






 本文介绍了一个用于网络资源获取的工具类HttpHelper,详细展示了其从初步搭建到逐步完善的过程,包括添加用户代理、Cookie、超时设置、压缩处理等功能,并引入了代理服务器的概念以应对请求被频繁拒绝的问题。
本文介绍了一个用于网络资源获取的工具类HttpHelper,详细展示了其从初步搭建到逐步完善的过程,包括添加用户代理、Cookie、超时设置、压缩处理等功能,并引入了代理服务器的概念以应对请求被频繁拒绝的问题。
什么是Httphelper?
httpelpers是一个封装好拿来获取网络上资源的工具类。因为是用http协议,故取名httphelper。
httphelper出现的背景
使用WebClient可以很方便获取网络上的资源,例如
WebClient client = new WebClient();
string html= client.DownloadString("https://www.baidu.com/");这样就可以拿到百度首页的的源代码,由于WebClient封装性太强,有时候不大灵活,需要对底层有更细致的把控,这个时候就需要打造自己的网络资源获取工具了;
HttpHelper初级
现在着手打造自己的下载工具,刚开始时候长这样
public class HttpHelp
{
public static string DownLoadString(string url)
{
string Source = string.Empty; HttpWebRequest request= (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
return Source;
}
}
程序总会出现各种异常的,这个时候加个Try catch语句
public class HttpHelp
{
public static string DownLoadString(string url)
{
string Source = string.Empty;
try{
HttpWebRequest request= (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}
}请求资源是I/O密集型,特别耗时,这个时候需要异步
public static async Task<string> DownLoadString(string url)
{
return await Task<string>.Run(() =>
{
string Source = string.Empty;
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream stream = response.GetResponseStream())
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
});
} HttpHelper完善
为了欺骗服务器,让服务器认为这个请求是浏览器发出的
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0";有些资源是需要权限的,这个时候要伪装成某个用户,http协议是无状态的,标记信息都在cookie上面,给请求加上cookie
request.Headers.Add("Cookie", "这里填cookie,从浏览器上面拷贝")再完善下,设定个超时吧
request.Timeout = 5000;有些网站提供资源是GZIP压缩,这样可以节省带宽,所以请求头再加个
request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
相应的得到相应流要有相对应的解压,这个时候httphelper变成这样了
public static string DownLoadString(string url)
{
string Source = string.Empty;
try{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0";
request.Headers.Add("Cookie", "这里是Cookie");
request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
request.KeepAlive = true;//启用长连接
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream dataStream = response.GetResponseStream())
{
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
}
request.Abort();
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}
请求态度会被服务器拒绝,返回429。这个时候需要设置代理,我们的请求会提交到代理服务器,代理服务器会向目标服务器请求,得到的响应由代理服务器返回给我们。只要不断切换代理,服务器不会因为请求太频繁而拒绝掉程序的请求var proxy = new WebProxy(“Adress”,8080);//后面是端口号
request.Proxy = proxy;//为httpwebrequest设置代理原理是
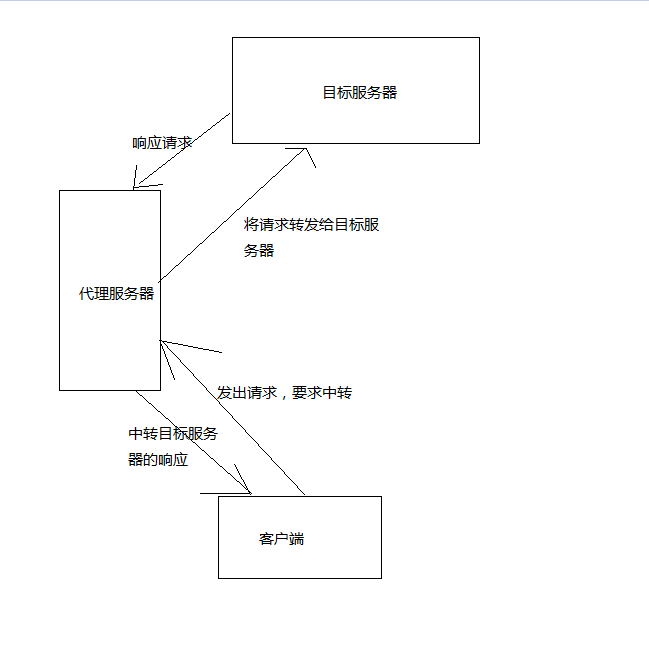
我使用的是一家叫阿布云的服务商,提供的服务比较稳定优质,就是有点贵,根据阿布云官网的示例代理,我将httphelp修改成了
public static string DownLoadString(string url)
{
string Source = string.Empty;
try
{
string proxyHost = "http://proxy.abuyun.com";
string proxyPort = "9020";
// 代理隧道验证信息
string proxyUser = "H71T6AMK7GREN0JD";
string proxyPass = "D3F01F3AEFE4E45A";
var proxy = new WebProxy();
proxy.Address = new Uri(string.Format("{0}:{1}", proxyHost, proxyPort));
proxy.Credentials = new NetworkCredential(proxyUser, proxyPass);
ServicePointManager.Expect100Continue = false;
Stopwatch watch = new Stopwatch();
watch.Start();
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0";
request.Headers.Add("Cookie", "q_c1=17d0e600b6974387b1bc3a0117d21c50|1483348502000|1483348502000; l_cap_id=\"NjVhNGM1ODhmZWJlNDE4MDk1OTRlMDU0NTRmMmU3NzY=|1483348502|ce7951227c840cde8d8356526547cfeddece44a8\"; cap_id=\"Y2QyODU3MTg0NTViNDIwZTk4YmRhMTk5YWI5MTY1MGQ=|1483348502|892544d61b1d04265cad1ad172a5911eaf47ebe2\"; d_c0=\"AEAC7iaxFwuPToc2DY_goP_H5QnNPxMReuU=|1483348504\"; r_cap_id=\"ODA5ZDI5YTQ1M2E2NDc1OWJlMjk0Nzk1ZWY4ZjQ1NTU=|1483348505|00d0a93219de27de0e9dfa2c2a6cbe0cbf7c0a36\"; _zap=ea616f49-be5d-4f94-98d8-fdec8f7d277b; __utma=51854390.2059985006.1483348508.1483348508.1483416071.2; __utmz=51854390.1483416071.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmv=51854390.100-1|2=registration_date=20160110=1^3=entry_date=20160110=1; login=\"ZDczZTgyMmUzZjY1NDQ1YTkzMDk2MTk5MTNjMDIxMTM=|1483348523|f1e570e14ceed6b61720c413dd8663527aea78fc\"; z_c0=Mi4wQUJCS0c2ZmVTUWtBUUFMdUpyRVhDeGNBQUFCaEFsVk5LNmVSV0FEc1hkcFV2YUdOaDExVjBTLU1KNVZ6OFRYcC1n|1483416083|3e5d60bef695bd722a95aea50f066c394cfcba9d; _xsrf=87b1049f227fe734a9577ec9f76342b3; __utmb=51854390.0.10.1483416071; __utmc=51854390");
request.Headers.Add("Upgrade-Insecure-Requests", "1");
request.Headers.Add("Cache-Control", "no-cach");
request.Accept = "*/*";
request.Method = "GET";
request.Referer = "https://www.zhihu.com/";
request.Headers.Add("Accept-Encoding", " gzip, deflate, br");
request.KeepAlive = true;//启用长连接
request.Proxy = proxy;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream dataStream = response.GetResponseStream())
{
if (response.ContentEncoding.ToLower().Contains("gzip"))//解压
{
using (GZipStream stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else if (response.ContentEncoding.ToLower().Contains("deflate"))//解压
{
using (DeflateStream stream = new DeflateStream(response.GetResponseStream(), CompressionMode.Decompress))
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
else
{
using (Stream stream = response.GetResponseStream())//原始
{
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8))
{
Source = reader.ReadToEnd();
}
}
}
}
}
request.Abort();
watch.Stop();
Console.WriteLine("请求网页用了{0}毫秒", watch.ElapsedMilliseconds.ToString());
}
catch
{
Console.WriteLine("出错了,请求的URL为{0}", url);
}
return Source;
}















 2144
2144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









