






浅谈hadoop1.0与hadoop2.0的不同
这几天刚到公司报道,开始了我的实习历程。首先我的目标是对公司的hadoop平台进行学习,希望在短时间自己能够独立搭建,并且能明目个组件内部的交互原理。这两天我进行了hadoop1.0到hadoop2.0(cdh4及以后的版本均为hadoop2.0)过渡学习,现将两者不同总结如下。
hadoop1.0:
JobTracker:调度datanode上的工作,跨datanode工作,主————从。
TaskTracker:执行任务者。
namenode:主服务器,管理文件系统元数据。
SecondaryNamenode:周期检查点,清理任务(namenode的冷备节点)。
hadoop2.0的产生背景:
HDFS:
1.Namenode单点故障难以应用于在线场景。
2.Namenode压力过大且内存受限,影响系统的扩展性。
MAPREDUCE:
1.JobTracker单点故障,访问压力大影响系统扩展性。
2.难以支持除mapreduce之外的计算框架,如:spark storm Tez 等。
hadoop2.0:
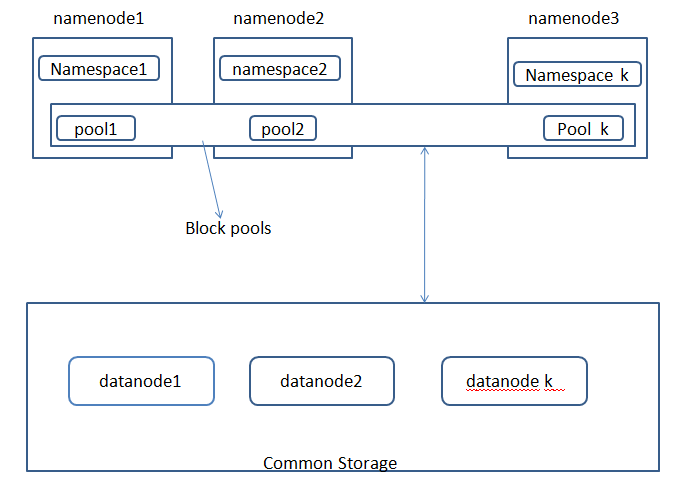
HDFS:Namenode Federation(联盟) HA(热备)。
MAPREDUCE:运行在YARN上的mapreduce。
YARN:资源管理系统,可支持多种运算框架。
JOURNALNODE:内存日志节点,存取元数据信息。
hadoop2.0 namenode的故障切换:
1.手动切换。
2.基于zookeeper的自动切换:FailoverController监控namenode,namenode挂掉后,ZKFC为namenode竞争锁,获得ZKFC锁的namenode变为Active。
多种共享存储系统可供选择:
1.NFS:Liunx系统的文件共享。
2.Qurom Journal Manager(QJM):多个journalnode构成的集群。
3.Bookeeper:雅虎推荐的方案。
hadoop2.0(cdh版本)使用QJM方案
基本原理:数据同时写入所有的Journalnode,多数写入成功则认为写成功。
一般配置奇数个Journalnode,越多容错性越好,比如:有三个Journalnode,只要两个写成功,则数据写成功,最多允许一个Journalnode挂掉。
HDFS(hadoop1.0):
由namespace(属于namenode)和BlockStorage组成,BolckStorage包括Block Management(属于namenode)和Physical Storage(datanode)。
局限性:
1.BlockStorage和namespace高耦合。
2.namenode扩展性。
3.性能:单个namenode仅支持约60K的task。
4.隔离性。
HDFS(hadoop2.0): Federation.
YARN: Yet Another Resource Negotiator
核心思想:将MRV1 中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
ResourceManager:负责整个集群的资源管理和调度。
ApplicationMaster:负责应用程序相关的事物,比如任务调度,任务监控和容错。
NodeManager:存在于每个datanode节点,负责某个datanode上具体的资源管理和分配,向ResourceManager汇报。
*每个应用程序对应一个ApplicationMaster。
YARN的引入使得多个计算框架可以运行在一个集群中。
MapReduce计算框架(hadoop1.0):
1.将计算过程分为两个阶段,map和reduce。
(1)map阶段并行处理输入数据。
(2)reduce阶段对map结果进行汇总。
2.shuffle连接map和reduce两个阶段。
(1)map Task 将数据写到本地磁盘。
(2)reduce Task从每个map Task上读取一份数据。
3.仅适合离线批处理
(1)具有很好的容错性和扩展性。
(2)适合简单的批处理任务。
4.缺点:启动开销大,过多使用磁盘导致效率低下。
MapReduce On YARN(hadoop2.0):
1.将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中。
2.基本功能模块:
(1)YARN:负责资源调度和管理。
(2)MRAppMaster负责任务切分,任务调度和容错等。
(3)MapTask和ReduceTask:任务驱动引擎,与MRv1一致。
3.每个MapReduce作业对应一个MRAppMaster。
4.MRAppMaster任务调度:
(1)YARN将资源分配给MRAppMaster。
(2)MRAppMaster进一步将资源分配给内部任务。
5.MrAppMaster容错:
(1)失败后,由YARN重新启动。
(2)任务失败后,MRAppMaster重新申请资源。
以上是我这两天的总结,如有不对之处,还望指正。















 3984
3984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









