






http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id15
美丽汤中文文档~
前面的写在纸上了,有空再藤上来。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup ,Comment .
Tag:
Tag 对象与XML或HTML原生文档中的tag相同,即所有<div>,<a>,<p>,<h>等都属于Tag标签:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
- Tag有很多属性,同时它有最主要的两个方法能够对属性进行操作。
- name
这个方法的作用是“.name”时能够获取tag的名字。
tag.name # u'b'
注意:
如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档:
tag.name = "blockquote" tag # <blockquote class="boldest">Extremely bold</blockquote>
- Attributes
这个方法的作用是“.attrs” 能够获取tag的全部属性。
tag.attrs
# {u'class': u'boldest'}
2. Tag 的属性
- Tag有许多属性,tag的属性的操作方法与字典相同
- tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote>
tag['class']
# KeyError: 'class'
print(tag.get('class'))
# None
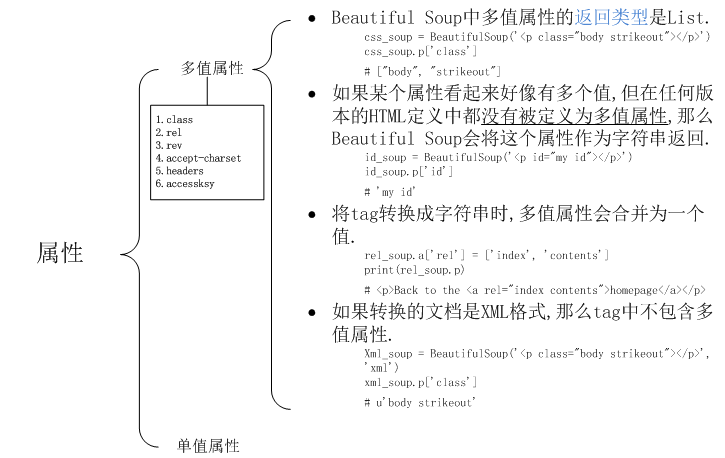
- 多值属性
NavigableString:
字符串常被包含在Tag(标签)内,如
![]()
Beautiful Soup用 NavigableString 类来包装tag中的字符串“Extremely bold”。
tag.string # u'Extremely bold' type(tag.string) # <class 'bs4.element.NavigableString'>
NavigableString字符串可以用unicode()方法转换成unicode字符串
unicode_string = unicode(tag.string) unicode_string # u'Extremely bold' type(unicode_string) # <type 'unicode'>
tag中的字符串不能编辑,但可以替换掉,使用replace_with()方法。
tag.string.replace_with("stringstring")















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









