






AES 加密处理流程分为:
1、字节替换(SubBytes) , 2、行移位(ShiftRows), 3、列混合(MixColumns),4、轮密钥加(AddRoundKey)
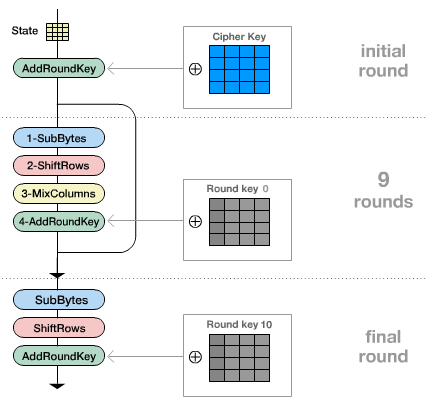
AES 解密处理的流程类似。按照这个流程,写出代码还不算复杂,就列混合的操作要多一些。这样写出来的代码,处理速度比较慢,可能在1 mb/s。所以需要把这个流程中耗时的操作优化一下,还要把比较简单的操作合并一下。
因为列混合的操作最多,所以首先优化列混合。
列混合中,要一直使用 GF(2^8) 域乘,所以我们可以在加密前,把所有的域乘结果缓存在一张表中,在实际加密中,用查表的方式,取代调用域乘函数。
域乘的代码:
unsigned char AES::field_multiply(const unsigned char x, const unsigned char y) {
int i;
unsigned char rem, tmp;
unsigned char result = 0;
rem = y;
for( i = 0; i < 8; i++) { //一个字节有8比特,所以循环8次,对于 AES ,循环4次就可以了,因为只用到后4比特
if( (x >> i ) & 0x01 ) {
result ^= rem;
}
tmp = rem << 1; //将GF(2)多项式相乘,变成一多项式不断乘 x,如果高位是1,则异或不可约多项式。
if( rem & 0x80 ) {
tmp ^= 0x1b;
}
rem = tmp;
}
return result;
}(发现 CRC 的计算也是用 GF(2),而且只是单纯的不断求余就可以了,把这个域乘改一下,就能算 CRC 了。)
加密列混合中的输入矩阵中有3个数:01、02、03,而数据的输入矩阵有256个可用的数:00 到 FF,那域乘的结果缓存下来会的到 3 x 256 大小的表。再加上解密的4个数:09、0B、0D、0E,那这张域乘表的大小为 7 x 256。
生成的表很大,但对 AES 加密处理的提速很明显,可以从以前的 1mb/s 提升到 3mb/s。
域乘填表的实现方式:我把 AES 写成了一个类,在 AES 类的构造函数中,调用填表函数,填表函数计算所有的域乘结果,并缓存在一个数组中,在列混合中,原先的域乘函数,替换为域乘结果数组,并用下标从数组中查到域乘的结果。
代码:
unsigned char AES::FieldBox[7][256];
void AES::fill_field_box()
{
int i, j;
unsigned char mix_box[] = {0x01, 0x02, 0x03, 0x09, 0x0b, 0x0d, 0x0e};
for(i = 0; i < 7; ++i)
{
for(j = 0; j < 256; ++j)
{
FieldBox[i][j] = AES::field_multiply(mix_box[i], (unsigned char) j );
}
}
}既然查表可以很显著的提升处理速度,那把其他操作一起拿来查表吧。
而 字节替换 已经是用查表方式实现的,那合并表。现在我们把 字节替换 的表,和域乘的表合并在一起。
原先是:MixColums( FieldMultiply [ MixMatirix ] [ SubBytes[ x ] ] )
现在要变为: MixColums( Table[ x ] )
要实现这个就比较简单了,先把域乘的表填完后: x = 00 To FF; Table[ x ] = FieldMultiplyTable [ MixMatrix ] [ SubBytes[x] ];
这样一种包含字节替换和域乘的表就生成了,处理速度又可以加快了。。。
但是这样简单的填完这张表,还不太好,这样填表并没有考虑列混合的特点,列混合是 两个 4x4 的输入矩阵相乘得到输出矩阵,那在算列混合的时候,相同的一个值,需要查4次表,其实可以把表改变表的排列方式,让列混合中的每个值只需查1次表,就得到一个输出矩阵。
列混合:
02 03 01 01 E6 B1 CA B7 a0 a4 a8 a12
01 02 03 01 X 1B 5B 12 7F = a1 a5 a9 a13
01 01 02 03 50 FD 7C 7B a2 a6 a10 a14
03 01 01 02 18 79 04 23 a3 a7 a11 a15
分解矩阵乘法:
a0 = 02xE6 + 03x1B + 01x50 + 01x18
a1 = 01xE6 + 02x1B + 03x50 + 01x18
a2 = 01xE6 + 01x1B + 02x50 + 03x18
a3 = 03xE6 + 01x1B + 01x50 + 02x18
这样规律就很明显了,只要将表结果和列混合矩阵的列一一对应,那查一次表,就可以得到要得到4个值,把这四个值相异或就得到一列结果了。
实现:我用两个三维数组缓存表,一个是加密用的表,一个是解密用的表,AesBox[4][256][4],InvAesBox[4][256][4]
代码实现:
unsigned char AES::AesBox[4][256][4];
unsigned char AES::InvAesBox[4][256][4];
void AES::fill_aes_box()
{
int i, j, k;
unsigned char mix_box[4][4] = {{1, 0, 0, 2}, {2, 1, 0, 0}, {0, 2, 1, 0}, {0, 0, 2, 1}};
unsigned char inv_mix_box[4][4] = {{6, 3, 5, 4}, {4, 6, 3, 5}, {5, 4, 6, 3}, {3, 5, 4, 6}};
for(i = 0; i < 4; ++i)
{
for(j = 0; j < 256; ++j)
{
for(k = 0; k < 4; ++k)
{
AesBox[i][j][k] = FieldBox[ mix_box[i][k] ] [ Sbox[j] ];
InvAesBox[i][j][k] = FieldBox[ inv_mix_box[i][k] ] [ j ]; //解密的话,还没想到什么方法合并S盒
}
}
}
}合并完后,测试发现 行移位(ShiftRows) 也很费时,不过 行移位 很简单,可以直接和列混合合并。
合并方式:把列混合展开,不用 for 循环,然后在展开的代码中,调整下标访问的顺序就可以了。
代码:(状态盒是列向填充,一维数组存储)
inline void AES::bit_xor(unsigned char* array1, unsigned char* array2, unsigned char* array3, unsigned char* array4, unsigned char* result)
{
result[0] = array1[0] ^ array2[0] ^ array3[0] ^ array4[0];
result[1] = array1[1] ^ array2[1] ^ array3[1] ^ array4[1];
result[2] = array1[2] ^ array2[2] ^ array3[2] ^ array4[2];
result[3] = array1[3] ^ array2[3] ^ array3[3] ^ array4[3];
}
void AES::mix_column(unsigned char* content, unsigned char* result)
{
bit_xor(AesBox[0][content[0]] , AesBox[1][content[5]], AesBox[2][content[10]], AesBox[3][content[15]], result);
result += 4;
bit_xor(AesBox[0][content[4]] , AesBox[1][content[9]], AesBox[2][content[14]], AesBox[3][content[3]], result);
result += 4;
bit_xor(AesBox[0][content[8]] , AesBox[1][content[13]], AesBox[2][content[2]], AesBox[3][content[7]], result);
result += 4;
bit_xor(AesBox[0][content[12]] , AesBox[1][content[1]], AesBox[2][content[6]], AesBox[3][content[11]], result);
}
void AES::inv_mix_column(unsigned char* content, unsigned char* result)
{
bit_xor(InvAesBox[0][content[0]] , InvAesBox[1][content[1]], InvAesBox[2][content[2]], InvAesBox[3][content[3]], result);
result += 4;
bit_xor(InvAesBox[0][content[4]] , InvAesBox[1][content[5]], InvAesBox[2][content[6]], InvAesBox[3][content[7]], result);
result += 4;
bit_xor(InvAesBox[0][content[8]] , InvAesBox[1][content[9]], InvAesBox[2][content[10]], InvAesBox[3][content[11]], result);
result += 4;
bit_xor(InvAesBox[0][content[12]] , InvAesBox[1][content[13]], InvAesBox[2][content[14]], InvAesBox[3][content[15]], result);
}AES优化处理过程后,处理速度可以在 6 mb/s 以上。。。















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









