









 本文探讨了JSON在Web开发中的广泛使用及其可能导致的性能瓶颈,重点介绍了如何通过优化数据结构、选择更高效的序列化格式(如Protobuf、MessagePack、BSON和Avro)以及服务器端缓存来提高速度和响应能力。
本文探讨了JSON在Web开发中的广泛使用及其可能导致的性能瓶颈,重点介绍了如何通过优化数据结构、选择更高效的序列化格式(如Protobuf、MessagePack、BSON和Avro)以及服务器端缓存来提高速度和响应能力。
是的, 你没听错! 网络开发中无处不在的数据交换格式JSON, 可能会拖慢你的应用程序. 在这个速度和响应速度至上的世界里, 检查 JSON 的性能影响至关重要, 而我们对此却常常忽略. 在本博客中, 我们将深入探讨 JSON 成为应用程序瓶颈的原因, 并探索更快的替代方案和优化技术, 以确保你的应用程序以最佳状态运行.
JSON 是什么? 为何我要关注这个问题?
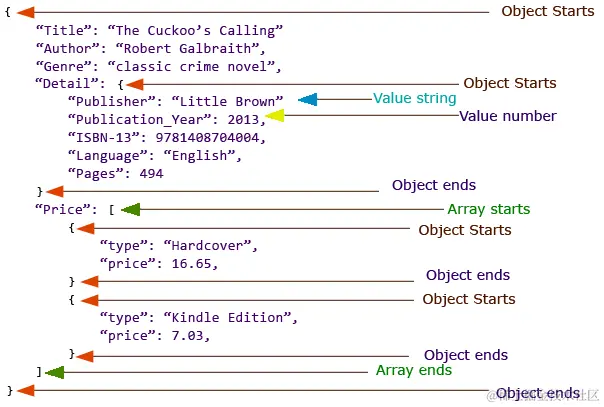
JSON是JavaScript Object Notation的缩写, 是一种轻量级数据交换格式, 已成为Web应用中传输和存储数据的首选. 它的简洁性和人类可读格式使人类和机器都能轻松使用. 但是, 为什么要在Web开发项目中关注 JSON 呢?
JSON 是应用中数据的粘合剂. 它是服务器和客户端之间进行数据通信的语言, 也是数据库和配置文件中存储数据的格式.
JSON 的流行以及人们使用它的原因…
JSON 在Web开发领域的受欢迎程度怎么强调都不为过. 它已成为数据交换的事实标准, 这其中有几个令人信服的原因:
它易于使用!
- 人类可读格式: JSON 使用简单明了, 基于文本的结构, 开发人员和非开发人员都能轻松阅读和理解. 这种人类可读的格式增强了协作, 简化了调试.
- 语言无关性: JSON 与任何特定的编程语言无关. 它是一种通用的数据格式, 几乎所有现代编程语言都能对其进行解析和生成, 因此它具有很强的通用性.
- 数据结构一致性: JSON 使用键值对, 数组和嵌套对象来实现数据结构的一致性. 这种一致性使其具有可预测性, 便于在各种编程场景中使用.
- 支持浏览器: 网络浏览器原生支持 JSON, 允许Web应用与服务器进行无缝通信. 这种本地支持极大地促进了 JSON 在Web开发中的应用.
- JSON API: 许多网络服务和应用接口默认以 JSON 格式提供数据. 这进一步巩固了 JSON 在Web开发中作为数据交换首选的地位.
- JSON Schema: 开发人员可以使用 JSON 模式来定义和验证 JSON 数据的结构, 从而为应用增加了一层额外的清晰度和可靠性.
鉴于这些优势, 难怪全球的开发人员都依赖 JSON 来满足他们的数据交换需求. 然而, 随着我们在本博客的深入探讨, 我们将发现与 JSON 相关的潜在性能挑战, 以及如何有效解决这些挑战.
速度需求
🚀🚀🚀
应用的速度和响应的重要性
在当今快节奏的数字环境中, 应用的速度和响应能力是不可或缺的. 用户希望在Web和移动应用中即时获取信息, 快速交互和无缝体验. 对速度的这种要求是由以下几个因素驱动的:
- 用户期望: 用户已习惯于从数字互动中获得闪电般快速的响应. 他们不想等待网页的加载或应用的响应. 哪怕是几秒钟的延迟, 都会导致用户产生挫败感并放弃使用.
- 竞争优势: 速度可以成为重要的竞争优势. 反应迅速的应用往往比反应迟缓的应用更能吸引和留住用户.
- 搜索引擎排名: 谷歌等搜索引擎将网页速度视为排名因素. 加载速度更快的网站往往在搜索结果中排名靠前, 从而提高知名度和流量.
- 转化率: 电子商务网站尤其清楚速度对转化率的影响. 网站速度越快, 转换率越高, 从而增加收入.
- 移动性能: 随着移动设备的普及, 对速度的需求变得更加重要. 移动用户的带宽和处理能力往往有限, 因此快速的应用性能是必要的.
JSON 会拖慢我们的应用吗?
现在, 让我们来讨论核心问题: JSON 是否会拖慢我们的应用?
如前所述, JSON 是一种非常流行的数据交换格式. 它灵活, 易用, 并得到广泛支持. 然而, 这种广泛的应用并不意味着它不会面临性能挑战.
在某些情况下, JSON 可能是导致应用慢的罪魁祸首. 解析 JSON 数据的过程, 尤其是在处理大型或复杂结构时, 可能会耗费宝贵的毫秒时间. 此外, 低效的序列化和反序列化也会影响应用的整体性能.
在接下来的内容中, 我们将探讨 JSON 成为应用瓶颈的具体原因, 更重要的是, 探讨如何缓解这些问题. 在深入探讨的过程中, 请记住我们的目标不是诋毁 JSON, 而是了解其局限性并发现优化其性能的策略, 以追求更快, 反应更灵敏的应用.
LinkedIn将Protocal Buffers与Rest.li集成以提高微服务性能| LinkedIn工程
JSON 为什么会变慢
尽管 JSON 被广泛使用, 但它也难逃性能挑战. 让我们来探究 JSON 可能会变慢的原因, 并理解为什么 JSON 并不总是数据交换的最佳选择.
1. 解析带来的开销
当 JSON 数据到达应用时, 它必须经过解析过程才能转换成可用的数据结构. 解析过程可能相对较慢, 尤其是在处理大量或深度嵌套的 JSON 数据时.
2. 序列化和反序列化
JSON 要求在从客户端向服务器发送数据时进行序列化(将对象编码为字符串), 并在接收数据时进行反序列化(将字符串转换回可用对象). 这些步骤会带来开销, 影响应用的整体速度.
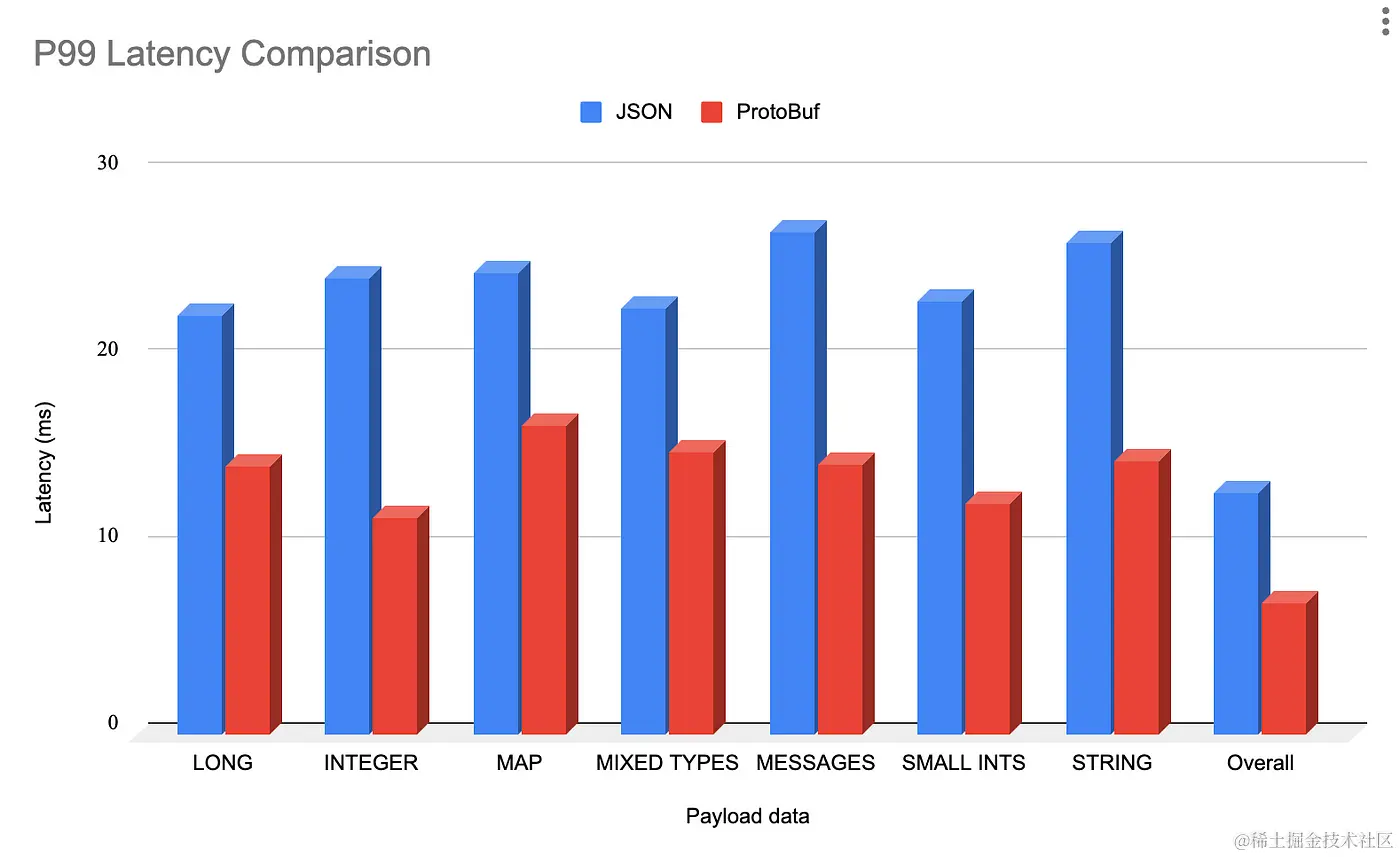
在微服务架构的世界里, JSON 通常用于在服务之间传递消息. 但是, 很关键的是, 我们必须认识到, JSON 消息需要序列化和反序列化, 这两个过程会带来巨大的开销.
在有大量微服务不断通信的场景中, 这种开销可能会增加, 并有可能使应用变慢, 以至于影响用户体验.
我们面临的第二个挑战是, 由于 JSON 的文本性质, 序列化和反序列化的延迟和吞吐量都不理想. — LinkedIn
序列化和反序列化
3. 字符串操作
JSON 基于文本, 在连接和解析等操作中严重依赖字符串操作. 与处理二进制数据相比, 处理字符串的速度会慢一些.
4. 缺乏数据类型
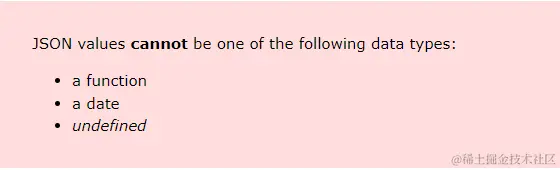
JSON 的数据类型(如字符串, 数字, 布尔值)非常有限. 复杂的数据结构可能需要效率较低的表示法, 从而导致内存使用量增加和处理速度减慢.
5. 冗余
JSON 的人类可读性设计可能会导致冗余. 不需要的键和重复的结构增加了有效载荷的大小, 导致数据传输时间延长.
第一个挑战是 JSON 是一种文本格式, 往往比较冗余. 这导致网络带宽使用量增加, 更高的延迟, 效果并不理想. — LinkedIn
6. 不支持二进制
JSON 缺乏对二进制数据的本地支持. 在处理二进制数据时, 开发人员通常需要将其编解码为文本, 而这可能会降低效率.
7. 深度嵌套
在某些情况下, JSON 数据可能是深嵌套的, 需要递归解析和遍历. 这种计算复杂性会降低应用的运行速度, 尤其是在没有优化的情况下.
JSON的替代方案
虽然 JSON 是一种通用的数据交换格式, 但由于其在某些情况下的性能限制, 人们开始探索更快的替代格式. 让我们深入探讨其中的一些替代方案, 了解何时以及为何选择它们:
1. Protocol Buffers(protobuf)
Protocal Buffers通常被称为protobuf, 是由谷歌开发的一种二进制序列化格式. 它的设计宗旨是高效, 紧凑和快速. Protobuf 的二进制性质使其在序列化和反序列化方面的速度明显快于 JSON.
- 何时选择: 当你需要高性能的数据交换时, 尤其是在微服务架构, 物联网应用或网络带宽有限的情况下, 请考虑使用Protobuf.
GitHub - vaishnav-mk/protobuf-example
2. MessagePack
MessagePack 是另一种二进制序列化格式, 以速度快, 结构紧凑而著称. 它比 JSON 更有效率, 同时与各种编程语言保持兼容.
- 何时选择: 当你需要在速度和跨语言兼容性之间取得平衡时, MessagePack 是一个不错的选择. 它适用于实时应用和对减少数据大小至关重要的情况.
3. BSON (二进制 JSON)
BSON 或二进制 JSON 是一种从 JSON 衍生出来的二进制编码格式. 它保留了 JSON 的灵活性, 同时通过二进制编码提高了性能. BSON 常用于 MongoDB 等数据库.
- 何时选择: 如果你正在使用 MongoDB, 或者需要一种格式来弥补 JSON 和二进制效率之间的差距, 那么 BSON 是一个很有价值的选择.
4. Apache Avro
Apache Avro 是一个数据序列化框架, 专注于提供一种紧凑的二进制格式. 它基于schema, 可实现高效的数据编解码.
- 何时选择: Avro 适用于schema演进非常重要的情况, 如数据存储, 以及需要在速度和数据结构灵活性之间取得平衡的情况.
与 JSON 相比, 这些替代方案提供了不同程度的性能改进, 具体选择取决于你的具体使用情况. 通过考虑这些替代方案, 你可以优化应用的数据交换流程, 确保将速度和效率放在开发工作的首位.
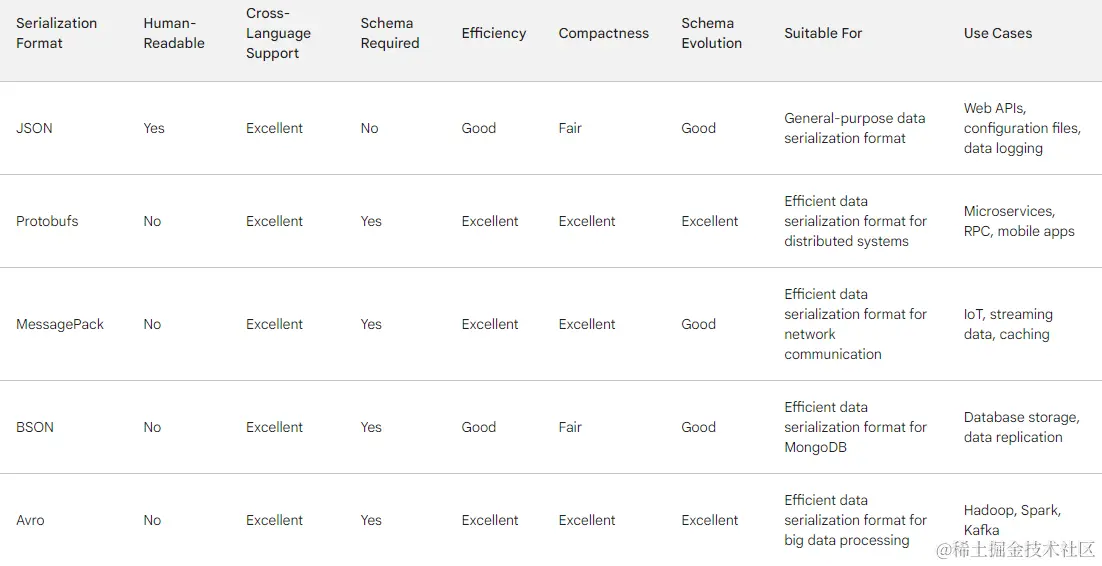
JSON, Protobufs, MessagePack, BSON 和 Avro 之间的差异
每个字节都很重要: 优化数据格式
在效率和速度至上的数据交换世界中, 数据格式的选择会产生天壤之别. 本节将探讨从简单的 JSON 数据表示到更高效的二进制格式(如 Protocol Buffers, MessagePack, BSON 和 Avro)的过程. 我们将深入探讨每种格式的细微差别, 并展示为什么每个字节都很重要.
开始: JSON 数据
我们从简单明了的 JSON 数据结构开始. 下面是我们的 JSON 数据示例片段:
{
"id": 1, // 14 bytes
"name": "John Doe", // 20 bytes
"email": "johndoe@example.com", // 31 bytes
"age": 30, // 9 bytes
"isSubscribed": true, // 13 bytes
"orders": [ // 11 bytes
{ // 2 bytes
"orderId": "A123", // 18 bytes
"totalAmount": 100.50 // 20 bytes
}, // 1 byte
{ // 2 bytes
"orderId": "B456", // 18 bytes
"totalAmount": 75.25 // 19 bytes
} // 1 byte
] // 1 byte
} // 1 byte
JSON 总大小: ~ 139 字节
虽然 JSON 用途广泛且易于使用, 但它也有一个缺点, 那就是它的文本性质. 每个字符, 每个空格和每个引号都很重要. 在数据大小和传输速度至关重要的情况下, 这些看似微不足道的字符可能会产生重大影响.
效率挑战: 使用二进制格式减小尺寸

现在, 让我们提供其他格式的数据表示并比较它们的大小:
Protocol Buffers (protobuf)
syntax = "proto3";
message User {
int32 id = 1;
string name = 2;
string email = 3;
int32 age = 4;
bool is_subscribed = 5;
repeated Order orders = 6;
message Order {
string order_id = 1;
float total_amount = 2;
}
}
0A 0E 4A 6F 68 6E 20 44 6F 65 0C 4A 6F 68 6E 20 44 6F 65 65 78 61 6D 70 6C 65 2E 63 6F 6D 04 21 00 00 00 05 01 12 41 31 32 33 03 42 DC CC CC 3F 05 30 31 31 32 34 34 35 36 25 02 9A 99 99 3F 0D 31 02 42 34 35 36 25 02 9A 99 99 3F
Protocol Buffers 总大小: ~ 38 bytes
MessagePack:
注意:MessagePack 是一种二进制格式, 此处的表示法非人工可读。
二进制表示(十六进制):
a36a6964000000000a4a6f686e20446f650c6a6f686e646f65406578616d706c652e636f6d042100000005011241313302bdcccc3f0530112434353625029a99993f
MessagePack 总大小: ~34 字节
BSON (二进制 JSON)
注意:BSON 是一种二进制格式, 此处的表示法非人工可读。
二进制表示法 (十六进制):
3e0000001069640031000a4a6f686e20446f6502656d61696c006a6f686e646f65406578616d706c652e636f6d1000000022616765001f04370e4940
BSON 总大小: ~ 43 字节
Avro
注: Avro使用schema, 因此数据与schema信息一起编码。
二进制表示法 (十六进制):
0e120a4a6f686e20446f650c6a6f686e646f65406578616d706c652e636f6d049a999940040a020b4108312e3525312e323538323539
Avro 总大小: ~ 32 字节
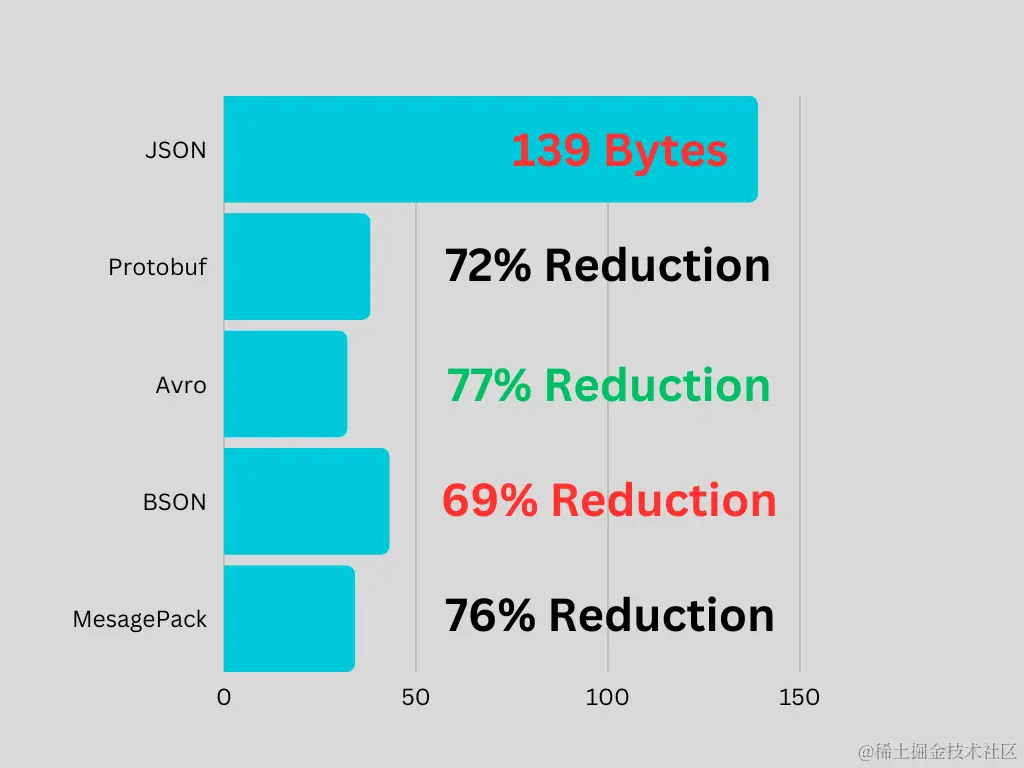
这些替代方案的实际字节数可能会有所不同, 提供这些数字只是为了让大家有个大致的了解。
现在你可能想知道为什么有些格式输出的是二进制, 但它们的大小却各不相同。Avro, MessagePack 和 BSON 等二进制格式具有不同的内部结构和编码机制, 这可能导致二进制表示法的差异, 即使它们最终表示的是相同的数据。下面简要介绍一下这些差异是如何产生的:
-
Avro
-
Avro 使用schema对数据进行编码, 二进制表示法中通常包含该schema.
-
Avro 基于schema的编码可提前指定数据结构, 从而实现高效的数据序列化和反序列化.
-
Avro 的二进制格式设计为自描述格式, 这意味着schema信息包含在编码数据中. 这种自描述性使 Avro 能够保持不同版本数据模式之间的兼容性.
-
-
MessagePack
-
MessagePack 是一种二进制序列化格式, 直接对数据进行编码, 不包含schema信息.
-
它使用长度可变的整数和长度可变的字符串的紧凑二进制表示法, 以尽量减少空间使用.
-
MessagePack 不包含schema信息, 因此更适用于schema已预先知道并在发送方和接收方之间共享的情况.
-
-
BSON
-
BSON 是 JSON 数据的二进制编码, 包括每个值的类型信息.
-
BSON 的设计与 JSON 紧密相连, 但它增加了二进制数据类型, 如 JSON 缺乏的日期和二进制数据.
-
与 MessagePack 一样, BSON 不包含schema信息.
-
-
这些设计和编码上的差异导致了二进制表示法的不同:
-
Avro 包含模式信息并具有自描述性, 这导致二进制大小稍大, 但提供了schema兼容性.
-
MessagePack 因其可变长度编码而高度紧凑, 但缺乏模式信息, 因此适用于已知模式的情况.
-
BSON 与 JSON 关系密切, 包含类型信息, 与 MessagePack 等纯二进制格式相比, 会增加大小.
-
总之, 这些差异源于每种格式的设计目标和功能. Avro 优先考虑schema兼容性, MessagePack 注重紧凑性, 而 BSON 则在保持类似 JSON 结构的同时增加了二进制类型. 格式的选择取决于具体的使用情况和要求, 如schema兼容性, 数据大小和易用性。
优化 JSON 性能
JSON 虽然用途广泛, 在Web开发中被广泛采用, 但在速度方面也存在挑战. 这种格式的人类可读性会导致数据负载较大, 处理时间较慢. 因此, 问题出现了: 我们能够怎样优化JSON以使得它更快更高效? 在本文中, 我们将探讨可用于提高 JSON 性能的实用策略和优化方法, 以确保 JSON 在提供应用所需的速度和效率的同时, 仍然是现代 Web 开发中的重要工具.
以下是一些优化 JSON 性能的实用技巧以及代码示例和最佳实践:
最小化数据大小
使用简短, 描述性的键名: 选择简洁但有意义的键名, 以减小 JSON 对象的大小.
// Inefficient
{
"customer_name_with_spaces": "John Doe"
}
// Efficient
{
"customerName": "John Doe"
}
尽可能缩写: 在不影响清晰度的情况下, 考虑对键或值使用缩写.
// Inefficient
{
"transaction_type": "purchase"
}
// Efficient
{
"txnType": "purchase"
}
优化数字表示
尽可能使用整数: 如果数值可以用整数表示, 请使用整数而不是浮点数.
// Inefficient
{
"quantity": 1.0
}
// Efficient
{
"quantity": 1
}
消除冗余:
避免重复数据: 通过引用共享值来消除冗余数据.
// Inefficient
{
"product1": {
"name": "Product A",
"price": 10
},
"product2": {
"name": "Product A",
"price": 10
}
}
// Efficient
{
"products": [
{
"name": "Product A",
"price": 10
},
{
"name": "Product B",
"price": 15
}
]
}
使用压缩:
使用压缩算法: 如何可行的话, 使用压缩算法, 比如Gzip 或者Brotli, 以在传输过程中减少JSON负载大小.
// Node.js example using zlib for Gzip compression
const zlib = require('zlib');
const jsonData = {
// Your JSON data here
};
zlib.gzip(JSON.stringify(jsonData), (err, compressedData) => {
if (!err) {
// Send compressedData over the network
}
});
采用服务器端缓存
缓存 JSON 响应: 实施服务器端缓存, 以便高效地存储和提供 JSON 响应, 减少重复数据处理的需要.
剖析与优化
剖析性能: 使用剖析工具找出 JSON 处理代码中的瓶颈, 然后优化这些部分。请记住, 你实施的具体优化措施应符合应用的要求和限制.
真实世界的优化: 在实践中加速
在这一部分, 我们将深入探讨现实世界中遇到 JSON 性能瓶颈并成功解决的应用和项目. 我们将探讨企业如何解决 JSON 的局限性, 以及这些优化为其应用带来的切实好处. 从 LinkedIn 和 Auth0 这样的知名平台到 Uber 这样的颠覆性科技巨头*, 这些示例为我们提供了宝贵的见解, 让我们了解在尽可能利用 JSON 的多功能性的同时提高速度和响应能力的策略.
1. LinkedIn集成Protocol Buffers:
挑战: LinkedIn 面临的挑战是 JSON 的冗长以及由此导致的网络带宽使用量增加, 从而导致延迟增加. 解决方案: 他们在微服务通信中采用了二进制序列化格式 Protocol Buffers 来取代 JSON. 影响: 这一优化将延迟降低了60%, 提高了 LinkedIn 服务的速度和响应能力.
2. Uber的H3地理索引:
- 挑战: Uber 使用 JSON 表示各种地理空间数据, 但解析大型数据集的 JSON 会降低其算法的速度.
- 解决方法 他们引入了H3地理索引, 这是一种用于地理空间数据的高效六边形网格系统, 可减少 JSON 解析开销.
- 影响: 这一优化大大加快了地理空间操作, 增强了 Uber 的叫车和地图服务.
3. Slack的消息格式优化:
- 挑战: Slack 需要在实时聊天中传输和呈现大量 JSON 格式的消息, 这导致了性能瓶颈.
- 解决方法 他们优化了 JSON 结构, 减少了不必要的数据, 只在每条信息中包含必要的信息.
- 影响: 这一优化提高了消息渲染速度, 改善了 Slack 用户的整体聊天性能.
4. Auth0的Protocal Buffers实现:
- 挑战: Auth0 是一个流行的身份和访问管理平台, 在处理身份验证和授权数据时面临着 JSON 的性能挑战.
- 解决方案: 他们采用Protocal Buffers来替代 JSON, 以编解码与身份验证相关的数据.
- 影响: 这一优化大大提高了数据序列化和反序列化的速度, 从而加快了身份验证流程, 并增强了 Auth0 服务的整体性能.
这些真实案例表明, 通过优化策略解决 JSON 的性能难题, 可对应用的速度, 响应和用户体验产生重大积极影响. 它们强调了在各种应用场景中考虑使用替代数据格式和高效数据结构来克服 JSON 相关缓慢的问题的重要性.
总结一下
在开发领域, JSON 是数据交换不可或缺的通用工具. 其人类可读格式和跨语言兼容性使其成为现代应用的基石. 然而, 正如我们在本文中所探讨的, JSON 的广泛应用并不能使其免于性能挑战.
我们在优化 JSON 性能的过程中获得的主要启示是显而易见的:
- 性能至关重要: 在当今的数字环境中, 速度和响应速度至关重要. 用户希望应用能够快如闪电, 即使是微小的延迟也会导致不满和机会的丧失.
- 尺寸至关重要: 数据有效载荷的大小会直接影响网络带宽的使用和响应时间. 减少数据大小通常是优化 JSON 性能的第一步.
- 替代格式: 当效率和速度至关重要时, 探索其他数据序列化格式, 如Protocal Buffers, MessagePack, BSON 或 Avro.
- 真实世界案例: 从企业成功解决 JSON 速度变慢问题的实际案例中学习. 这些案例表明, 优化工作可以大幅提高应用的性能.
在继续构建和增强Web应用时, 请记住要考虑 JSON 对性能的影响. 仔细设计数据结构, 选择有意义的键名, 并在必要时探索其他序列化格式. 这样, 你就能确保你的应用在速度和效率方面不仅能满足用户的期望, 而且还能超越用户的期望.
在不断变化的Web开发环境中, 优化 JSON 性能是一项宝贵的技能, 它能让你的项目与众不同, 并确保你的应用在即时数字体验时代茁壮成长.
作者:bytebeats
链接:https://juejin.cn/post/7299353265099423753
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









