






今天碰到一个问题:一个服务在凌晨2点到3点被频繁的调用,出现了一个小高峰,现在要查出到底是由于什么原因调用的。(也就是是因为在业务中被调用了,导致频繁的触发了这个服务,还是来自由用户端的操作,比如:有人在频繁的刷)。所以要查看是否这个服务
方法一:sed
一开始我上网找了一个命令,sed的用法:
sed -n “起始日期,终止日期” 日志文件
上面的命令的意思是匹配“字符串1”与“字符串2”直接的所有匹配到的信息。
例如:注意要使用这个命令的话,应该知道我们的日志文件的格式是什么?我们的日志文件:post_access_log.2016-09-21,经过查看,我们的日志文件的格式是下面的这样的:如下
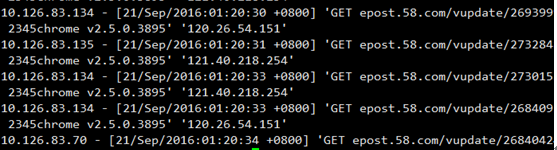
所以我写下了:
sed –n “/21/Sep/2016:02:00:00,/21/Sep/2016:03:00:00/p” post_access_log.2016-09-21
运行上面的命令报了一个错:"/"字符要转义,因为sed里面用的是正则表达式:

经过查文档发现,我们应该使用转义(如下):

但是然后可能是匹配不了,可能是正则写的不好,也可能是其它原因。
sed命令博客:http://blog.csdn.net/teamlet/article/details/38046437
http://www.iteye.com/topic/587673
方法二:awk
用vi命令进入日志文件post_access_log.2016-09-21,然后用”/搜索字符串”的方式搜索字符串。分别搜索”/02:00:00”与”/03:00:00”,记下这两个字符串在日志文件中的行号。
liunx vi下的命令:(在命令模式下,不是编辑模式下)
设置行号:”:set nu”
显示当前行号: “:nu”
跳到第几行: “:数字”
在vi下查找字符串: http://blog.csdn.net/huaishuming/article/details/9001312
上面拿到了两个行号的话,这样的话,再使用awk命令去获取日志信息:
awk '{if(NR>=10769 && NR<=30267) print $0}' post_access_log.2016-09-21 > aaa.txt
其中:NR代表行号,10769、30267具体行号,$0代表环境变量(下面的博客中有详细解释)。
注意:要获取行号的话,可以采用: nl post_access_log.2016-09-21 | grep "/02:00:00" 可以获取行号。
awk命令详解博客:http://www.cnblogs.com/emanlee/p/3327576.html
方法三:grep
由于我要找了是2点到3点的日志,我们可以这么获取:cat post_access_log.2016-09-21 | grep "21/Sep/2016:02" > bbb.txt
通过匹配"21/Sep/2016:02"这个字符串的话,就可以拿到2点到3点的日志,方便。这种获取方式就是通过获取数据的特点而采用的这种方式。
以上方法可以拿到日志,但是日志文件在liunx下,还是不好分析,所以应该把它拿到windows上,可以采用sz命令。
sz与rz命令的博客:http://blog.csdn.net/kobejayandy/article/details/13291655















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









