






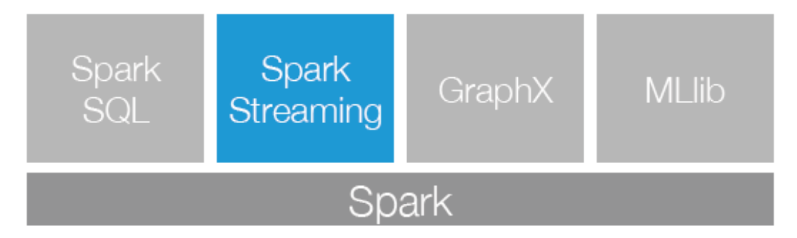
- Spark Streaming是Spark生态系统当中一个重要的框架,它建立在Spark Core之上,下面这幅图也可以看出Sparking Streaming在Spark生态系统中地位。
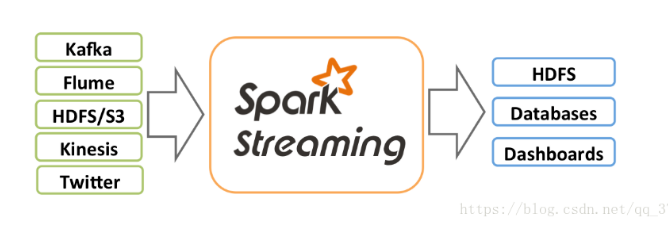
- Spark Streaming是Spark Core的扩展应用,它具有可扩展,高吞吐量,对于流数据的可容错性等特点。可以监控来自Kafka,Flume,HDFS。Kinesis,Twitter,ZeroMQ或者Scoket套接字的数据通过复杂的算法以及一系列的计算分析数据,并且可以将分析结果存入到HDFS文件系统,数据库以及前端页面中。

- 对于DStream如何理解呢?,离散流,表示连续的数据流,它是一系列连续的RDD,它是建立在Spark之上的不可变的,分布式数据集,在DStream中的每一个RDD包含着一定时间间隔的数据,
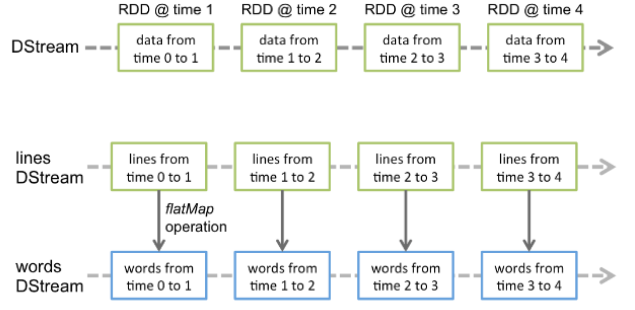
- 对于Spark Core它的核心就是RDD,对于Spark Streaming来说,它的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒数将数据流进行批量的划分。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等
我们都知道Spark Core在初始化时会生成一个SparkContext对象来对数据进行后续的处理,相对应的Spark Streaming会创建一个Streaming Context,它的底层是SparkContext,也就是说它会将任务提交给SparkContext来执行,这也很好的解释了DStream是一系列的RDD。当启动Spark Streaming应用的时候,首先会在一个节点的Executor上启动一个Receiver接受者,然后当从数据源写入数据的时候会被Receiver接收,接收到数据之后Receiver会将数据Split成很多个block,然后备份到各个节点(Replicate Blocks 容灾恢复),然后Receiver向StreamingContext进行块报告,说明数据在那几个节点的Executor上,接着在一定间隔时间内StreamingContext会将数据处理为RDD并且交给SparkContext划分到各个节点进行并行计算。
- sparkstream性能调优
- 通过有效地使用集群资源,减少了每一批数据的处理时间
- 设置正确的批处理大小,以便能够以接收到的速度处理数据批次(也就是说数据处理和数据摄入保持一致)
- 输入的数据必须序列化,流数据生成的RDD当我们调用持久化的时候序列化,序列化工具:kryo,avro
- 其中批处理时间应该小于批处理间隔
- GC调优,堆分为:老年代和新一代
与RDDs类似,转换允许修改输入DStream中的数据。DStreams支持许多在普通SparkRDD上可用的转换。一些常见的问题如下。
| 地图(漏斗) | 通过函数传递源DStream的每个元素来返回新的DStream漏斗. |
| 平面图(漏斗) | 类似于map,但是每个输入项都可以映射到0或多个输出项。 |
| 滤光器(漏斗) | 仅通过选择源DStream的记录返回一个新的DStream漏斗返回真。 |
| 再分割(非部分) | 通过创建更多或更少的分区来更改此DStream中的并行级别。 |
| 联合(异溪) | 返回一个新的dStream,其中包含源dStream和其他DStream. |
| 数数() | 通过计算源dStream的每个rdd中的元素数,返回一个新的单元素rdd的dStream。 |
| 减少(漏斗) | 通过使用函数聚合源dStream的每个rdd中的元素,返回一个新的单元素rdd的dStream。漏斗(它使用两个参数并返回一个)。函数应该是相联的和可交换的,这样才能并行计算。 |
| 计数ByValue() | 当调用类型为K的元素的DStream时,返回一个新的DStream(K,Long)对,其中每个键的值是其在源DStream的每个RDD中的频率。 |
| 还原剂ByKey(漏斗, [鼻烟壶]) | 当调用(K,V)对的DStream时,返回一个新的(K,V)对的DStream,其中每个键的值使用给定的约简函数进行聚合。注:默认情况下,这将使用SPark的默认并行任务数(本地模式为2,而在群集模式下,数目由config属性确定)。spark.default.parallelism)进行分组。您可以传递一个可选的numTasks参数设置不同数量的任务。 |
| 加入(异溪, [鼻烟壶]) | 当调用两个(K,V)和(K,W)对的DStreams时,返回一个新的(K,(V,W)对的dStream,每个键都包含所有的元素对。 |
| 协群(异溪, [鼻烟壶]) | 当调用(K,V)和(K,W)对的DStream时,返回一个新的dStream(K,Seq[V],Seq[W])元组。 |
| 变换(漏斗) | 通过将RDD到-RDD函数应用到源DStream的每个RDD中,返回一个新的DStream。这可以用于在DStream上执行任意的RDD操作。 |
| updateStateByKey(漏斗) | 返回一个新的“状态”dStream,其中每个键的状态通过在键的前一个状态上应用给定的函数和键的新值来更新。这可用于维护每个键的任意状态数据 |















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









