






- hdfs文件读取过程
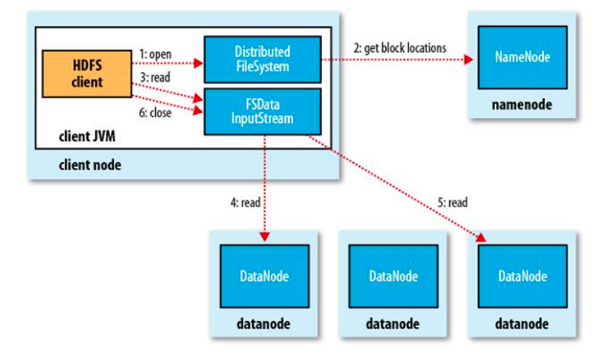
过程描述:
(1)客户端调用FileSyste对象的open()方法在分布式文件系统中打开要读取的文件。
(2)分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置。
(3)分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法。
(4)DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端。
(5) 到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode。
(6)客户端完成读取,对FSDataInputStream调用close()方法关闭连接。
- hdfs文件写入过程
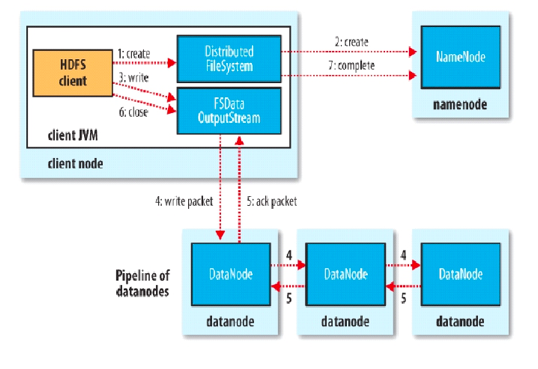
- 过程描述:
写文件过程分析:
(1) 客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
(2) 分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件。
(3)Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信,客户端开始写入数据。
(4)FSDataOutputStream将数据分成一个一个的数据包,写入内部队列“数据队列”,DataStreamer负责将数据包依次流式传输到由一组namenode构成的管线中。
(5)DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除。
(6)客户端完成数据的写入,对数据流调用close()方法。
(7)namenode确认完成
- Block的副本放置策略
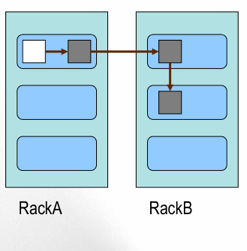
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点















 4471
4471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









