






一、项目目的
本项目旨在优化长才机电设备生产过程中产品质检这一关键环节,通过采用人工智能和相关应用,将这些技术部署在硬件设备上,全面提升质检流程的效率和质量。通过本项目的实施,将减少质检过程中所需的人力和财力资源的投入,并实现质检过程的自动化。
项目的具体目标如下
1、实现无人监管的质检流程:通过自动化软件程序的引入,能够在指定时间内自动、精准执行质检任务,无需人工介入。该系统确保在规定时间内高效完成所有质检任务,极大简化操作流程、提高工作效率。
2、实现高效高质量的质检操作:借助人工智能技术和自动化工具,质检过程将更加智能化,确保每一项质检任务都能达到高质量标准。自动化系统化系统能够快速检测设备中潜在的问题,保证质检工作的精确性和可靠性。
3、优化了人力和财力的资源开销:通过自动化质检系统的应用,大幅降低对人工质检的依赖,减少了人员和时间成本。同时,自动化之间的高效率也减少了财力资源的开销,使得公司能够将更多的资源用于其他核心业务,进一步提升提运营效率。
4、降低操作风险:无人监管的质检流程减少了人工操作的参与,降低了人为失误的风险。自动化系统能够准确执行预定程序,避免了人为因素可能带来的操作失误或疏漏,提升了整个生产流程的安全性和可靠性。
5、缩短生产周期:自动化质检系统能够实时监测并即时反馈设备状态,从而减少了质检流程中的等待时间和中断。这一优化将大幅缩短生产周期,使得产品能够更快地投放市场,提升企业的市场响应速度。
二、项目方向
在生产环境中部署自动化质检设备,通过硬件设备采集待检设备的图像数据,并利用人工智能领域中的深度学习框架、卷积神经网络(CNN)以及 OpenCV库对图像进行处理和分析。通过这些技术可以从图像中提取设备的关键数据,并将其存储到本地工作表中。这不仅方便后续质检人员进行进一步比对,还能有效检测产品是否符合生产标准,确保每一台设备都达到预定的质量要求。通过这一自动化过程,质检流程更加精确和高效,极大地提升了生产的整体质量控制水平。
三、项目技术流程
设备质检设备主要采用是OCR技术,整个实现方案为:核心部分是收集需要质检设备的图像数据,然后进行清洗、分类、训练等操作获得目标模型,再使用PaddlePaddle深度学习框架使用PaddleOCR 和训练得到的模型对需要识别的设备进行识别,并存储得到的识别数据,软件部分使用 PySide6 实现整体应用的 UI搭建,最终部署到硬件设备上进行自动化之间操作,具体流程为:
(1)图像数据收集:首先,通过质检设备采集需要检测设备的图像数据。确保图像数据涵盖不同设备的多种状态和角度,以提供全面的数据基础。
(2)数据清洗与分类:对采集到的图像数据进行清洗和分类,去除噪声和无关信息,确保数据的准确性和质量。这一步骤是构建高效模型的重要前提。
(3)模型训练:使用 PaddlePaddle 深度学习框架对经过清洗和分类的数据进行训练,构建符合质检需求的目标模型。在训练过程中,通过不断优化模型参数,提高识别的准确性和鲁棒性。
(4)OCR识别:在模型训练完成后,利用PaddleOCR 以及训练得到的模型,对需要质检的设备进行实时识别。PaddleOCR将图像中的文字和字符信息准确地提取出来,并转化为可用的设备数据。
(5)数据存储与管理:将识别得到的设备数据存储到本地的数据库或工作表中,以便后续质检人员进行进一步的分析和比对。数据存储的过程确保了质检信息的完整性和可追溯性。
(6)软件UI 开发:使用 PySide6 框架开发质检系统的用户界面(UI)。UI 设计注重简洁易用,方便质检人员进行操作和查看识别结果,并能够实时监控和管理整个质检流程。
(7)自动化部署:在完成软件开发后,将整个系统部署到质检设备的硬件平台上,实现质检过程的全自动化操作。部署后的系统能够独立运行,实现无人值守的高效质检,持续监控和处理生产线上的设备数据。
(8)流程优化与维护:在系统实际运行过程中,持续收集反馈数据并进行模型优化和软件更新,确保质检流程的高效性和准确性。
核心流程
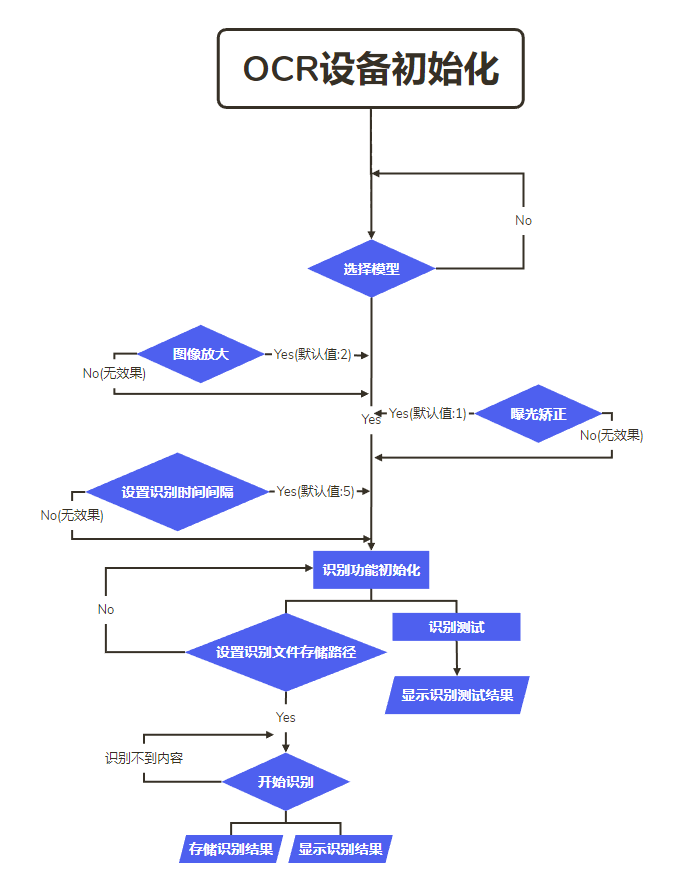
图 1 项目流程
四、技术方案
4.1、模型训练方案
1.数据准备:准备至少 5000张训练数据图片,并对每张图片进行标注。
2.数据划分:将训练数据划分为训练集(60%)、验证集(20%)、测试集(20%)。
3.训练参数调整:调整学习率、批量大小、训练轮数、优化器(如 Adam、SGD 等)、正则化参数、激活函数、损失函数等参数。
4.模型训练:开始训练模型,最终得到用于识别的OCR 模型。
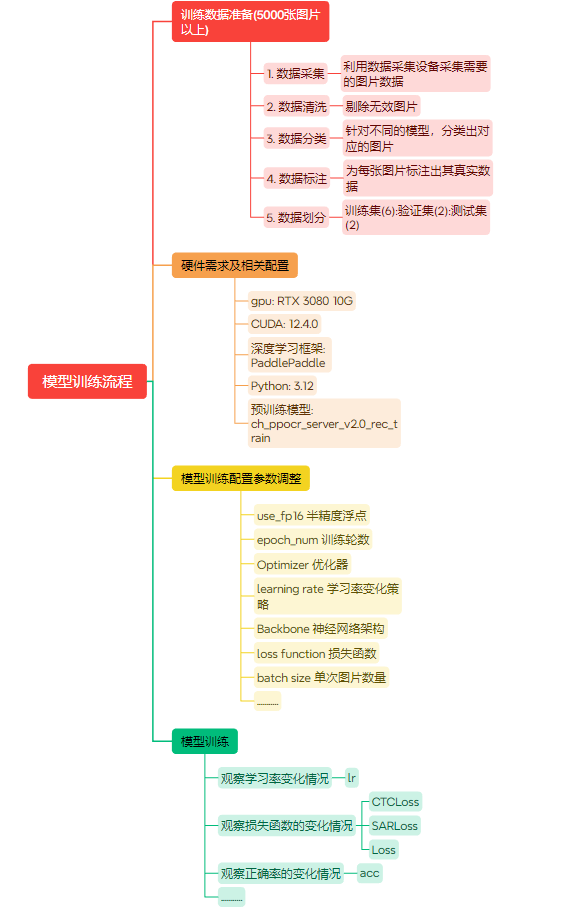
图 2 模型训练流程
4.2、设备应用功能
(1) 用户操作界面
用户界面中的按键布局合理规范,便于人机交互操作,整体布局如图 1所示。
整个界面的下半部分可为用户进行实时的识别结果监测,左下部分为当前实时显示区域内的所框选部分的识别结果,其中实时显示的区域来自树莓派设备的摄像头模块的对当前场景内容的实时捕捉整个界面的上半部分可为用户操作的功能,在界面中显示的所有基本功能为:开始识别,设置识别时间间隔,重新框选,识别测试选择识别文件存储路径,选择模型,图像处理功能为:像放大、曝光矫正,其他功能为:用户使用手册,添加模型。

图 3 用户操作界面
(2)选择识别文件存储路径
在用户开始进行识别操作之前,需要先选择识别结果存放的路径,因为将识别结果收集有利于后期的集中处理与分析。若用户没有选择正确的文件存储路径,那么就无法开始进行后续的识别操作,同时当用户点击开始识别时也会提醒用户重新进行选择。具体如图2所示。
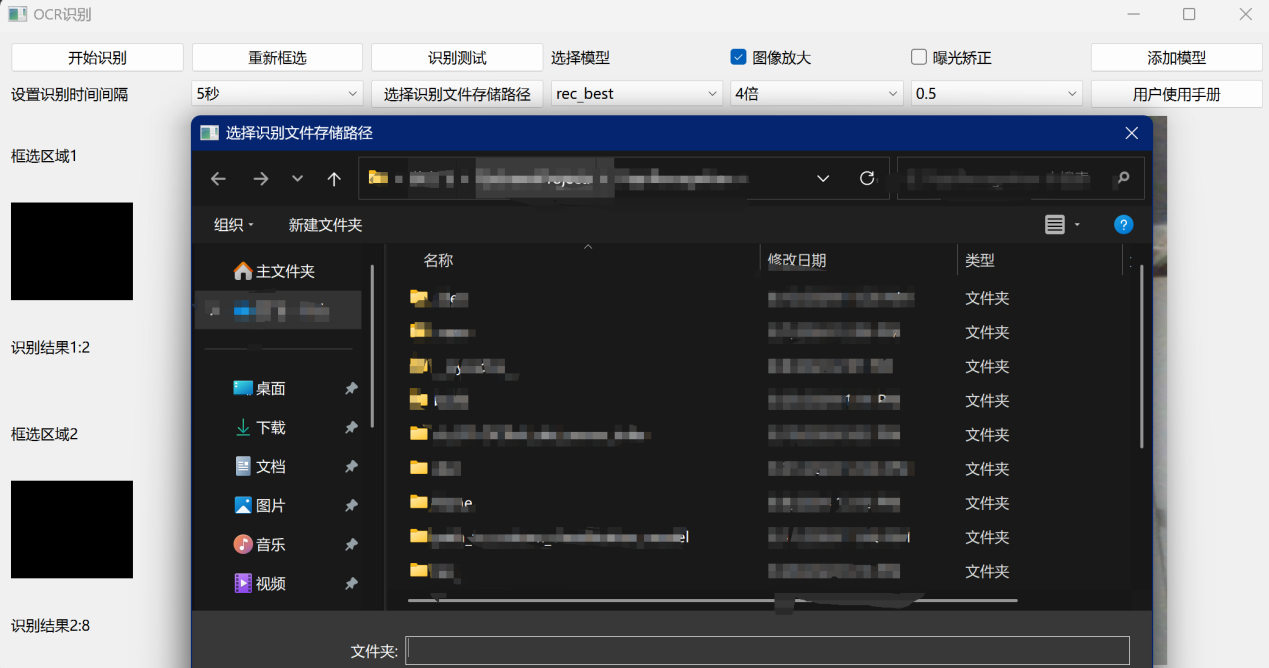
图 4 选择识别文件存储路径
(3)开始识别
当用户选择了正确的识别文件存储路径,那么就可以开始进行识别操作了。
首先用户需要对摄像头捕获的图像区域中需要识别的区域进行框选,当用户点击了开始识别按钮,设备就会以5秒/次的频率对用户所框选的区域进行内容识别,设备识别的结果会在摄像头视频流的左侧进行显示,若能够成功识别,则会在框选区域图的下方显示所识别的内容,若识别失败,则会显示空白内容,此时也会将所识别的图像进行存储,并按照每天一张表的规则,默认每天生成一张excel表,表的组成结构具体如图3所示,识别结果具体如图4所示。
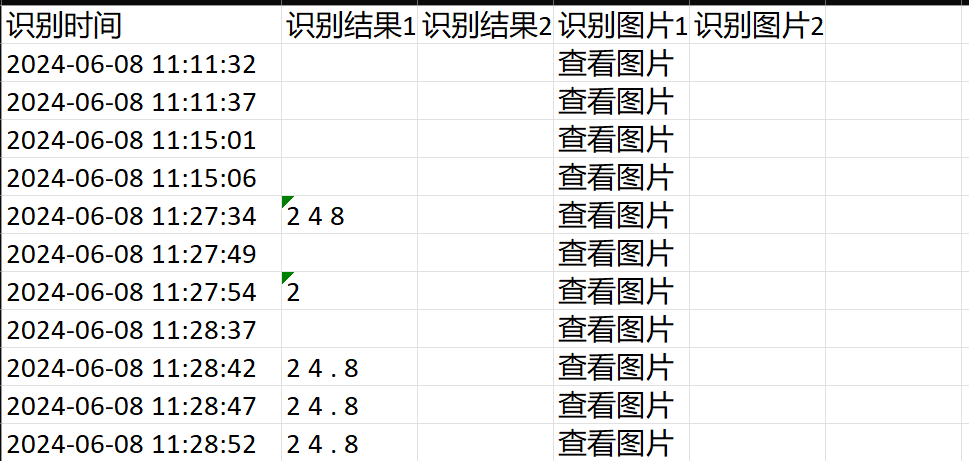
图 5 excel表结构
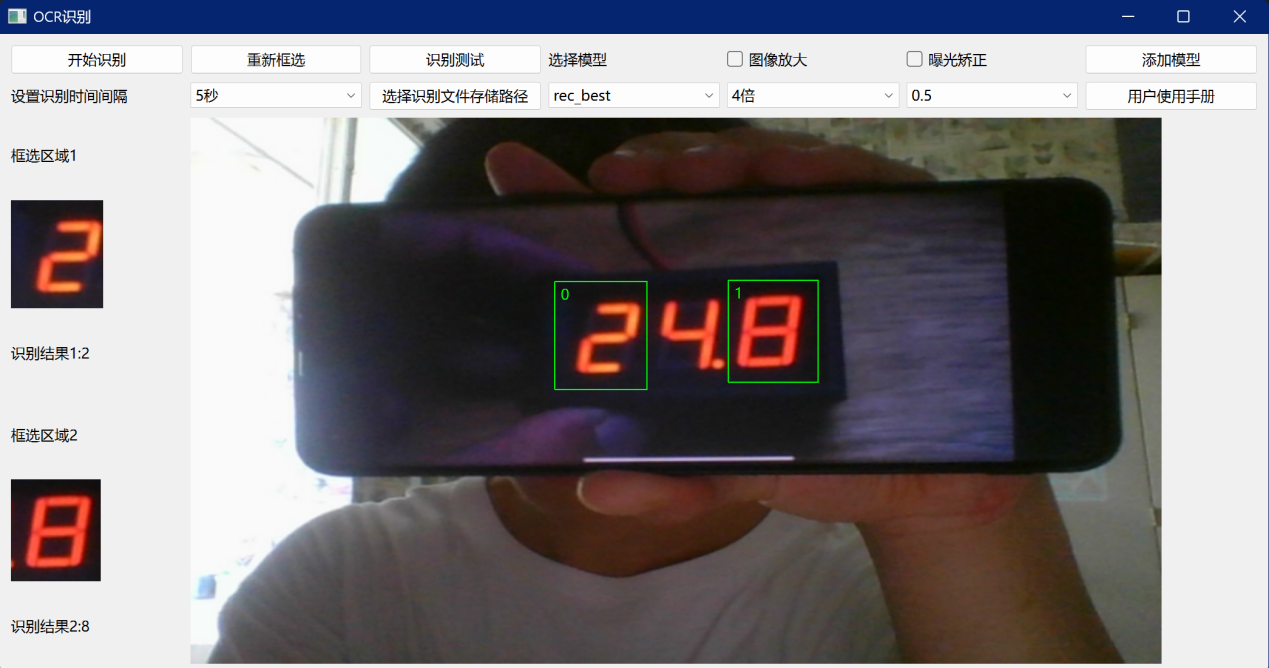
图 6 识别结果
(4)重新框选
当用户点击了重新框选按钮后,设备当前的识别操作会终止,并清空摄像头视频流显示区域的所有选框,摄像头视频流显示区域左侧的上次的框选内容也会被清空,此时设备会等待用户进行重新框选在进行识别操作。具体如图5所示。

图 7 重新框选
(5)设置识别时间间隔
当用户点击了开始识别按钮后,设备会以默认的5秒/次的频率对框选的区域进行识别,一般5秒/次的识别频率为测试所用的识别频率,用户可以根据当前产品生产线中生产情况来调整该选项,以适应不同的识别场景和识别需求。
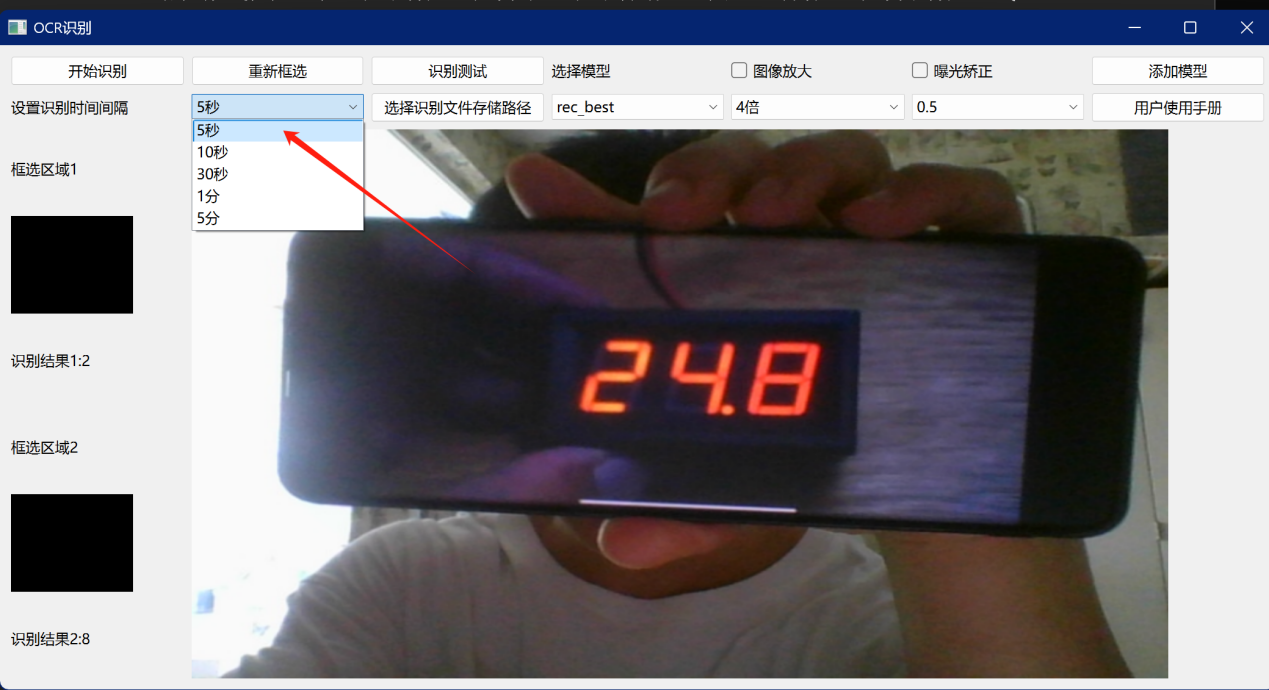
图 8 设置识别时间间隔
(6)识别测试
用户在使用识别测试功能时,不需要选择识别文件存储路径。当用户对摄像头视频流区域的需要识别的区域框选完毕后,可以直接对框选区域进行识别,并直接得到识别结果,此时的识别结果并不会进行存储,具体如图7所示。
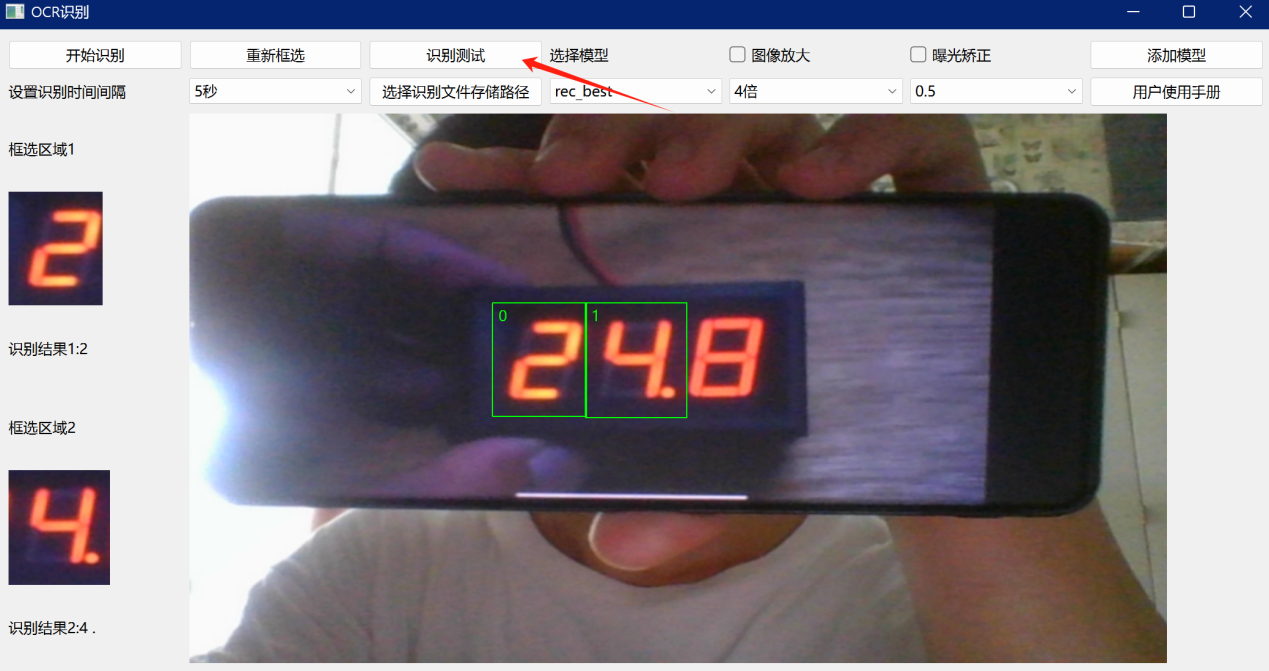
图 9 识别测试
(7)选择模型
此处用户可以针对不同的环境,不同的需求选择不同的识别模型,不同的识别模型的识别效果不同,针对数码管识别,可以选择现有的rec_best模型,若需要对其他文本内容进行识别,可以根据需要选择不同的模型进行测试,具体如图8所示。
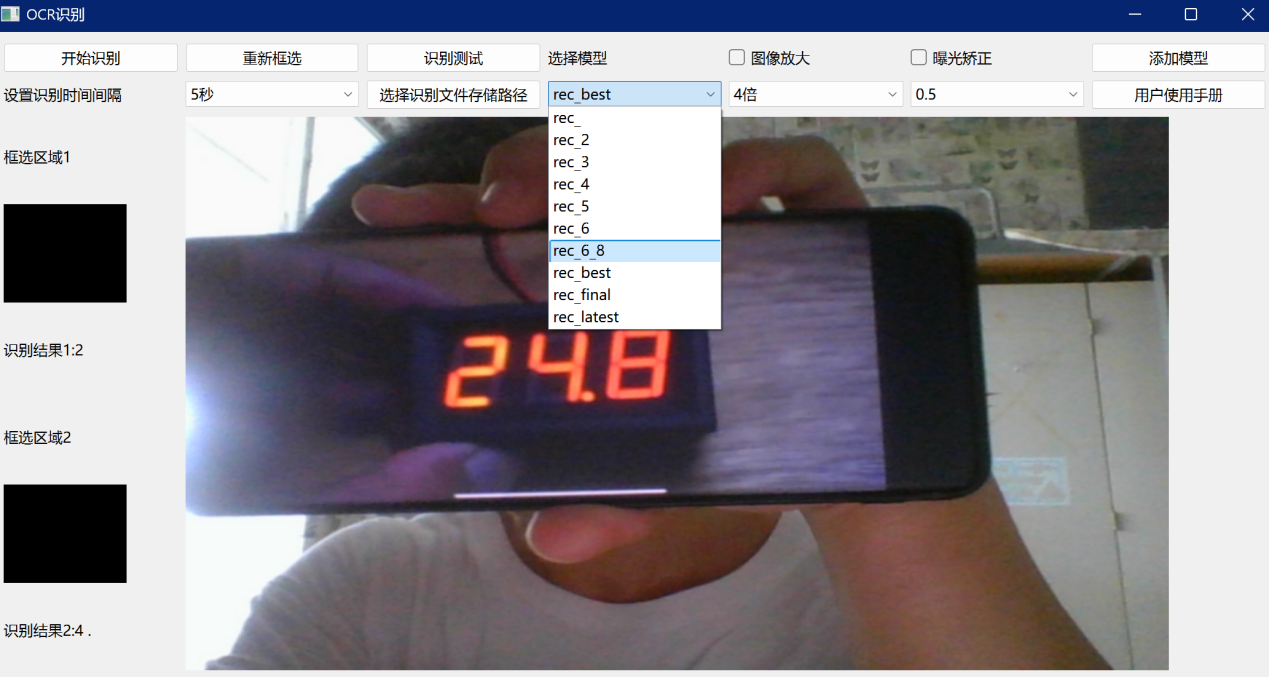
图 10 选择模型
(8)图像放大
为了提高内容识别的成功率,用户可以勾选图像放大选项,默认值是2倍,考虑到识别设备可能会离识别目标较远,在识别之前捕获到的图像像素较少,这样会使识别的成功率降低,所以在识别之前将图像进行放大是很有必要的,用户可以根据不同的场景进行选择不同的放大倍数,同时选择的倍数要合理适中,较大的放大倍数会极大影响识别的性能,从而导致识别的时间延长,产生不必要的时间成本,具体如图9所示。
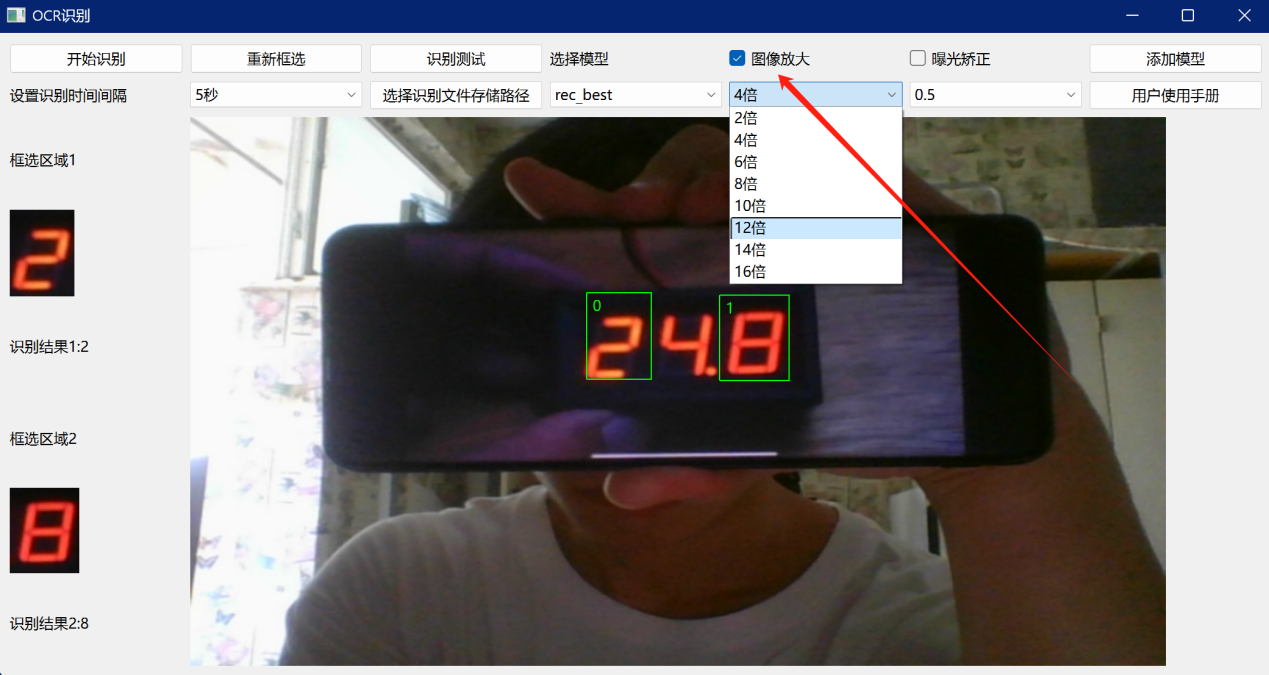
图 11 图像放大
(9)曝光矫正
考虑到识别设备要适应不同的环境,对于在强光环境下进行识别操作,可能会使识别的成功率降低,因此需要调整图像的曝光度,对其进行矫正至合适的范围才能够正常识别,同时提高识别的成功率。该选项的默认值为1.0,在强光环境下,可以适当调低该值,在昏暗环境下,可以适当调高该值。具体如图10所示。
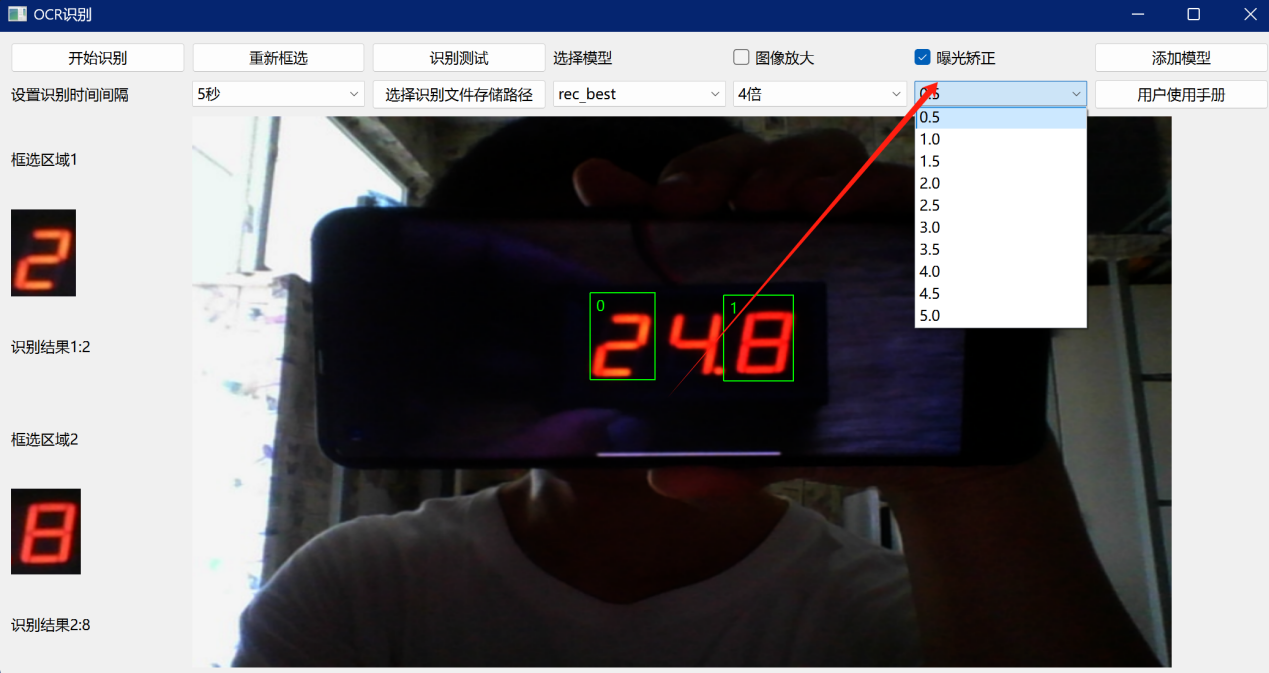
图 12 曝光矫正
(10)添加模型
考虑到后面会在更多不同环境对不同的内容进行识别,需要应用到其他的不同的模型,方便用户添加我们所提供的模型,用户可以点击添加模型按钮进行添加模型文件,模型文件组成:.pdiparams, .pdiparams.info, .pdmodel,具体如图11和图12所示。

图 13 添加模型

图 14 模型文件组成
(11)用户使用手册
为了指导用户进行操作,用户可以点击用户使用手册按钮,这里面会显示该识别设备的详细使用内容,如:如何在图片被识别之前进行相关的预处理操作、如何使用操作该设备等,具体如图13所示。
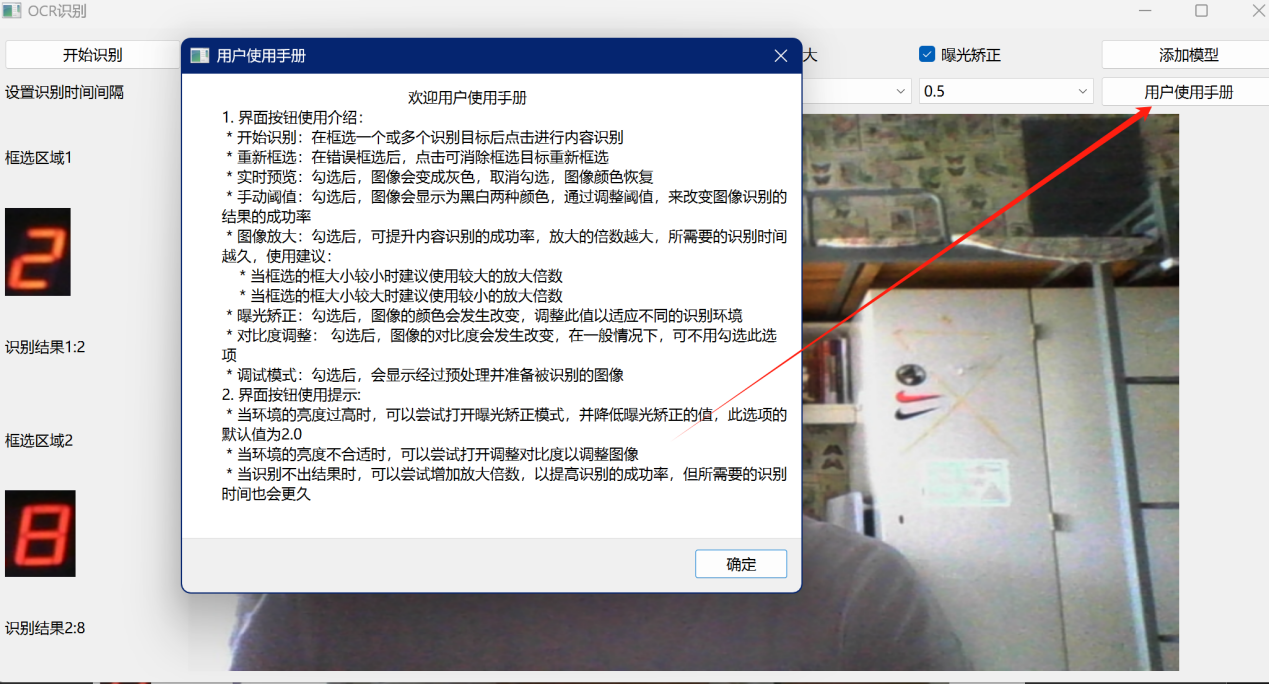
图 15 用户使用手册
五、设备详情
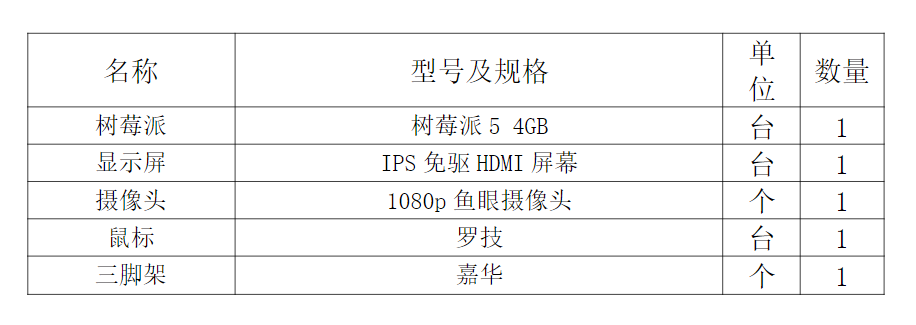
5.1、应用部署硬件设备
5.2、模型训练设备
(1)GPU设备:
使用NVIDIA A100 Tensor Core GPU,配备80GB HBM2e显存,专为AI和数据分析任务设计,能够提供高达312 TFLOPS的深度学习性能,显著加速大规模模型的训练。
备用选项:NVIDIA V100 Tensor Core GPU,配备32GB HBM2显存,适合大规模深度学习任务,并支持混合精度训练。
(2)CPU设备:
选择Intel Xeon Platinum 8276 CPU,配备28核/56线程,主频2.2GHz,最高睿频可达4.0GHz,适用于高并发计算任务。
备用选项:AMD EPYC 7742,配备64核/128线程,主频2.25GHz,最高睿频可达3.4GHz,具备卓越的多线程性能。
(3)内存配置:
配置512GB DDR4 ECC内存,保障在处理大规模数据和训练模型时的稳定性和性能。
备用选项:1TB DDR4 ECC内存,针对超大数据集的处理需求,进一步提升系统的内存容量。
(4)存储设备:
使用2TB NVMe SSD(如Samsung 980 PRO),具有高速读写能力,支持快速的数据加载和模型保存。
备用选项:4TB NVMe SSD(如Western Digital SN850),提供更大的存储空间,适应超大数据集和模型的存储需求。
(5)主板选择:
选择Supermicro X12SPA-T,支持Intel Xeon系列处理器,具有多个PCIe 4.0插槽,满足多GPU配置需求,具备可靠的扩展性和稳定性。
备用选项:ASUS ROG Zenith II Extreme Alpha,支持AMD EPYC处理器,提供全面的扩展选项和高性能连接,适合高负载计算环境。
(6)电源供应器:
使用Corsair AX1600i 1600W电源供应器,具有白金级别的效率和稳定性,专为高性能计算设备设计,确保所有组件在高负载下的正常运行。
(7)网络设备:
选择Mellanox ConnectX-6 EN,100GbE以太网卡,支持超高速网络连接,满足分布式训练和数据传输需求。
备用选项:Intel X710-DA2,10GbE以太网卡,提供可靠的网络连接性能,适用于多种数据中心环境。
(8)机箱与散热:
选择Fractal Design Define 7 XL,提供充足的内部空间和散热管理,适合高性能组件的安装。
备用选项:Corsair Obsidian Series 1000D,超大机箱,支持多GPU和水冷系统的安装,确保稳定的散热效果。
(9)软件环境:
使用Ubuntu 20.04 LTS操作系统,这是一款优化的Linux环境,为深度学习提供了稳定的支持。
深度学习框架使用PaddlePaddle 2.x,配合CUDA 11.x和cuDNN 8.x,确保与硬件的最佳兼容性和性能。
六、现场实际部署环境
现场设备系统OCR识别系统界面功能有开始识别、重新框选、识别测试、选择模型、图像放大等功能模块展示,如图6-1所示。
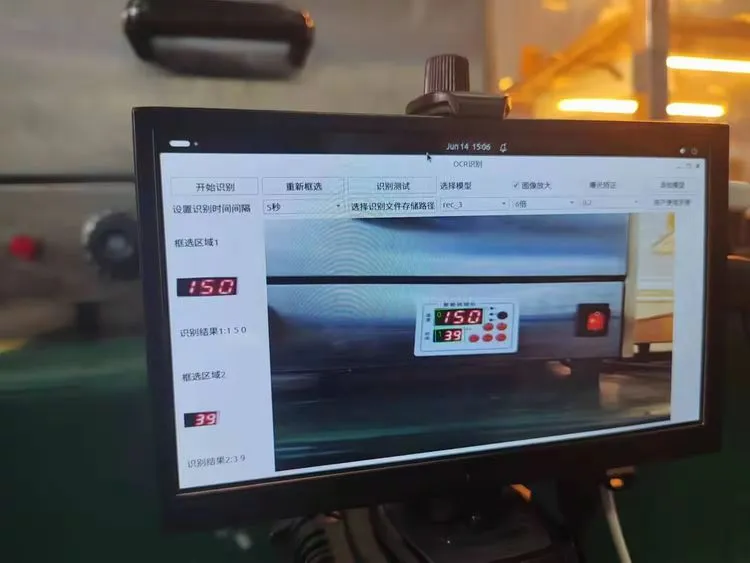
图 6-1 现场OCR识别系统界面
现场设备拍摄系统照片如图6-2所示。

图 6-2 现场设备状况
七、知识产权
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









