






1.NLP常见任务
自动摘要 指代消解 机器翻译 词性标注
中文分词 主题识别 文本分类
2.NLP处理方法
传统:基于规则
现代:基于统计机器学习
HMM:隐马尔可夫模型
CRF:条件随机场
SVM:支持向量机
LDA:隐式狄利克雷分配,一种文档主题生成模型
CNN:卷积神经网络
RNN:循环神经网络
LSTM:长短期记忆,是一种时间递归神经网络
最终目的:词向量表示作为机器学习,特别是深度学习的输入和空间表示
3.词向量的离散表示方法
(1)基于独热编码(one-hot coding)的词袋表示法(bag of words)

from nltk import word_tokenize
# 语料库
corpus = 'John likes to watch movies Mary likes too John also likes to watch football games'
words = word_tokenize(corpus)
# print(words)
# 词典
corpus_dict = {}
index = 0
for word in set(words):
corpus_dict[word] = index
index += 1
print corpus_dict
# {'to': 4, 'football': 2, 'watch': 3, 'movies': 1, 'also': 0, 'games': 5, 'likes': 6, 'John': 7, 'Mary': 8, 'too': 9}
# bag of words表示
sentence = 'John likes to watch movies Mary likes too'
sentence_words = word_tokenize(sentence)
sentence_one_hot = [sentence_words.count(word) for word in corpus_dict.keys()]
print sentence_one_hot
# [1, 0, 1, 1, 0, 0, 2, 1, 1, 1] 文档的向量表示可以直接将各词的词向量表示加和
(2)基于词权重的文档向量表示法:TD-IDF

(3)Bi-gram和N-gram:考虑词的顺序,但词表迅速膨胀
语言模型如下:

总之,离散表示方法的问题:
(1)无法衡量词向量之间的关系
(2)词表维度随着语料库增长膨胀
(3)n-gram词序列随语料库膨胀更快
(4)数据稀疏问题
4.分布式表示
You shall know a word by the company it keeps
-- 用一个词附近的其他词来表示该词
(1)共现矩阵(Cocurrence matrix):共现矩阵主要用于主题模型, 如LSA(Latent Semantic Analysis)
局域窗中的Word - Word 共现矩阵可以挖掘语法和语义信息,局域窗的长度一般设为5~10,
且使用对称的窗函数,即左或右出现都算共现。
下面的例子,局域窗的长度为1
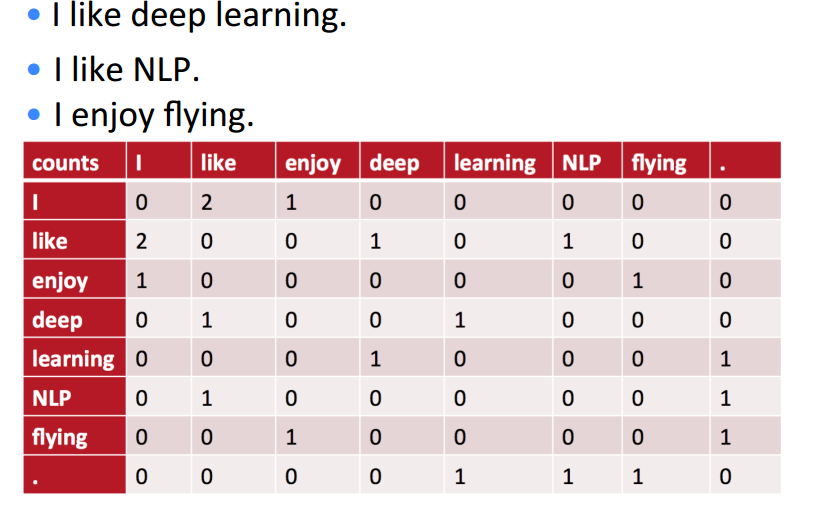
将共现矩阵行(列)作为词向量存在的问题:
1)向量维数随着词典大小线性增长
2)存储整个词典的空间消耗非常大
3)一些模型如文本分类模型会面临稀疏性问题
4)模型会欠稳定
针对维度高,稀疏性问题,最直接的想法就是降维用SVD(奇异值分解)对共现矩阵向量做降维

import numpy as np
words = ['I', 'like', 'enjoy', 'deep', 'learning', 'NLP', 'flying', '.']
X = np.array([[0, 2, 1, 0, 0, 0, 0, 0],
[2, 0, 0, 1, 0, 1, 0, 0],
[1, 0, 0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 1],
[0, 1, 0, 0, 0, 0, 0, 1],
[0, 0, 1, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 1, 1, 1, 0]])
U, S, Vh = np.linalg.svd(X, full_matrices=False)
想了解更多有关SVD的知识,可以看看下面这个连接:
http://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
SVD降维的问题:
1)计算量随语料库和词典增长膨胀太快, 对X(n,n)维的矩阵, 计算量O(n^3)
2)难以为词典中新加入的词分配词向量
3)与其他深度学习模型框架差异大
(2)NNLM(神经网络语言模型):效果不错,但计算量大


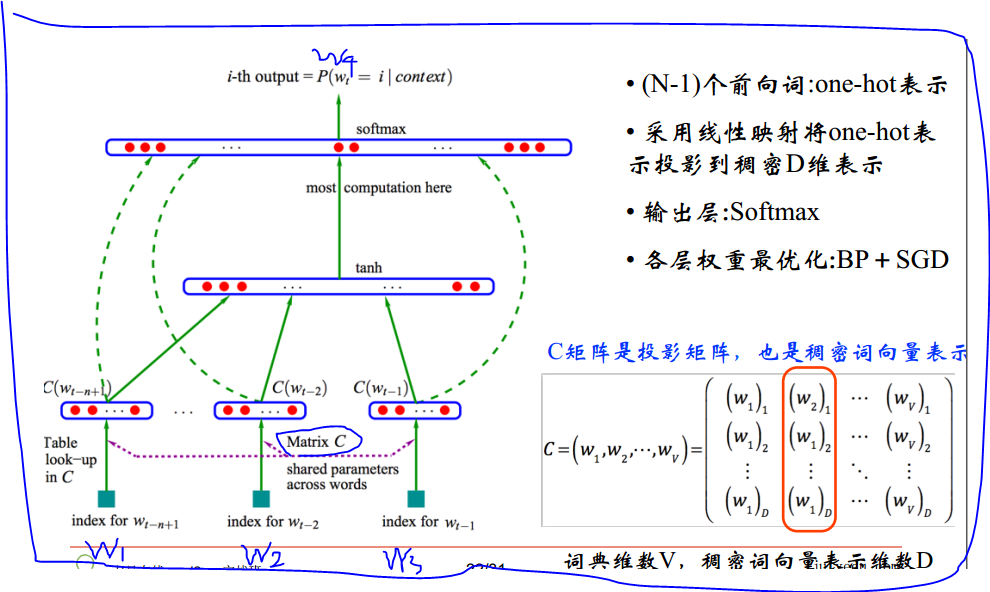
假设有一个语料库,从语料库里面以滑动窗口的形式取出若干个4-gram,我们要做的事情就是用前面的三个词来预测第四个词,即由w1、w2和w3去预测w4。这样的事情我们会做很多次,因为我们有很多这样的样本。这就相当于我们拿训练集来训练模型。
模型的输入是一个one-hot representation。假设词表的长度为10w,则w1、w2和w3是1 x 10w的行向量,其中只有一个元素值为1。
输入层之后是投影层。我们最终要做的事情就是要得到每个词的词向量,即稠密向量。在机器学习和深度学习中,惯用的做法是先初始化一组权重。在此,即初始化一组词向量,然后不断的去优化它。输入层和投影层之间有一个矩阵C,矩阵C是由词表中10w个词的列向量组成的,假设列向量的维度是300(工业界经验值),这样矩阵C就是300 x 10w的,这个C是随机初始化的,比如用高斯初始化。矩阵C与w1的矩阵相乘就是一个300维的列向量,这就相当于从矩阵里面取出来一列,因为w1是one-hot表示的,只有一个元素值为1。这就是投影层的来历。然后将这3个300维的向量拼接在一起,构成了一个900维的向量。
接下来是一个隐层,假设隐层的维度是500维。将900维与500维做一个全连接,全连接的权重为θ,θ的维度是900 x 500。最后的输出层我们选取了10w维,500维与最后的输出层之间有一个WX + b的操作,即500维与10w维之间做了一个全连接再加上偏移量。因为我们在输出层选取了10w,W则是10w x 500维,X就是隐藏层的500 x 1维, b是10w x 1维,则输出的结果是一个10w维的向量。那么由w1、w2和w3去预测w4 到底是10w个词里面的哪个词呢? 输出层的softmax是一个线性分类器, 它会给出这10w个词里面每个词的概率,有这些概率就构成了一个10w维的概率向量,这就是输出结果。我们希望w4所对应的概率是10w个概率里面最大的。这10w个概率之和为1。
在隐层里面是有一个激活函数的,在此取得是tanh,还可以取sigmoid或者reLU(Rectified Linear Unit )。
这个模型的输入样本是固定的,即input是已知的。一个input所对应的target也是已知的,target是一个10w维的向量,这个向量只有w4所对应的位置的元素为1,即概率为1,其他的元素值都为0。然后我们根据交叉熵(cross entropy)的损失函数去做优化,最小化这个交叉熵损失,此时的矩阵C就是我们真正要的词向量。
(3)Word2Vec
(1)CBOW模型(连续词袋 Continuous Bag-of-Word): 输入已知上下文,输出对下个单词的预测,比如:我喜欢学习机器学习,已知上文“我”、“喜欢”,下文“机器学习”,来预测“学习”。
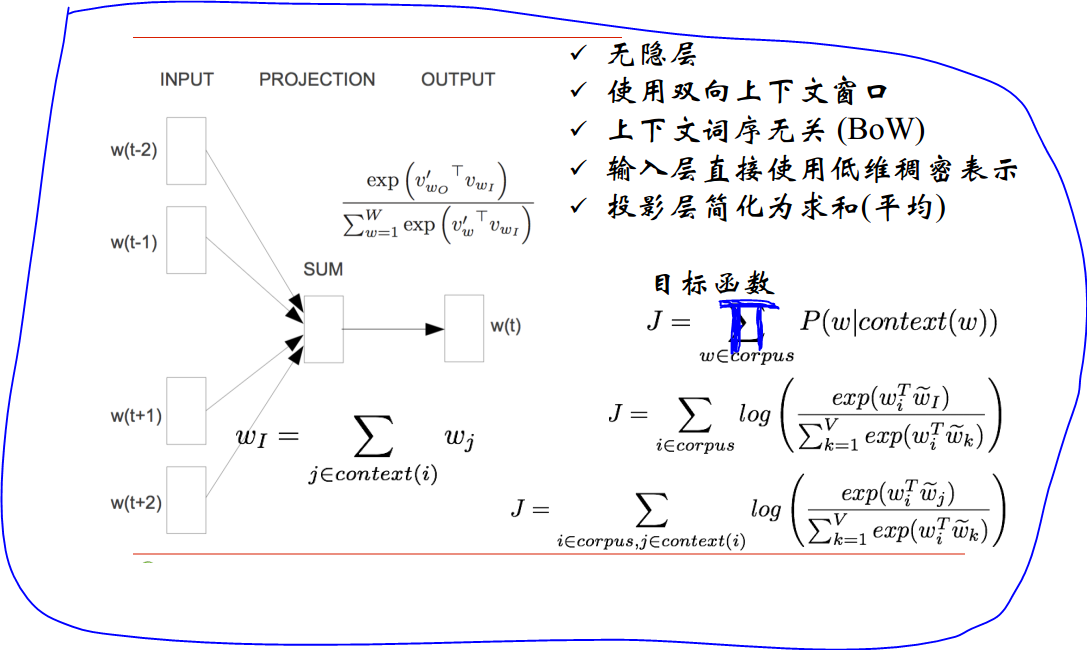
在NNLM中,有一个投影层,投影层有两个用途,一个是将输入的one-hot representation投影成词向量,一个是将词向量拼接。CBOW模型将投射层直接简化为求和,即输入层直接用词向量表示,投影层直接将输入的词向量相加。NNLM模型中,词向量拼接后会导致维度很高,而CBOW模型做求和,向量维度保持不变。假设输入是300维,按照NNLM模型做拼接,结合上图,得到的应该是1200维,而按照CBOW模型,得到的仍然是300维。
假设我们的词表仍然是10w。 求和之后,我们依旧要做的事情就是去预测w(t)这个词。CBOW没有隐层,输出层也是一个softmax分类器。
在NNLM中,softmax的输出是一个10w维的,这个维数实在是太大了,很难去训练。为了解决这个问题,CBOW模型提出了两种解决办法:第一种就是层次softmax。
如何将10w维编码成低维度的数据信息 ,同时保证所有的词都存在呢?我们可以用这10w个词去构建一棵树,我们采用了Huffman Tree来编码输出层的词典。例如我们现在有这么一句话:我喜欢观看巴西足球世界杯,则词表为“我”、“喜欢”、“观看”、“巴西”、“足球”、“世界杯”这6个词。如果按照普通的softmax,我们需要将他们展开为6个节点。这样做太麻烦了,现在我们用Huffman Tree来处理这个问题。我们根据这6个词出现的频率来构建一颗Huffman Tree,而这颗树作决策的时候到每个节点只有左右两个分支,往左分支为1, 往右分支为0。所以softmax里面所有的权重都在节点之间的边上。对于普通的softmax,求和后是300维,输出是10w维,则有一个300 x 10w的权重,这个计算量实在是太大了。层次softmax做了一个事情,它把这些词都编码成了Huffman Tree,把权重θ放到了树上,即每一个做决策的节点上都留了一个权重。这样就将softmax转化成了一个连续做二分类的问题。这样计算量就降低为logV这个量级了(V为词表的长度),做计算的时候只需要logV这么多的参数。
二分类使用的sigmoid函数为![]() ,此处x就是权重θ的转置。假设我们用“我”、“喜欢”、“观看”、“巴西”、“世界杯”来预测“足球”,我们从根节点出发,只需要做1001这样的决策,即做了4个二分类。我们的目标就是最大化这4次二分类连乘的结果。因为Huffman编码是1001,所以目标函数就是
,此处x就是权重θ的转置。假设我们用“我”、“喜欢”、“观看”、“巴西”、“世界杯”来预测“足球”,我们从根节点出发,只需要做1001这样的决策,即做了4个二分类。我们的目标就是最大化这4次二分类连乘的结果。因为Huffman编码是1001,所以目标函数就是
![]()
(2)Skip-gram模型: 输入一个单词, 输出对上下文的预测,比如:我喜欢学习机器学习,已知“学习”,来预测上文“我”、“喜欢”,下文“机器学习”。















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









