







Agenda
1. Architecture of Scheduler
2. Kubernetes Default Scheduler
3. Multiple Schedulers
4. Schedule Policy
5. Schedule RateLimiter
1. Architecture of Scheduler
集群调度工具要求/原则:使得集群的资源(如:cpu,memory,disk)被高效利用,支持用户提供的配置约束(placement constraints),能够迅速调度应用以此保证它们不会处于待定状态(pending state),有一定程度的”公平”(fairness),具有一定的健壮性和可用性。在关于Omega(Omega flexible, scalable schedulers for large compute clusters)的白皮书中,提到了三个主要的调度架构
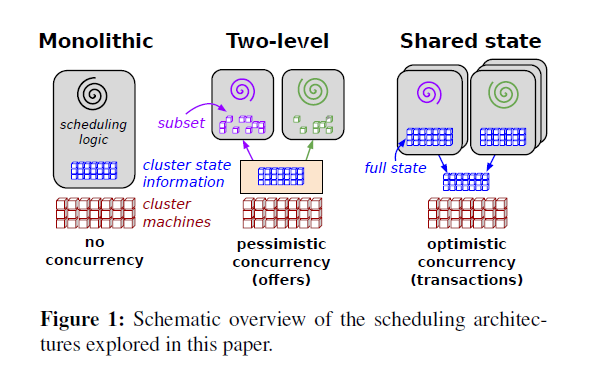
1.1 Monolithic scheduling
单体式调度结构由单一的调度器(scheduler)组成,它负责处理所有的请求,
这种结构通常应用于高性能计算。其通常实现了一个单一的算法来处理所有的作业(job)
因此根据作业的类型来运行不同的调度逻辑是困难的
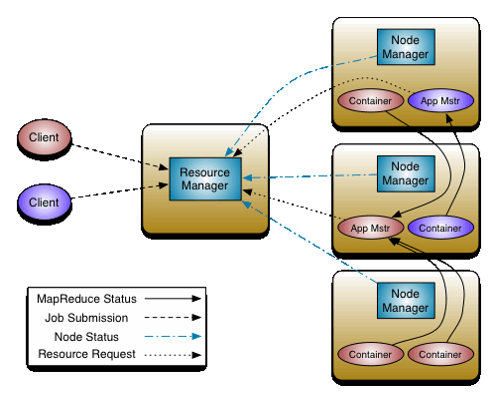
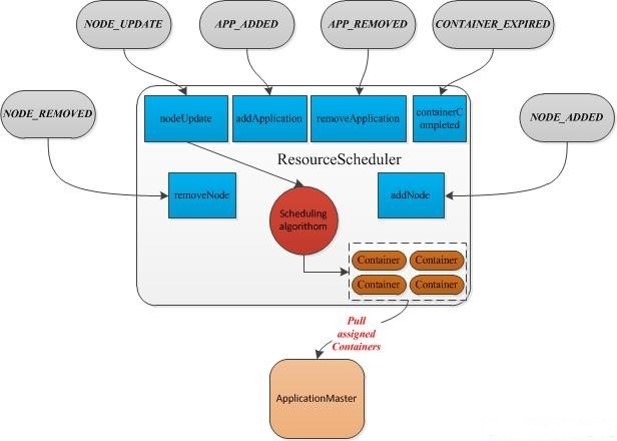
Apache Hadoop YARN 就是单体式调度架构的典型代表,
所有的资源(slot)请求都会被发送到一个单一的全局调度模块
1.2 Two-level scheduling
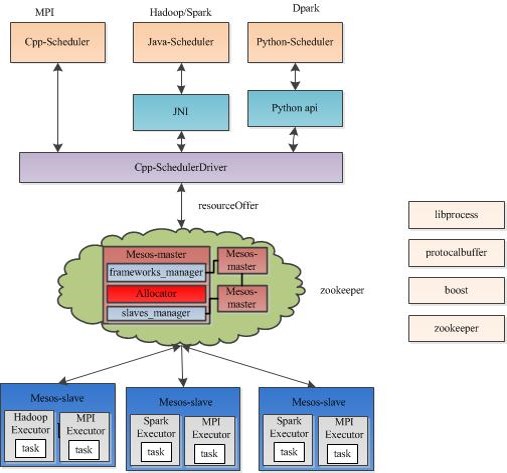
两级调度框架会利用一个中央协调器(central coordinator)来动态地决定各个调度
模块可以调用多少资源. Apache Mesos既是该架构的典型代表
Mesos由四个组件组成,分别是Mesos-master,mesos-slave,framework和executor
Mesos-master是系统的核心,负责管理接入mesos的各个framework
(由frameworks_manager管理)和slave(由slaves_manager管理),并将slave上的
资源按照某种策略分配给framework(由独立插拔模块Allocator管理)。
Mesos中的调度机制被称为”Resource Offer”,采用了基于资源量的调度机制,这不同
于Hadoop中的基于slot的机制。在mesos中,s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









