






一、问题描述
在一次使用查询中,知道结果集很大,使用了from、size的方案进行轮训查询,结果在from + size > 10000时报错:
get tid once, from:0, size:100
get tid once, from:100, size:100
get tid once, from:200, size:100
get tid once, from:300, size:100
......
get tid once, from:9700, size:100
get tid once, from:9800, size:100
get tid once, from:9900, size:100
get tid once, from:10000, size:100
get need modify tid fail: es query fail:elastic: Error 500 (Internal Server Error): all shards failed [type=search_phase_execution_exception]
10000是es默认最大查询结果集的数量,由参数index.max_result_window控制。
二、原因分析
这跟我理解的不太一样了,我认为用from + size是一次取100,没有超过10000,看结果是from + size的数量不能超过10000,于是在命令行上测试了相关操作:
GET media_std_content_dispatch/_search
{
"from": 10000,
"size": 10
}应答:
{
"error":{
"root_cause":[
{
"type":"query_phase_execution_exception",
"reason":"Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type":"search_phase_execution_exception",
"reason":"all shards failed",
"phase":"query",
"grouped":true,
"failed_shards":[
{
"shard":0,
"index":"media_std_content_dispatch",
"node":"UMQ0-vTxRQiXkR4vu8iyoQ",
"reason":{
"type":"query_phase_execution_exception",
"reason":"Result window is too large, from + size must be less than or equal to: [10000] but was [10010]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status":500
}查看了源码,发现from、size的方式在from + size > maxResultWindow时会报错,具体参考:
server/src/main/java/org/elasticsearch/search/DefaultSearchContext.java
/**
* Should be called before executing the main query and after all other parameters have been set.
*/
@Override
public void preProcess() {
if (hasOnlySuggest()) {
return;
}
long from = from() == -1 ? 0 : from();
long size = size() == -1 ? 10 : size();
long resultWindow = from + size;
int maxResultWindow = indexService.getIndexSettings().getMaxResultWindow();
if (resultWindow > maxResultWindow) {
if (scrollContext() == null) {
throw new IllegalArgumentException(
"Result window is too large, from + size must be less than or equal to: ["
+ maxResultWindow
+ "] but was ["
+ resultWindow
+ "]. See the scroll api for a more efficient way to request large data sets. "
+ "This limit can be set by changing the ["
+ IndexSettings.MAX_RESULT_WINDOW_SETTING.getKey()
+ "] index level setting."
);
}
......
}
......
}三、解决办法
1、扩大max_result_window
把max_result_window扩大到比结果集还大,就能用from、size的方式循环取结果,或者用普通查询方式一次把结果取出来。
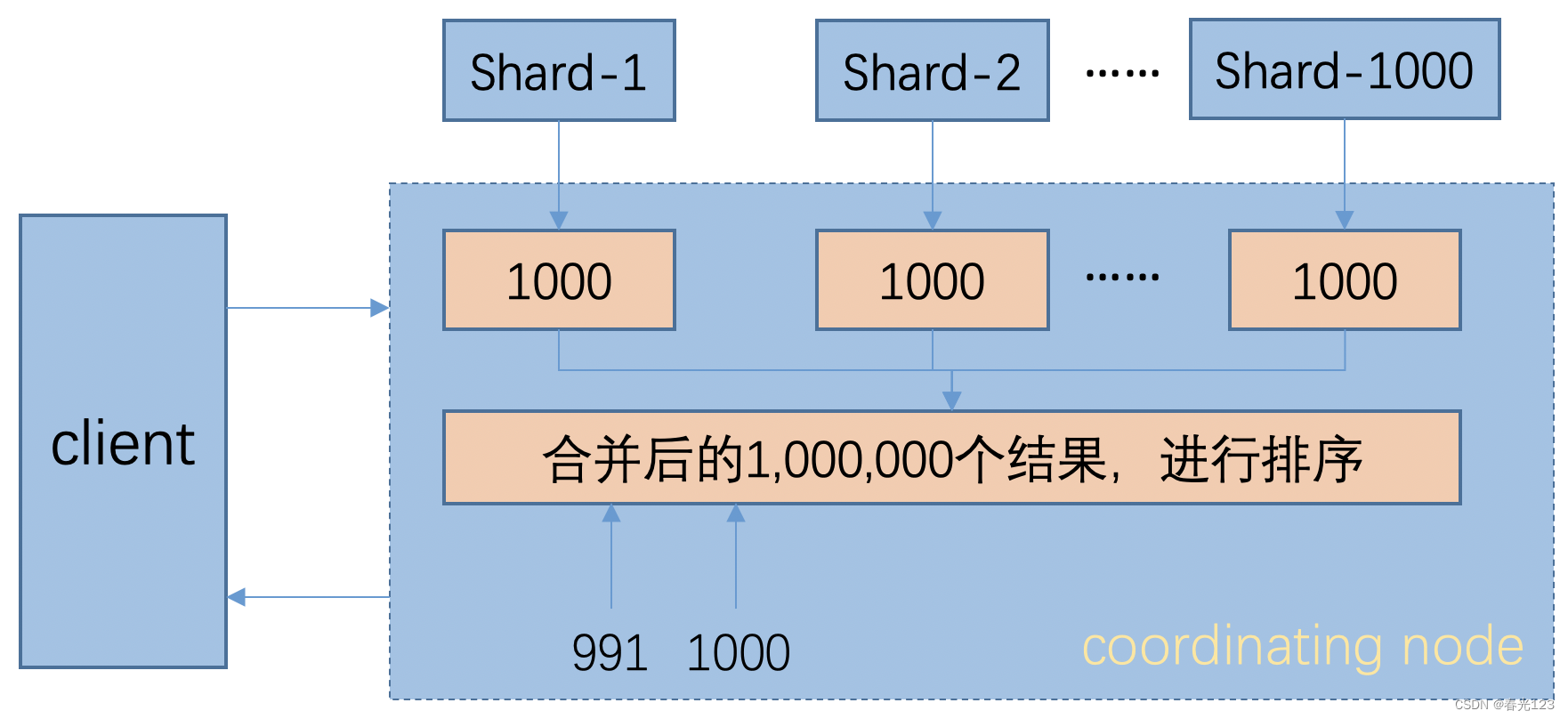
from、size的方式是从每个shard上先取from + size条数据,然后发送到请求节点上,请求节点进行合并排序,取出需要的部分;例如1000个shard,from = 990,size = 10,那么每个shard就要取1000条数据,总共100万条数据发送到请求节点,请求节点对这100万条数据进行排序,然后取出排序后的991 - 1000共10条数据;这种操作在带宽、计算性能和存储等方面都有很大的浪费,非常不建议这种做法。
下面是这种方式的大概流程:
2、search_after方式
search_after是指定按一些字段排序,逐步往后走,可以类比mysql的order by limit操作:
1、select fields from table order by id asc limit 10;
记录下最后一条数据的id:last_id,用作下面的比较条件
2、select fields from table where id > last_id order by id asc limit 10;
记录下最后一条数据的id:last_id,用作后续的比较条件,循环步骤2
具体操作方式如下:
DELETE test_index
// 写入测试数据
POST test_index/_bulk
{ "index":{} }
{ "name":"a","age":1 }
{ "index":{} }
{ "name":"b","age":2 }
{ "index":{} }
{ "name":"c","age":3 }
{ "index":{} }
{ "name":"d","age":4 }
{ "index":{} }
{ "name":"e","age":5 }
{ "index":{} }
{ "name":"f","age":6 }
{ "index":{} }
{ "name":"g","age":7 }
第一次请求
GET test_index/_search
{
"size": 2,
"sort": [
{
"age": { // 比较字段的名称,按 age 升序排序
"order": "asc"
}
}
]
}
返回结果,只保留主要的信息
{
"hits":{
"hits":[
{
"_source":{
"name":"a",
"age":1
},
"sort":[
1 // 这条数据对应排序字段的值
]
},
{
"_source":{
"name":"b",
"age":2
},
"sort":[
2 // 这条数据对应排序字段的值
]
}
]
}
}
后续请求
GET test_index/_search
{
"size": 2,
"search_after":[2], // 指定 sort 字段上次结果集中,最后一条结果的值;如果 sort 中有多个字段,只需要跟sort的顺序一致即可
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
应答
{
"hits":{
"hits":[
{
"_source":{
"name":"c",
"age":3 // 接着 2 后面的数据
},
"sort":[
3
]
},
{
"_source":{
"name":"d",
"age":4
},
"sort":[
4
]
}
]
}
}
如果有多个字段,sort和search_after里面是多个字段的数组,顺序要对应,类似于mysql中多个字段的order by:
select fields from table order by field_a asc, field_b desc limit 10;、
这种方式,要取100个数据的话,首先在每个shard上,按sort字段查找100个数据,然后在请求节点上进行排序,取出需要的数据,这比from、size方法在带宽、内存和计算资源上都有不少的节省。
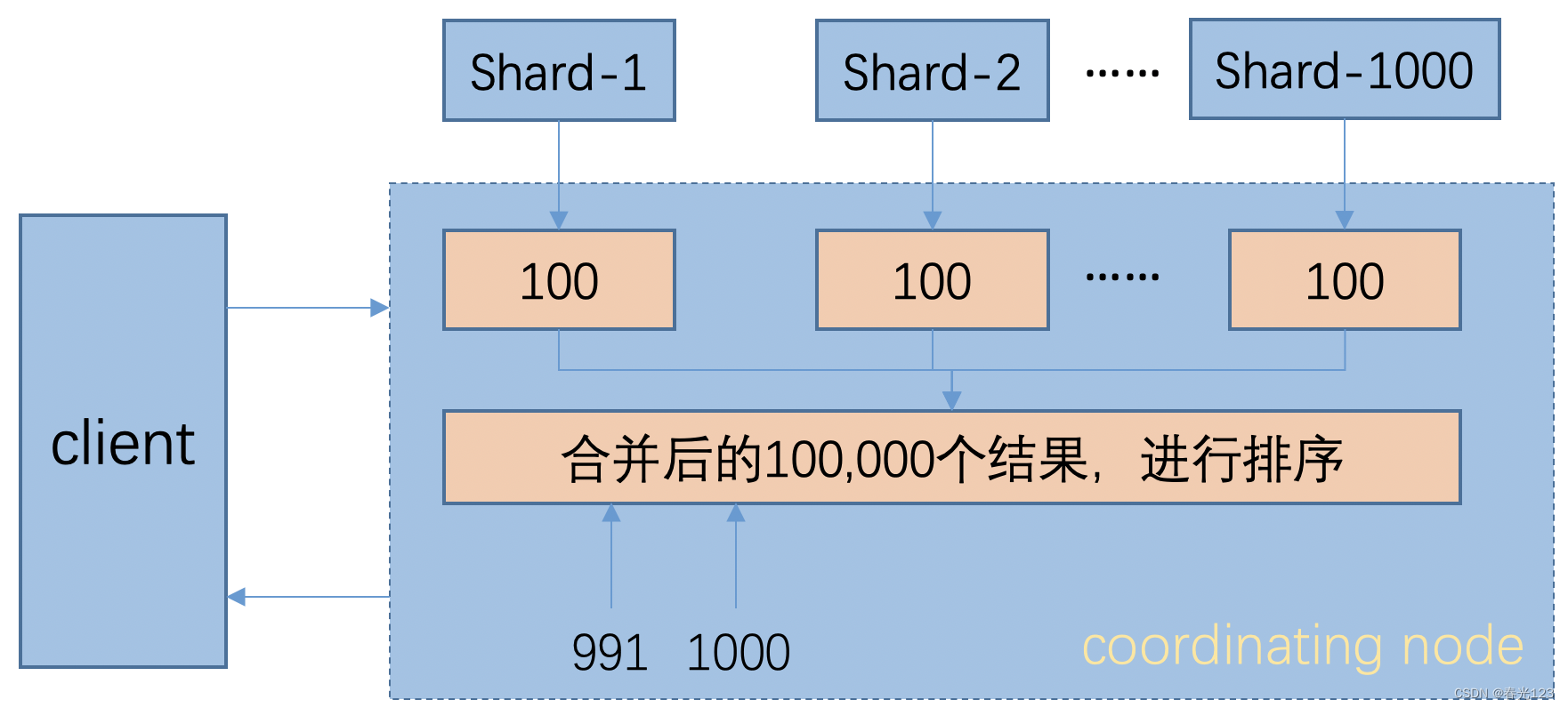
注意:
这种方法有个地方要注意,它是按sort field的顺序往后找,假设开始数据中age = 1、3、5、7,当使用search_after方式查到age = 5时,插入了一条age = 2的数据,search_after这种方式是搜索不到新插入的数据,因为要搜索的是age > 5的数据,新数据不满足。
3、scroll方式
scroll方式首先对查询结果生成快照,后续的操作都是针对这个快照进行的;因为是当时的快照,新数据不会包含在内,所以不能用于实时的操作。
scroll方式只需要知道这个快照的id,叫scroll_id,就能循环获取后续数据
// 第一次请求,指定是 scroll 方式
GET test_index/_search?scroll=1m
{
"size": 2
}
// 应答信息
{
"_scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAQEPczgWVU1RMC12VHhSUWlYa1I0dnU4aXlvUQ==",
"hits":{
"total":7,
"hits":[
{
"_source":{
"name":"a",
"age":1
}
},
{
"_source":{
"name":"b",
"age":2
}
}
]
}
}
// 后续请求
GET /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAQEPczgWVU1RMC12VHhSUWlYa1I0dnU4aXlvUQ=="
}
// 后续应答
{
"_scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAQEPczgWVU1RMC12VHhSUWlYa1I0dnU4aXlvUQ==",
"hits":{
"total":7,
"hits":[
{
"_source":{
"name":"c",
"age":3
}
},
{
"_source":{
"name":"d",
"age":4
}
}
]
}
}我们只需要知道第一次请求产生的快照id:_scroll_id = DXF1ZXJ5QW5kRmV0Y2gBAAAAAQEPczgWVU1RMC12VHhSUWlYa1I0dnU4aXlvUQ==,后续的请求都拿这个_scroll_id继续从这个快照里拿后续数据,个人猜测每个scroll快照里应该有个offset之类的信息,这样才能不断往后取数据。
“GET test_index/_search?scroll=1m”请求中的scroll=1m表示这个scroll快照要保留1 minute,相当于快照的ttl,后面每次请求中的"scroll" : "1m"也是这个意思,表示再次设置该快照的ttl为1 minute;如果知道后续数据处理的越来越慢,可以逐渐调大这个scroll的保留时间,避免快照被超时销毁。
四、结论
from、size的方式获取数据量不能超过max_result_window,也不建议调大这个参数,从效果和性能上看,scroll方式是获取大结果集的合适方式。















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









