






一.写在前面的话
转眼又是周一,回想双休的日子,短暂而幸福,在阳光明媚的下午,可以自己做自己想做的任何事,惬意舒适,或读书,或运动,或音乐,当我们静下心来慢慢感受这些的时候,会突然发觉,原来生活是这么的幸福!有所求,有所感,就够啦!简简单单的生活其实就是最奢华的享受!忘记不开心的事,做自己生活的主导,摆脱烦恼,希望园子的朋友们,都能有一个好心情,不顺心的时候,出去走走,让情绪行走无边,放空自己!相信美好的事情终将发生!

二.视图
视图可以看作定义在SQL Server上的虚拟表.视图包含查询的一组结果集.常规视图本身并不存储实际的数据,而仅仅存储一个Select语句和所涉及表的metadata.利用视图,可以根据我们的需要,将多个表的数据进行组合,而且视图一旦建立,就一直存在,可以循环使用。
例如:假如我们要查找美国顾客的相关信息,那么就可以建立一个视图,每次只要查询美国顾客信息,只要根据视图名称查询就可以啦!同理,视图也需要先定义再查询。sql如下:
1 CREATE VIEW USA_cusomers
2 AS
3 (
4 SELECT * FROM
5 sales.customers
6 WHERE country='USA'
7 )定义完成以后,执行sql,那么命令就创建完成,然后就可以利用sql查询语句来查询美国的顾客信息。
1 SELECT custid,country FROM dbo.USA_cusomers;执行结果如图所示:

同时我们在sql的对象资源管理器中——》视图中可以看到,已经添加了名称为dbo.USA_cusomers的视图,那么可以循环利用这个视图进行查询。

如果想删除这个视图的话,可以利用sql语句drop进行操作:
1 DROP VIEW dbo.USA_cusomers;三.集合运算
集合预算主用用于对查询的结果进行操作。合集(Union)、交集(Intersect)、差集(Except),跟数学中的集合运算一样。
(1)合集,将所查询的两个或者多个结果集进行合并进行展示。
例如:我们要查询顾客表(sales.customers)和雇员表(hr.employees)里面所有的国家信息,那么就需要先查询出顾客表里面的所有国家,然后查询雇员表里面的所有国家,将两个结果集进行合并。sql如下:
1 SELECT country
2 FROM Sales.Customers
3 UNION ALL
4 SELECT country
5 FROM hr.Employees;
注意此处用的是union all,那么假如使用union结果又是什么了?
1 SELECT country
2 FROM Sales.Customers
3 UNION
4 SELECT country
5 FROM hr.Employees;
可以看到使用union all与union之间进行合集以后,结果集是不同的,其实这就说明了一点:
union all 不去重,包含所有的结果。
union 去重,显示的是去重以后的结果集。所以上述结果集显示21条,是去重后的结果。
(2)交集,将所查询的两个或者多个结果集进行交集展示。其中包含两个结果集中相同的部分。
同样我们将顾客表(sales.customers)和雇员表(hr.employees)里面所有的国家信息进行交集处理,看哪些国家既有顾客也有雇员。sql如下:
1 SELECT country
2 FROM Sales.Customers
3 intersect
4 SELECT country
5 FROM hr.Employees;
其中需要注意的是:intersect求交集,也是去重后的结果。
(3)差集,将所查询的两个或者多个结果集进行差集合并,找出其中一个集合在另一个集合中不存在的结果集。
例如:我们找出雇员表(hr.employees)里面的员工所在国家在顾客表(sales.customers)里面不存在的部分,也就是找出有顾客没有雇员的国家有哪些。sql如下:
1 SELECT country
2 FROM Sales.Customers
3 EXCEPT
4 SELECT country
5 FROM hr.Employees;
四.透视(pivot)
所谓的透视,也就是表的转置,在数据库操作中,有些时候我们遇到需要实现“行转列”的需求,统计每一阶段或者每一季度,每一星期的数量,可能数据库中存的数据格式是一行一行的,那么我们需要用一列展示具体的统计情况,这时候就需要用到透视(pivot)。

在这里我们首先创建一张表dbo.orders,同时往表里面插入一些数据。
1 IF OBJECT_ID('dbo.orders','U') IS NOT NULL
2 DROP TABLE dbo.orders;
3 CREATE TABLE dbo.orders
4 (
5 orderid int NOT NULL PRIMARY KEY,
6 empid int NOT NULL,
7 custid int NOT NULL,
8 orderdate datetime,
9 qty int
10 );
11
12 INSERT INTO dbo.orders(orderid,empid,custid,orderdate,qty)
13 VALUES (30001,3,1,'20070802',10),
14 (30002,2,4,'20070601',20),
15 (10001,4,5,'20070802',30),
16 (20001,5,2,'20070802',40),
17 (40001,3,2,'20070802',50),
18 (30006,5,6,'20070802',50),
19 (30008,4,8,'20070802',60),
20 (60001,6,1,'20070802',70)1 SELECT * FROM dbo.orders查询表数据有:

现在假如有一个需求,要求出每位顾客所消费的金额,根据常规想法,我们可以根据顾客id进行分组,然后用聚合函数sum求和,sql语句如下:
1 SELECT empid,SUM(qty) AS N'顾客消费金额'
2 FROM dbo.orders
3 GROUP BY empid;
但是我们现在想将顾客消费金额变成一列,也就是行转列,该怎么考虑了,在这里我们先用传统的方式,用到case when,然后根据case when条件进行一次求和。sql语句如下:
1 SELECT empid,
2 SUM(CASE when empid=2 THEN qty end) AS N'2号顾客消费金额',
3 SUM(CASE when empid=3THEN qty end) AS N'3号顾客消费金额',
4 SUM(CASE when empid=4 THEN qty end) AS N'4号顾客消费金额',
5 SUM(CASE when empid=5 THEN qty end) AS N'5号顾客消费金额',
6 SUM(CASE when empid=6 THEN qty end) AS N'6号顾客消费金额'
7 FROM dbo.orders
8 GROUP BY empid;其执行结果如图:

从执行结果图可以看出,已经将顾客ID转换到一行显示,每位顾客的消费在列中都可以看到。但是这里我们采取新的一种方式,显得更好用,那就是pivot方式。只不过pivot帮我们做了很多的转换工作而已,这里我们只关注pivot如何用。对于上面的需求,我们可以这样使用pivot:
1 SELECT empid,[1],[2],[4],[6],[8]
2 FROM
3 (
4 --只返回pivot中用到的列
5 SELECT empid,qty,custid
6 FROM dbo.orders
7 ) AS t
8 PIVOT (
9 SUM(t.qty) FOR t.custid IN ([1],[2],[4],[6],[8])--做列名称
10 ) AS P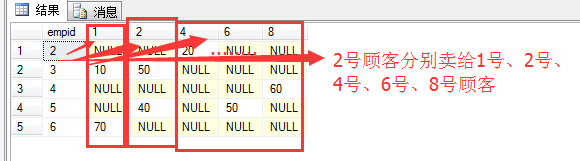
希望各位大牛给出指导,不当之处虚心接受学习!谢谢!















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









