







0 引言:
KMP用于, 在文本字符串 (或称文本串,字符串)s 中,
找出模式串(或称匹配串) pattern 出现的位置;
举例:
在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf,
并返回在字符串中开始出现模式串 pattern 的 下标位置;
code
class Solution:
# 算法中实现的关键点是:
# 通过判断能够回退跳转的指针 是否在初始位置, 以及此时 ,两指针对应位置上的元素是否相同;
# 当字符串与模式串匹配时,可跳转回退的指针是模式串中的指针, 后移指针是字符串中的指针;
# 当在模式串中,生成next 数组时, 可回退的指针是前缀下标指针, 后移的是后缀下标指针;
def strStr(self, haystack:str, pattern: str) -> int:
a = len(haystack)
b = len(pattern)
if a == 0 and b != 0: return -1
if a == 0 and b == 0: return 0
if b == 0: return 0
p, q = 0, 0 # 字符串指针 p 始终向后移动,不会回退, 模式串指针q 则会 回退;
next = self.getNext(b, pattern)
while(p < a and q < b): # p 指向字符串, q指针指向模式串;
# 判断的标准 是以模式串中的 指针q是否在起始点, 以及此时两者对应位置上的元素是否相同时, 为转折点
if q == 0 and haystack[p] != pattern[q]: #当 模式串指针q: 在初始位置时或者回退到初始位置时;当 模式串指针p 在初始位置时 或者回退到初始位置时
p += 1 # 移动的是不能跳转的指针, 则字符串指针p 向后移动;
elif haystack[p] == pattern[q]: # 当两个串对应位置上的元素相同时, 两个指针向后移动
p += 1
q += 1
elif q != 0 and haystack[p] != pattern[q]: # 模式串指针q != 0 , 两者对应元素不相等时, 模式串指针往前回退;
q = next[q - 1]
if q == b: # 如果模式串指针, 已经到达过最后一个位置(b-1), 说明模式串中的所有字符匹配上了 字符串;
return p - q
else:
return -1
def getNext(self, b: int, pattern: str) -> list:
j = 0 # j 前缀串指针的终止下标, 前缀串 j 会跳转
i = 1 # i 后缀串的 起始下标, 后缀串 i 始终向后移动
next = ["" for _ in range(b)] # 创建一个长度与模式串相同的空数组, 用于存放最大相同前缀后缀的长度值;
next[0] = 0
while (i < b):
if j == 0 and pattern[j] != pattern[i]: # 当j 已经在初始位置时, 两者对应的元素仍不相同时, 则最大相同前缀后缀长度为 0;
next[i] = 0
i += 1
elif pattern[i] == pattern[j]: # # 前缀串终止位置上的元素 == 后缀串起始位置上的元素, 说明两个串之间至少会存在 长度为 1的 最长相同前缀 后缀串;
next[i] = j + 1 # # 最长相同前缀后缀串的长度 = 前缀串的终止位置 + 1 = 因为前缀串的位置是从 0 开始的,加一之后,求得的便是相同前缀串 后缀串的 长度;
j += 1
i += 1
elif j !=0 and pattern[j] != pattern[i]:
j = next[j - 1]
return next
if __name__ == "__main__":
obj1 = Solution()
str1 = obj1.strStr("abeababeabf", "abeabf")
# str1 = obj1.strStr("hello", "ll")
# str1 = obj1.strStr("aaaaa", "bba")
# str1 = obj1.strStr("aaaaa" ,"bba")
print(str1)
KMP的主要贡献思想:
- KMP 字符串的指针不会往前回退, 只会不断往后移动;
- 模式串中的指针,回退过程中, 总是先寻找是否存在相同的前缀串, 然后回退到相同前缀串的后一个位置, 直到没有相同前缀串后, 模式串的指针才回退到初始位置, 即通过模式串已匹配部分中相同的「前缀」和「后缀」来加速下一次的匹配。;
分析:
字符串中指针不回溯至「发起点」意味着什么?
其实是意味着:随着匹配过程的进行,字符串的指针不断右移,本质上是在不断地在否决一些「不可能」的方案。
当字符串指针从 i 位置后移到 j 位置,不仅仅代表着「字符串」下标范围为 [i,j) 的字符与「模式串」匹配或者不匹配,更是在否决那些以「字符串」下标范围为 [i,j)为「匹配发起点」的子集。
在具体实现过程中,构造了最长相同前缀后缀next数组;
然后在字符串与模式串的匹配的过程中,调用 next 数组;
1. 最长相同前缀后缀
最长相同前缀后缀有的也称 前缀表,
该前缀表通常用一个 next 数组表示,
该数组中存储了, 模式串中每个位置上对应的最长相等前缀后缀的长度数值;
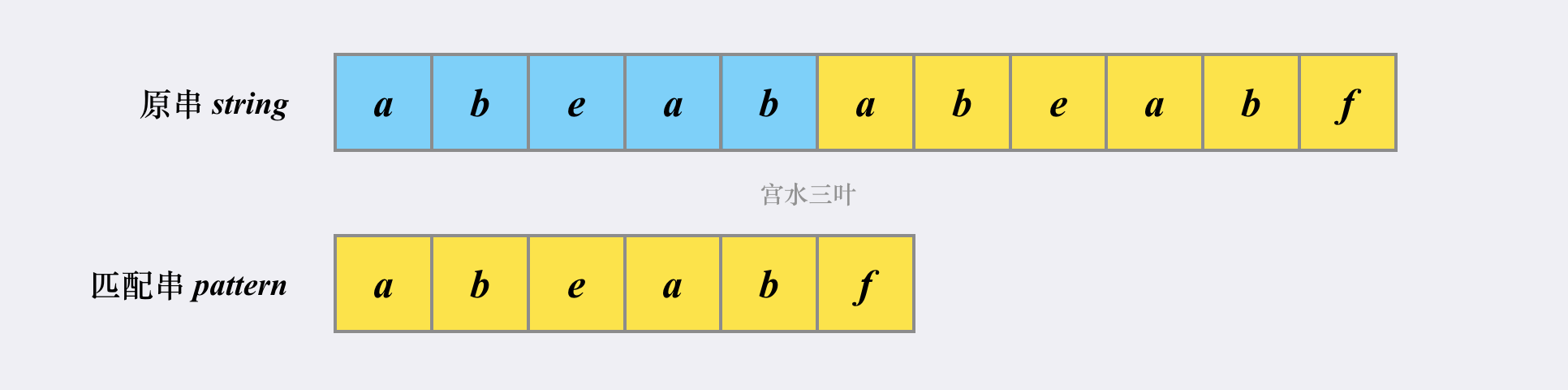
举个例子 , 以上图的匹配串(模式串): a b e a b f 说明;
1.1 前缀串
是指 以第一个字符为开头的所有连续子串, 但不包括最后一个字符;
模式串 a b e a b f : 所有的前缀有:
a ;
a b;
a b e;
a b e a;
a b e a b;
注意:
当字符串只有一个字符时, 便不存在前缀串后缀串的概念;
此时最后一个字符即第一个字符;
1.2 后缀串
是指以最后一个字符为结尾的所有连续子串, 但不包括一个字符;
模式串 a b e a b f : 所有的后缀串有:
f;
b f;
a b f;
e a b f;
b e a b f;
1.3 最长相同前缀后缀表 (即 next 数组)实例
j 代表前缀串的终止位置;
i 代表 后缀串的 起始位置; 两个指针都是向后移动;
此处,
前缀串终止位置
j
j
j从 0开始;
后缀串起始位置
i
i
i从 1开始;
next[0] 初始化赋值为 0;
随着
i
,
j
i,j
i,j 的向右移动,
前缀, 后缀串也在不断的变化;
a b e a b f;
c u r cur cur 为上述模式串中当前子串的下标;
| cur | 当前子串 | 前缀串 | 后缀串 | 最长相同前缀后缀串 | 相同串长度 | next[cur] |
|---|---|---|---|---|---|---|
| 0 | a | None | None | None | 0 | 0 |
| 1 | a b | a | b | None | 0 | 0 |
| 2 | a b e | a b | b e | None | 0 | 0 |
| 3 | a b e a | a b e | b e a | a | 1 | 1 |
| 4 | a b e a b | a b e a | b e a b | a b | 2 | 2 |
| 5 | a b e a b f | a b e a b | b e a b f | None | 0 | 0 |
注意, 上述 next 数组中值, 这里我们是通过人眼观察得来的相同的串长度;
那么实际在操作中, 如何得出最长相同前缀后缀长度;
1.4 next 数组的构造过程:
next 数组作用: 根据模式串,生成最大相同前缀后缀表
在模式串中构造了最长相同前缀后缀 next 数组,
此时模式串中存在两个指针:
前缀串的起始位置固定为第一个字符, 终止下标的作用为双向的,可回退指针(指可跳转到前面), 这里称为前缀串指针;
后缀串的起始下标作用为单向的向后移动指针,这里称为后缀串指针, 终止位置固定为最后一个字符;
- 该next 数组的长度 = 模式字符串的长度;
- 该next [i] 数组中的值 = 代表了在模式串中下标 i 的位置上,最长相同前缀后缀的长度;
I. 当前缀串指针已经在初始位置时,
并且此时前缀串指针与后缀串指针对应位置上的元素不相同时:
则此时最大相同前缀后缀的长度赋值为 0;
后缀串指针 +1; 前缀串指针保持不变;
II. 前缀串指针与后缀串指针对应位置上的元素相同时:
则此时最大相同前缀后缀的长度 赋值为 = 前缀串指针的位置 + 1;
后缀串指针, 前缀串指针两者同时 加 1;
III. 当前缀串指针不在初始位置时,并且此时前缀串指针与后缀指针对应位置上的元素不相同时:
前缀串指针回退到 = 具有相同前缀串的后一个位置;
1.5 当字符串与模式串匹配的过程中;
字符串中的 指针是单向的后移指针, 模式串中指针是双向的可回退指针;
I. 当可回退指针 已经在 初始位置时,并且此时 可回退指针与后移指针 对应位置上的 元素不相同时:
则字符串中的后移指针 +1; 模式串中的可回退指针保持不变;
II. 可回退指针与后移指针 对应位置上的元素相同时:
后移指针; 与 可回退指针 两者同时 加 1;
III. 当 可回退指针 不在初始位置时,并且此时 可回退指针与 后移指针对应位置上的 元素不相同时:
模式串中的可回退指针 回退到 = 具有相同前缀串的后一个位置;(此时调用到 next 数组)
2 next 数组的构造
首先, 回顾next 数组的意义:
在模式串中构造了最大相同前缀后缀 next 数组, 该next数组中的值 Vaule 代表了:
在模式串中, 前缀下标
j
j
j与后缀下标
i
i
i, 两个位置上 所对应的元素不相等时:
模式串中的 前缀下标
j
j
j 所应该回退到与当前坐标具有相同前缀串的后一个位置上, 从而减少在模式串中的遍历元素的次数;
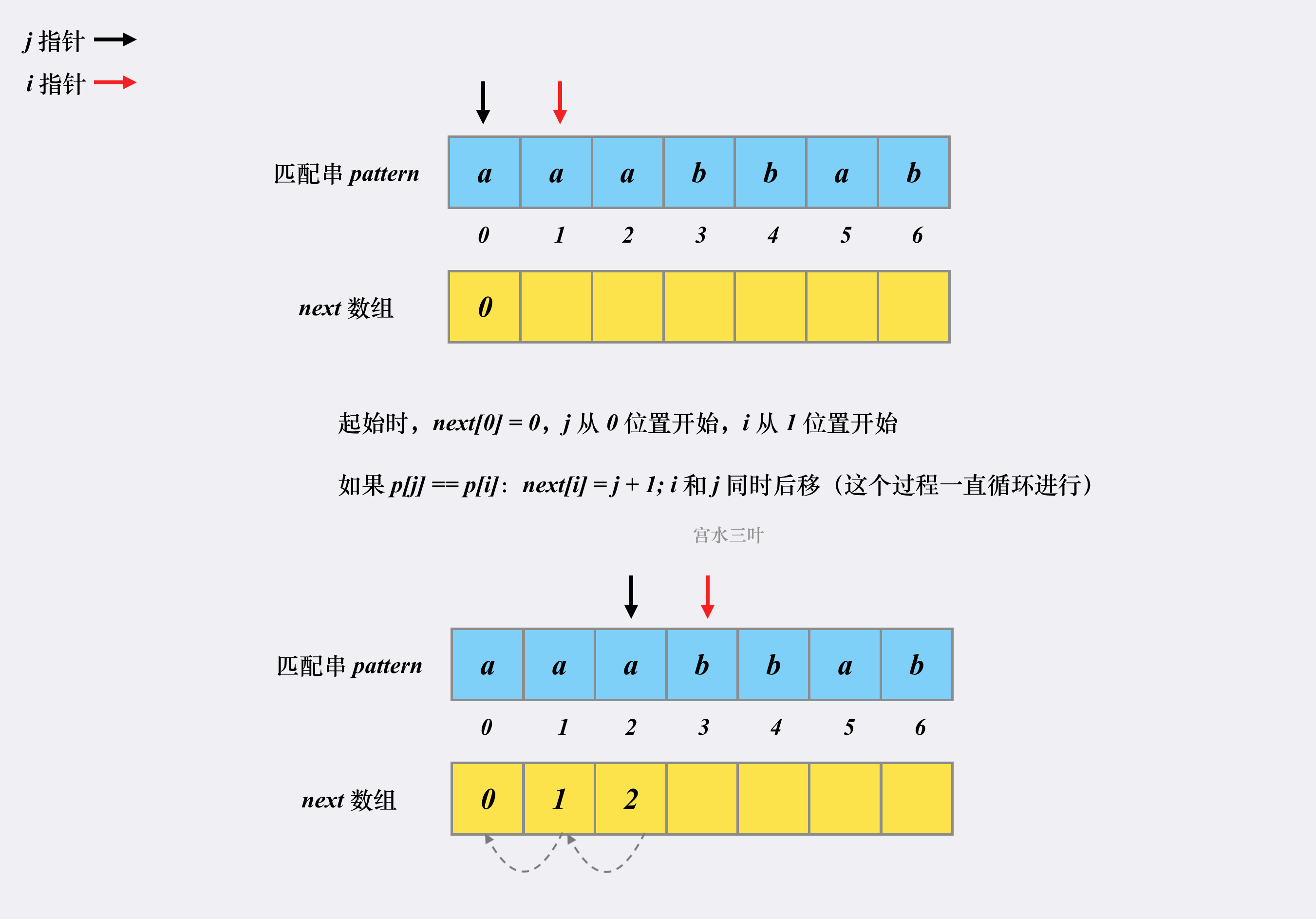
2.1 next 数组初始化
注意有的地方,是将j 从 -1 开始, 然后整个next 数组中的数值要全部减一 才与 最长相同前缀后缀中的数值相等;
此处, j 从0 开始, 目的便于 理解, 这样 next 数组中 的数值 与 最长相同前缀后缀串的 数值 就相等, 对应起来;
两者在实现上 稍有不同, 至于前人为什么要统一 减一, 这个操作的原因,个人暂时不知道, 希望有知道的可以提出来;
j 代表前缀串的 终止位置; 从 0 开始
i 代表后缀串的 起始位置; 从 1 开始;
next[0] = 0 , 初始化为0, 因为 i = 1 时,
此时前缀串 和后缀串 没有相同的子串;
j = 0
i = 1
next[0] = 0
2.2 前缀后缀上的元素相同时: p[j] == p[i]
当前缀串终止位置j上的元素 == 后缀串起始位置i上的元素时,
此时,表明两者拥有相同的子串,
相同子串的长度 = 前缀串的终止位置 + 1 = j + 1;
将相同子串的长度 (j + 1) 放入到 next[i] 数组中,
此时, Next[i] 数组中数值的意义,
表示当模式串中, j与 i 对应位置上的元素相同时, 相同子串的长度;
if next[j] == next[i]:
next[i] = j + 1
i += 1
j += 1
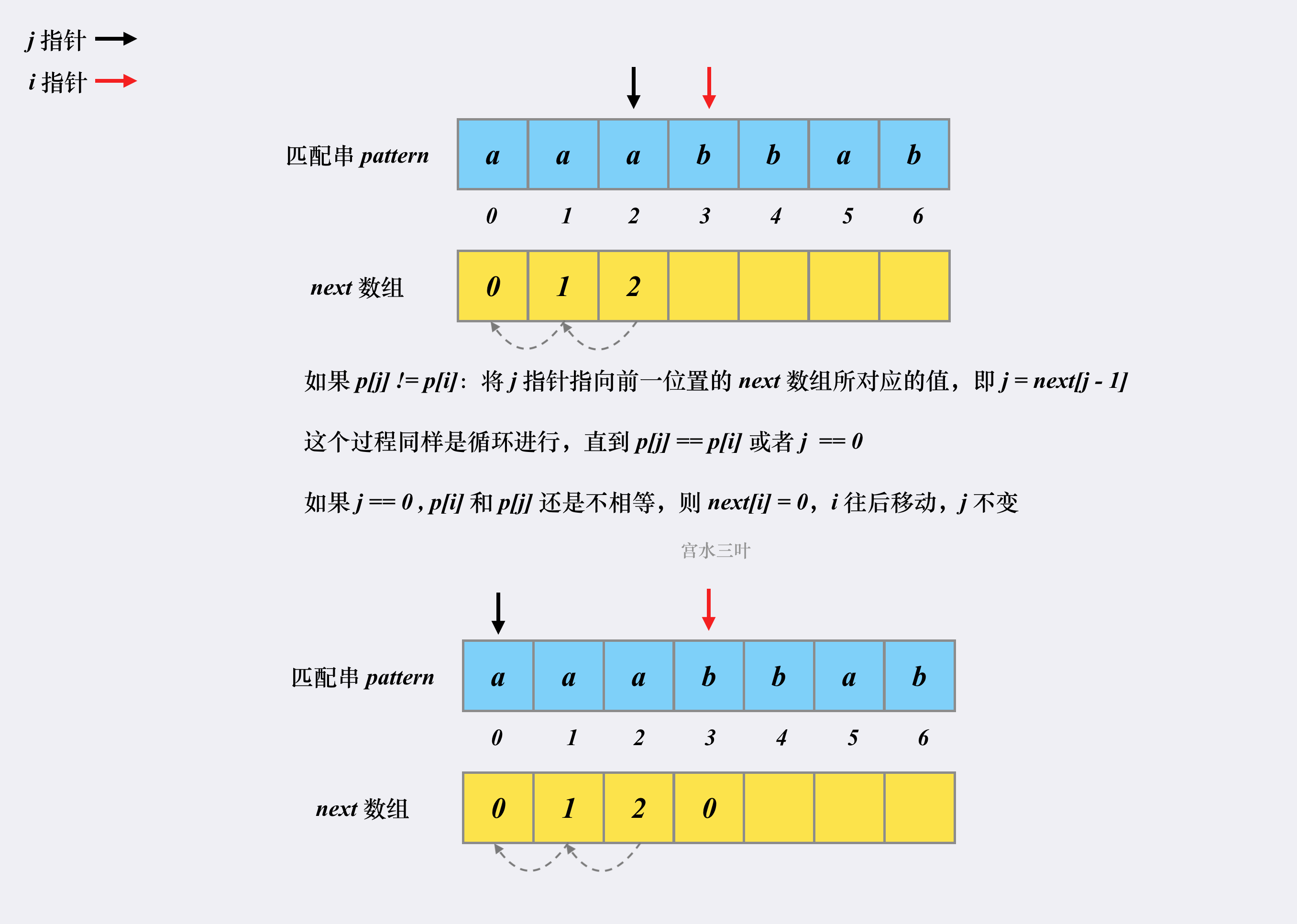
2.3 前缀后缀上的元素不同时: p[j] != p[i]
在模式串中, 当前缀下标 j 与后缀下标 i 对应位置上的元素不相同时,
此时 j 需要回退到 next[ j - 1] 的位置上,直到新位置 j上的 : p[j] == p[i],
或者 j = 0 时, p[j] != p[i] :
则令 next[i] = 0 ; i 后移, j 不变, 知道 p[j] == p[i]
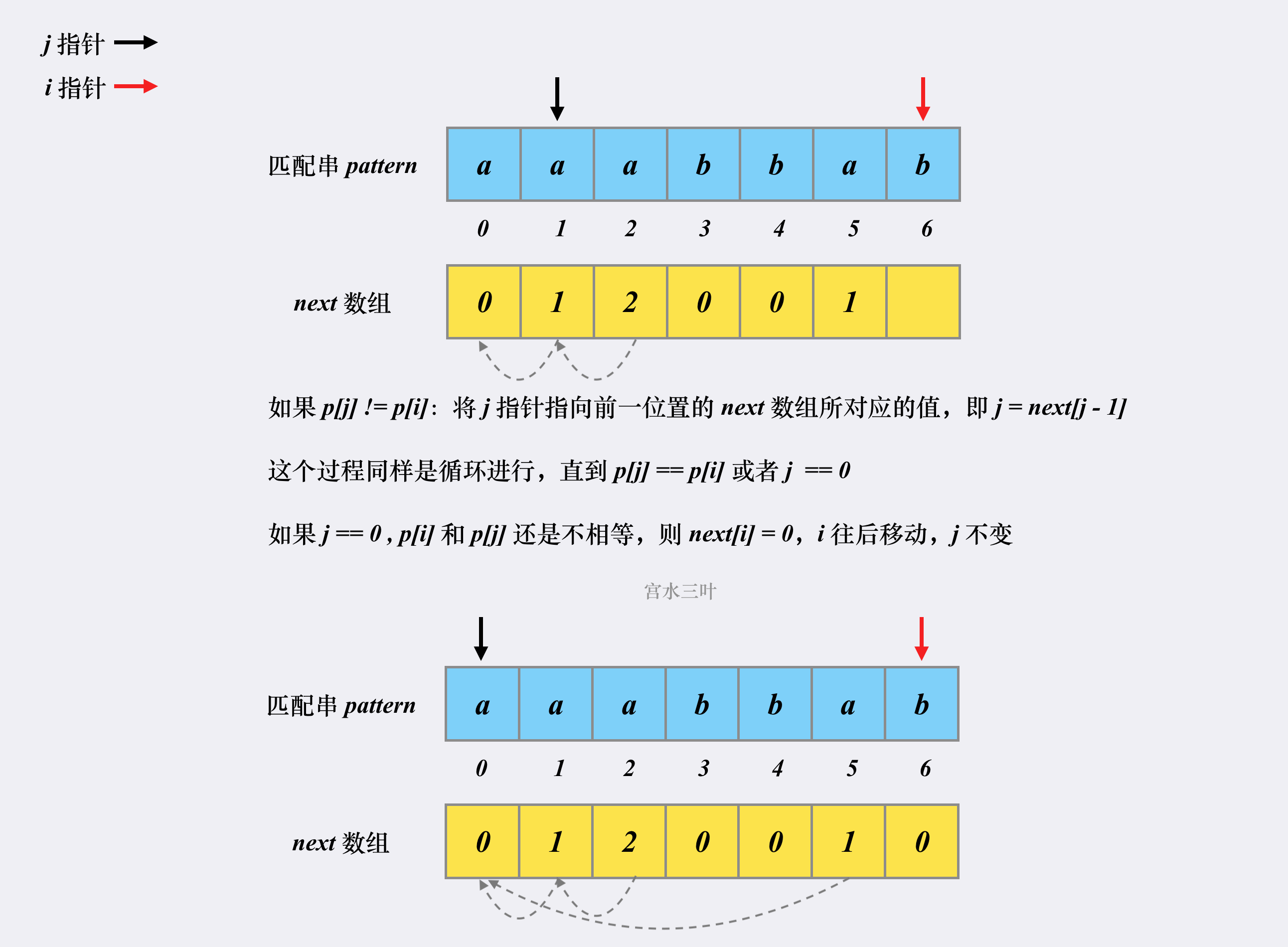
注意有个关键的地方 需要理解:
为什么 回退到的位置 j = next[ j - 1 ]; 理解 这个是 核心中的核心!!!
首先 next[ i ] 中的数值, 代表了最长相同前缀后缀的长度;
即当 前缀终止下标 为 j , 后缀起始下标为i 时, 此时 两者拥有最长相同串的长度为 next[i];
那么当 next[ j - 1] = Value 时,
if j != 0 and p[j] != p[i]:
j = next[j - 1]
elif j == 0 and p[j] != p[i]:
next[i] = 0
i += 1
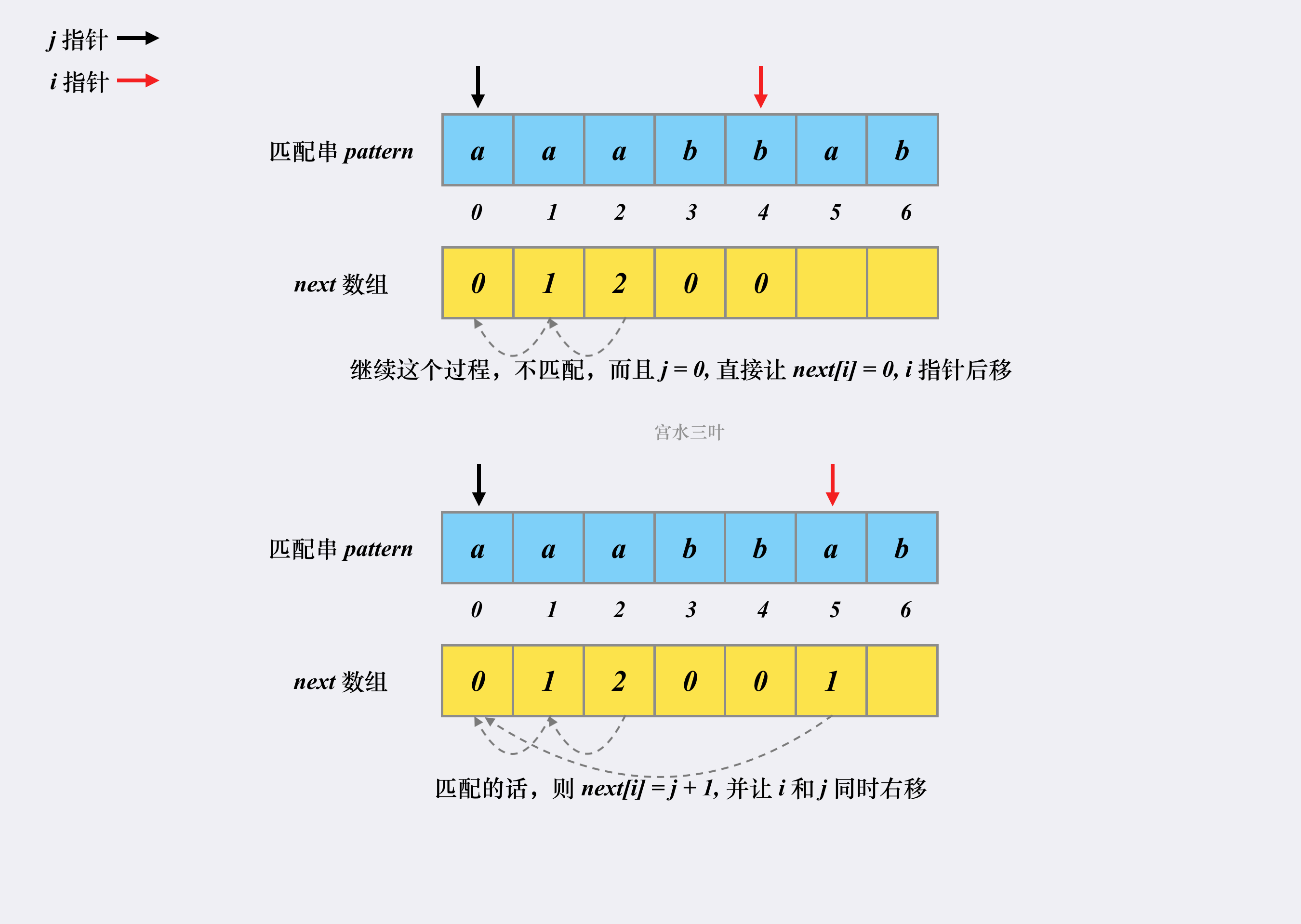
2.3 循环重复上述过程, 直到 i 到达下标末尾:
当 j, i 对应位置上的元素 匹配 与 不匹配 的情况 发生时, 继续循环重复上述的操作 , 直到后缀下标i 走到 模式串中的末尾下标,从而构建出整个 next 数组中的 数值;
3 字符串与模式串 之间的匹配
3.1 两串 匹配时:
当 字符串 位置上的元素 与 模式串 对应位置上的元素 匹配时, 两者的指针 同时 向后移动;
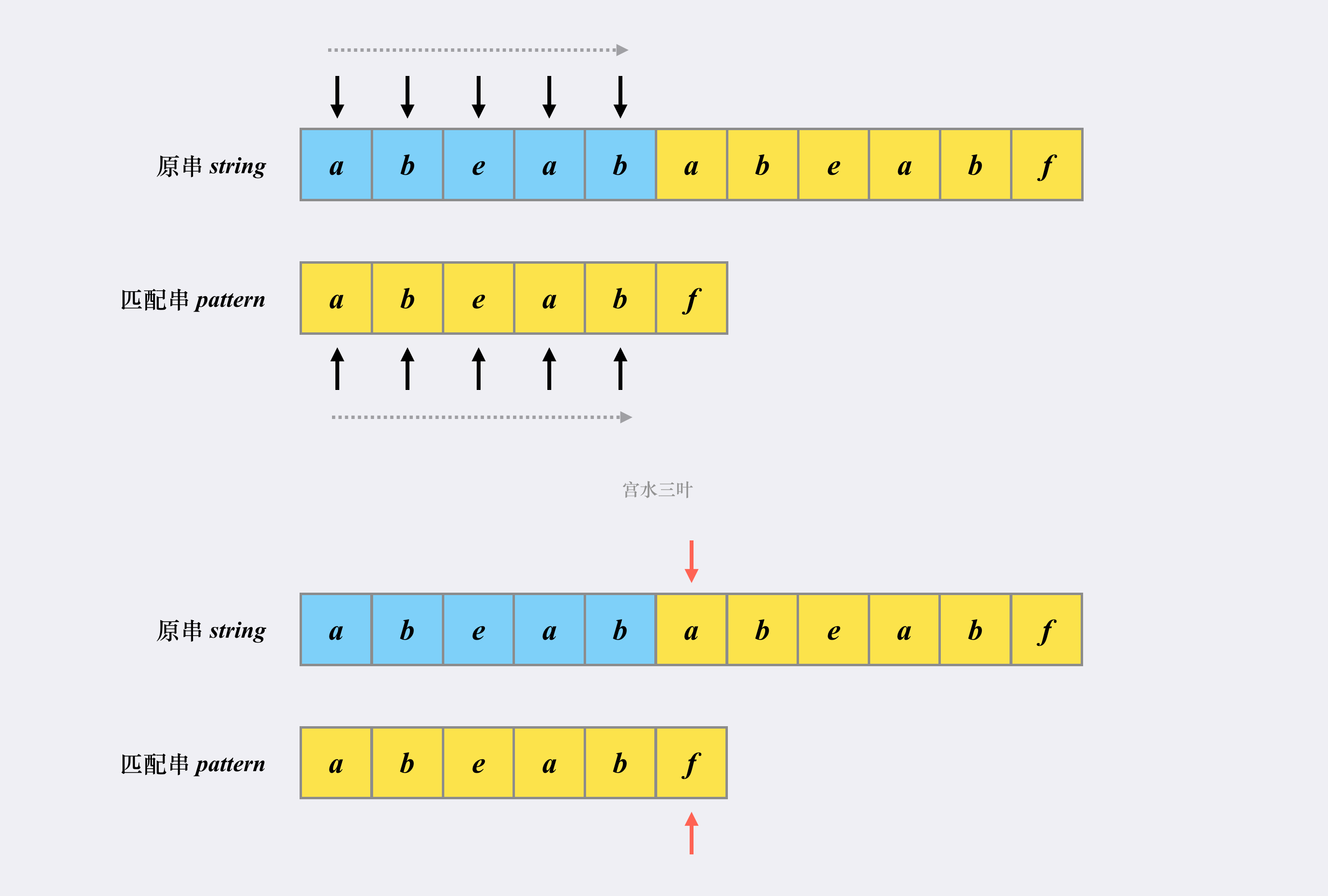
3.1 两串不匹配时:
p: 字符串中的指针,
q: 模式串中的指针保持;
-
当 字符串的元素与模式串上的元素 在最开始就不 匹配时,
即 两个指针: p = q = 0时;string[p ] != pattern[ q]
此时,将字符串中的指针 向后移动, 模式串中的指针保持不变; -
当q >0 时: 字符串的元素与模式串上的元素 仍然不 匹配时,
则 模式串中的指针 q 回退到 q = next[ q - 1 ]; 字符串中的指针保持 不变;
此过程中:
首先匹配串会检查之前已经匹配成功的部分中里是否存在相同的「前缀」和「后缀」。如果存在,则跳转到「前缀」的下一个位置继续往下匹配:

然后, 跳转到下一匹配位置后,尝试匹配,发现两个指针的字符对不上,并且此时匹配串指针前面不存在相同的「前缀」和「后缀」,这时候只能回到匹配串的起始位置重新开始:

到这里,你应该清楚 KMP 为什么相比于朴素解法更快:
因为 KMP 利用已匹配部分中相同的「前缀」和「后缀」来加速下一次的匹配。
因为 KMP 的原串指针不会进行回溯(没有朴素匹配中回到下一个「发起点」的过程)。
第一点很直观,也很好理解。
我们可以把重点放在第二点上,原串不回溯至「发起点」意味着什么?
其实是意味着:随着匹配过程的进行,原串指针的不断右移,我们本质上是在不断地在否决一些「不可能」的方案。
当我们的原串指针从 i 位置后移到 j 位置,不仅仅代表着「原串」下标范围为 [i,j) 的字符与「匹配串」匹配或者不匹配,更是在否决那些以「原串」下标范围为 [i,j)为「匹配发起点」的子集。














 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









