = {'university': 'HDU', "school": "computer"}
with client.write('sample.json', encoding='utf-8') as writer:
from json import dump
dump(sample, writer)
6.探索文件系统
所有的Client子类都公开了多种与HDFS交互的方法,大多数方法都是直接将WebHDFS的操作直接模块化。
(1)用content()方法检索文件或文件夹的内容摘要
# 检索文件或文件夹的内容摘要
content = client.content('test.txt')
print content

(2)列出一个目录中的所有文件
# 列出当前目录中所有的文件
file_names = client.list('.')
print file_names
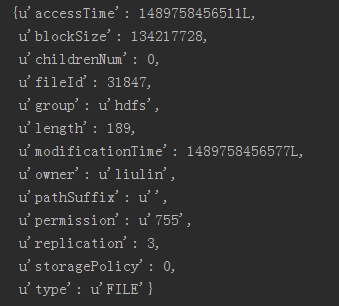
(3)检索一个文件或文件夹的状态
# 检索一个文件或文件夹的状态
from pprint import pprint
status = client.status('test_liulin.txt')
pprint(status)
(4)重命名:该方法也可以用于移动文件
# 给文件重命名
client.rename('test1.txt', 'test22.txt')
(5)删除文件
# 删除文件
client.delete('test_wyx')
(6)从HDFS下载文件到本地
# 从HDFS下载文件到本地:即当前这个文件所在的位置
client.download('test_liulin.txt', '.', n_threads=3)
(7)文件路径扩展:使用特殊的标记来标识路径,使用#LATEST 来标识给定文件夹中最后被修改的文件
# 给定文件夹中最后一个被修改的文件
with client.read('./#LATEST') as reader:
data = reader.read()
print data
注意:如果路径缺失,上面提到的大多数方法都会报HdfsError,推荐的方式是使用content()和status()方法来检查路径是否存在,并将strict参数设置False,若路径真的不存在,则返回None
还有一些高级应用及更详细的API参考资料请阅读官方文档……

















 2895
2895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









