









 多模态深度学习涉及图像、文本、音频等多种数据类型,通过联合或协调表示来理解和融合不同模态信息。常见应用包括图像字幕、跨模态检索、文本到图像生成、视觉问答和情感识别。融合技术如交叉注意力机制在多模态信息整合中起关键作用。COCO-Captions、VQA、CMU-MOSEI等数据集促进了这一领域的研究。
多模态深度学习涉及图像、文本、音频等多种数据类型,通过联合或协调表示来理解和融合不同模态信息。常见应用包括图像字幕、跨模态检索、文本到图像生成、视觉问答和情感识别。融合技术如交叉注意力机制在多模态信息整合中起关键作用。COCO-Captions、VQA、CMU-MOSEI等数据集促进了这一领域的研究。
1. 多模态定义
多模式深度学习是一个机器学习子领域,旨在训练人工智能模型来处理和发现不同类型数据(模式)之间的关系——通常是图像、视频、音频和文本。通过结合不同的模态,深度学习模型可以更普遍地理解其环境,因为某些线索仅存在于某些模态中。想象一下情绪识别的任务。它不仅仅是看一张人脸(视觉模态)。一个人的声音(音频模态)的音调和音高编码了大量关于他们情绪状态的信息,这些信息可能无法通过他们的面部表情看到,即使他们经常是同步的。
1.2 常见模态
在多模态深度学习中,最典型的模态是视觉(图像、视频)、文本和听觉(语音、声音、音乐)。然而,其他不太典型的模式包括 3D 视觉数据、深度传感器数据和 LiDAR 数据(自动驾驶汽车中的典型数据)。在临床实践中,成像方式包括计算机断层扫描 (CT) 扫描和 X 射线图像,而非图像方式包括脑电图 (EEG) 数据。传感器数据,如热数据或来自眼动追踪设备的数据也可以包含在列表中。
最流行的组合是三种最流行的方式的组合
- 图片+文字
- 图像+音频
- 图片+文字+音频
- 文字+音频
2 多模态的研究内容
2.1 模态表示
多模态表示分为两类。
-
联合表示每个单独的模态被编码,然后放入一个相互的高维空间。这是最直接的方式,当模态具有相似的性质时可能会很有效。
-
Coordinated representation每个单独的模态都被编码而不考虑彼此,但是它们的表示然后通过施加限制来协调。例如,它们的线性投影应该最大程度地相关
2.2 模态融合
融合是将来自两种或多种模式的信息结合起来以执行预测任务的任务。
- 由于多模态数据的异构性,多模态(如视频、语音和文本)的有效融合具有挑战性。
2.3 模态对齐
对齐是指识别不同模态之间的直接关系的任务。
2.4 模态转换
模态转换是将一种模态映射到另一种模态的行为。主要思想是如何将一种模态(例如,文本模态)转换成另一种模态(例如,视觉模态),同时保留语义。
2.5 模态共同学习
多模式共同学习旨在将通过一种或多种模式学习的信息转移到涉及另一种模式的任务。在低资源目标任务、完全/部分缺失或嘈杂模式的情况下,共同学习尤为重要。
3. 多模态的运作机理
多模态神经网络通常是多个单模态神经网络的组合。例如,视听模型可能由两个单峰网络组成,一个用于视觉数据,一个用于音频数据。这些单峰神经网络通常分别处理它们的输入。这个过程称为编码。在进行单峰编码之后,必须将从每个模型中提取的信息融合在一起。已经提出了多种融合技术,范围从简单的连接到注意机制。多模态数据融合过程是最重要的成功因素之一。融合发生后,最终的“决策”网络接受融合后的编码信息,并接受最终任务的训练。
简单来说,多模态架构通常由三部分组成:
- 编码单个模态的单峰编码器。通常,每个输入模式一个。
- 一种融合网络,在编码阶段结合从每个输入模态中提取的特征。
- 接受融合数据并进行预测的分类器。
我们将以上称为编码模块(下图中的 DL 模块)、融合模块和分类模块。
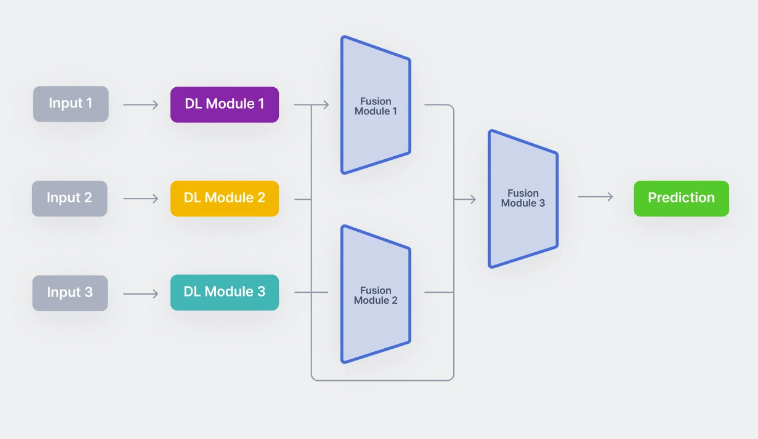
现在让我们更深入地了解每个组件。
3.1 编码
在编码过程中,我们寻求创建有意义的表示。通常,每个单独的模态由不同的单模态编码器处理。但是,通常情况下输入是嵌入形式而不是原始形式。
- 例如,word2vec 嵌入可用于文本;
- 而 COVAREP(一个基于matlab开发的语音库) 嵌入可用于音频。
- 多模态嵌入,如data2veq,将视频、文本和音频数据转换为高维空间中的嵌入,是最新的实践之一,并且在许多任务中优于其他嵌入,实现了 SOTA 性能。
使用联合表示还是协调表示,(上文的模态表示中)是一个重要的决定。
通常当模态在本质上是相似时,使用联合表示的方法效果很好,并且是最常用的方法。
在设计多模态网络的实践中,
编码器的选择是基于在每个领域表现良好的编码器,
因为更加强调融合方法的设计。
- 许多研究论文使用经典的 ResNets 作为视觉模式,
- 使用RoBERTA作为文本。
3.2融合
融合模块负责在特征提取完成后组合每个单独的模态。用于融合的方法/架构可能是成功的最重要因素。
最简单的方法是使用简单的操作,例如连接或求和不同的单峰表示。
然而,更具有经验和成功的方法,已经被研究出来了。例如,交叉注意力层机制是最近成功的融合方法之一。它已被用于以更有意义的方式捕获跨模态交互和融合模态。
下面的等式描述了交叉注意力机制,并假设您基本熟悉自注意力。
α = s ( K l Q k d ) V l \alpha = s (\frac{K_{l}Q_{k}}{\sqrt d})V_{l} α=s(dKlQk)Vl
α
k
l
\alpha_{kl}
αkl表示注意力得分向量,s(.)表示softmax函数,K、Q和V分别是注意力机制的Key、Query和Value矩阵。
为了对称,
α
l
k
\alpha_{lk}
αlk也被计算出来,并且可以将两者相加以创建一个注意力向量,该向量映射所涉及的两种模态(k,l)之间的协同作用。
本质上, α k l \alpha_{kl} αkl, α l k \alpha_{lk} αlk,两者之间的区别,
α
k
l
\alpha_{kl}
αkl是模态
k
k
k被用作query,
α
l
k
\alpha_{lk}
αlk是模态
l
l
l被用作query,被使用
并且模态
k
k
k扮演键和值的角色。
在三个或更多模态的情况下,可以使用多个交叉注意机制,以便计算每个不同的组合。
例如,如果我们有视觉 (V)、文本 (T) 和音频 (A) 模态,那么我们创建组合 VT、VA、TA 和 AVT 以捕获所有可能的跨模态交互。
即使在使用注意力机制之后,也经常执行上述跨模态向量的串联以产生融合向量F。Sum(.)、max(.) 甚至池化操作也可以代替使用。
3.3 分类
最后,一旦融合完成,向量F就被送入分类模型。这通常是具有一个或两个隐藏层的神经网络。输入向量F编码来自多种模态的互补信息,因此与单独的模态 V、A 和 T 相比提供更丰富的表示。因此,它应该增加分类器的预测能力。
从数学上讲,单峰模型的目标是最小化损失
哪里
是一个编码函数,通常是一个深度神经网络,而 C(.) 是一个分类器,通常是一个或多个密集层。
相反,多模态学习的目的是最小化损失:
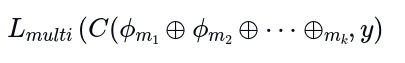
哪里
表示融合操作(例如,连接)和 表示单一模态的编码函数。
4. 多模态应用场景
4.1 image captioning
图像字幕是为给定图像生成简短文本描述的任务。这是一项多模态任务,涉及由图像和短文本描述组成的多模态数据集。它通过将视觉表示转换为文本表示来解决前面描述的翻译挑战。该任务还可以扩展到视频字幕,其中文本连贯地描述短视频。
对于将视觉模式转换为文本的模型,它必须捕获图片的语义。它需要检测关键对象、关键动作和对象的关键特征。参考图例。3,“一匹马(关键对象)背着(关键动作)干草(关键对象)的大负载(关键特征)和两个人(关键对象)坐在上面。” 此外,它需要推断图像中对象之间的关系,例如,“双层床下面有一个狭窄的架子(空间关系)。”
然而,正如已经提到的,多模态翻译的任务是开放式的和主观的。因此,标题“两个人骑着装满干草的马车”和“两个人用马车运送干草”也是有效的标题。
图像字幕模型可用于提供图像的文本替代方案,从而帮助盲人和视障用户。

4.2 跨模态图像检索
图像检索是在大型数据库中查找与检索关键字相关的图像的任务。该任务有时也称为基于内容的图像研究 (CBIR) 和基于内容的视觉信息检索 (CBVIR)。
这样的动作可以通过传统的标签匹配算法来执行,但深度学习多模态模型提供了更广泛的解决方案和更多的功能,这也部分消除了对标签的需求。图像检索可以扩展到视频检索。此外,检索关键字可以采用文本标题、音频甚至另一幅图像的形式,但文本描述是最常见的。
已经开发了几种跨模态图像检索任务。例子包括
文本到图像检索:检索与文本解释相关的图像
组合文本和图像:查询图像和描述所需修改的文本
跨视图图像检索
Sketch-to-image retrieval:使用人造铅笔素描来检索相关图像
每当您在浏览器上进行搜索查询时,搜索引擎都会提供一个“图像”部分,显示与您的搜索查询相关的大量图像。这是图像检索的真实示例。
4.3 文本到图像生成
文本到图像生成是目前最流行的多模态学习应用程序之一。它直接解决了翻译挑战。Open-AI 的 DALL-E 和谷歌的 Imagen 等模型一直是头条新闻。
这些模型所做的可以被认为是图像字幕的反面。给定简短的文本描述作为提示,文本到图像模型会创建一个准确反映文本语义的新颖图像。最近,文字转视频的模式也首次亮相。
这些模型可用于辅助 Photoshop 和图形设计,同时也为数字艺术提供灵感。

4.4 视觉问答(VQA)
视觉问答是另一种多模态任务,它结合了视觉模态(图像、视频)和文本模态。在 VQA 期间,用户可以提出有关图像或视频的问题,模型必须根据图像中发生的情况回答问题。要成功解决这个问题,需要对场景有很强的视觉理解以及常识性知识。封闭式 VQA 的简单示例包括“图片中有多少人”和“孩子坐在哪里?” 然而,VQA 可以扩展到自由形式、开放式的问题,这些问题需要更复杂的思维过程,如下图所示。
视觉问答是一种多模态应用程序,包含翻译和对齐挑战。
这些模型可用于帮助盲人和视障用户或提供高级视觉内容检索。
4.5 情绪识别
情感识别是一个很好的例子,说明了为什么多模态数据集优于单模态数据集。仅使用单模态数据集即可执行情感识别,但如果将多模态数据集用作输入,则性能可能会有所提高。多模态输入可以采用视频+文本+音频的形式,但脑电图数据等传感器数据也可以合并到多模态输入中。
然而,已经表明,与单一模式对应物相比,有时使用多种输入模式实际上可能会降低性能,即使具有多种模式的数据集总是会传达更多信息。这归因于训练多模态网络的困难。如果您有兴趣了解更多有关这些困难的信息,本文应该证明是有用的
5. 多模态数据集
没有数据,就没有学习。
多模态机器学习也不例外。为了推进该领域,研究人员和组织已经创建并分发了多个多模式数据集。以下是最受欢迎的数据集的完整列表:
5.1 COCO-Captions 数据集:
一个多模式数据集,包含 330K 图像并附有简短的文本描述。该数据集由微软发布,旨在推进图像字幕研究。
5.2 VQA
:一个视觉问答多模态数据集,包含 265K 个图像(视觉),每个图像至少有三个问题(文本)。这些问题需要理解视觉、语言和常识知识才能回答。适用于视觉问答和图像字幕。
5.3CMU-MOSEI
:Multimodal Opinion Sentiment and Emotion Intensity (MOSEI) 是一个用于人类情绪识别和情绪分析的多模态数据集。它包含 23,500 个句子,由 1,000 名 YouTube 演讲者发音。该数据集将视频、音频和文本模式合二为一。用于在三种最流行的数据模式上训练模型的完美数据集。
5.4.Social-IQ
:一个完美的多模态数据集,用于训练视觉推理、多模态问答和社交互动理解方面的深度学习模型。包含 1250 个音频视频(在动作级别),并带有与每个场景中发生的动作相关的问题和答案(文本)。
5.5 Kinetics 400/600/700
:此视听数据集是用于人类动作识别的 Youtube 视频集合。它包含人们执行各种动作的视频(视觉模态)和声音(音频模态),例如播放音乐、拥抱、进行运动等。该数据集适用于动作识别、人体姿势估计或场景理解。
5.6.RGB-D 对象数据集
:结合了视觉和传感器模态的多模态数据集。一个传感器是 RGB,对图片中的颜色进行编码,而另一个是深度传感器,对物体与相机的距离进行编码。该数据集包含 300 个家庭物品和 22 个场景的视频,相当于 250K 张图像。它已被用于 3D对象检测或深度估计任务。
其他多模式数据集包括IEMOCAP、CMU-MOSI、MPI-SINTEL、SCENE-FLOW、HOW2、COIN和MOUD。

















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









