






一、概述
本文基于宿主机Win10笔记本(8G+256固态,连接无线wifi)+三台虚拟机进行搭建。以下为搭建的详细过程,接近于现场直播Live。
二、软件环境准备
使用到具体软件及版本如下:
虚拟机VMware
VMware-workstation-full-12.5.7-5813279.exe
下载地址 https://my.vmware.com/web/vmware/details?productId=524&rPId=20840&downloadGroup=WKST-1257-WIN 
Centos
CentOS-7-x86_64-Minimal-1810.iso(最小安装盘,只有必要的软件,自带的软件最少,只有918 MB)
下载地址 http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1810.iso 
JDK
jdk-8u181-linux-x64.tar.gz
下载地址 https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html 
Hadoop
hadoop-2.9.2.tar.gz
下载地址 https://archive.apache.org/dist/hadoop/core/hadoop-2.9.2/
其他使用到的工具
远程连接工具Xshell6
上传工具xftp6
三、虚拟机准备
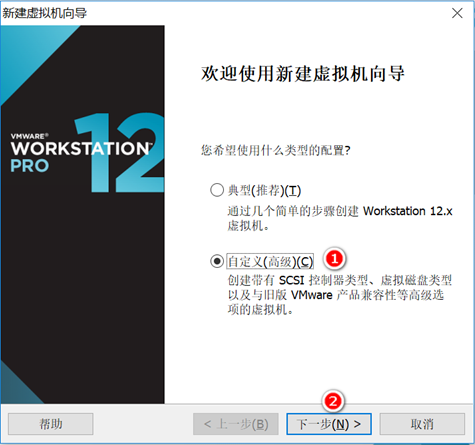
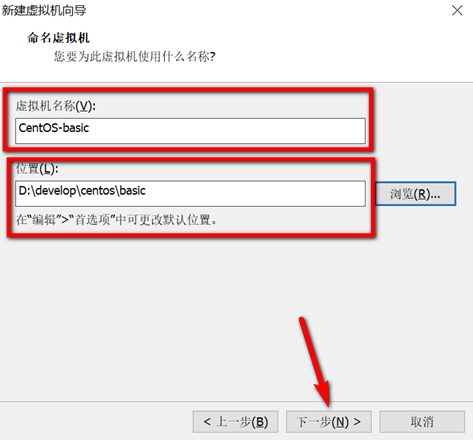
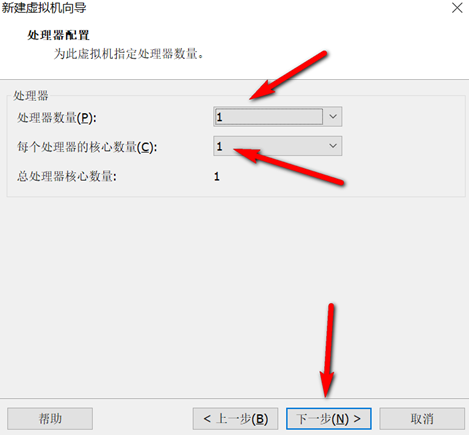
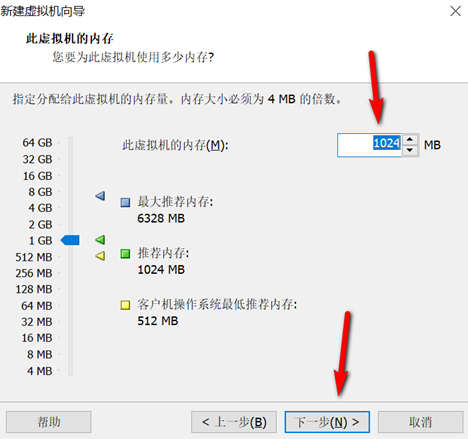
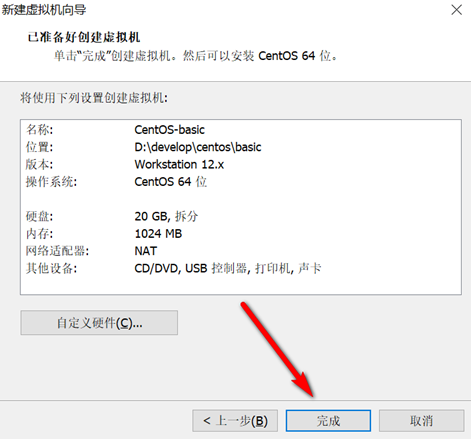
创建新的虚拟机,用于克隆,作为基础虚拟机,直接看图说话(虚拟机准备好的可略过)
新建虚拟机

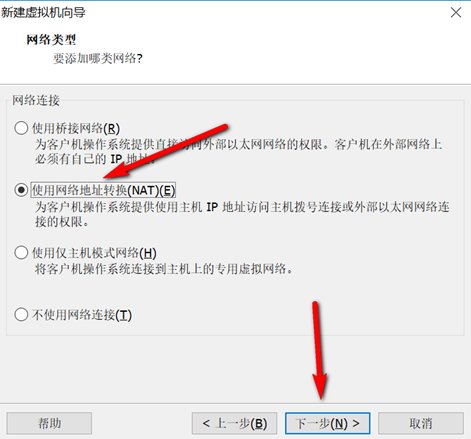
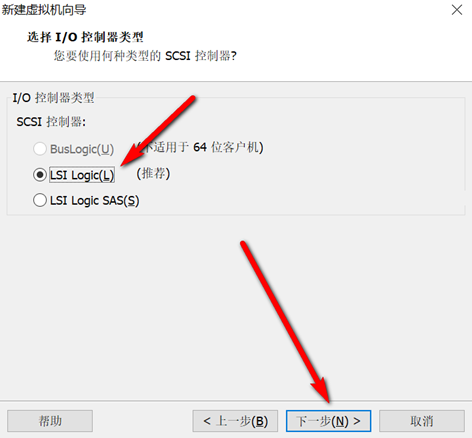

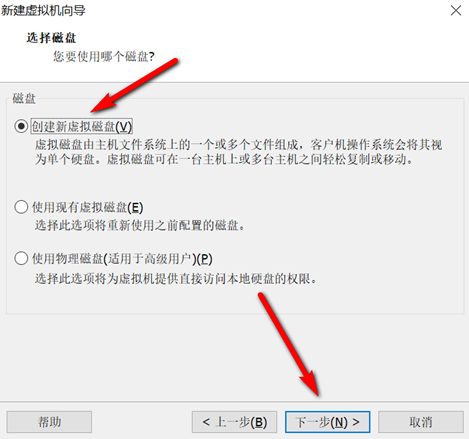
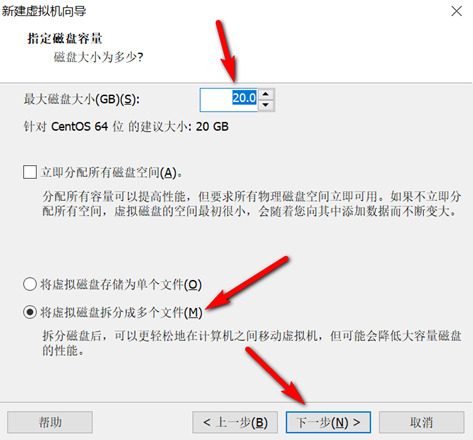
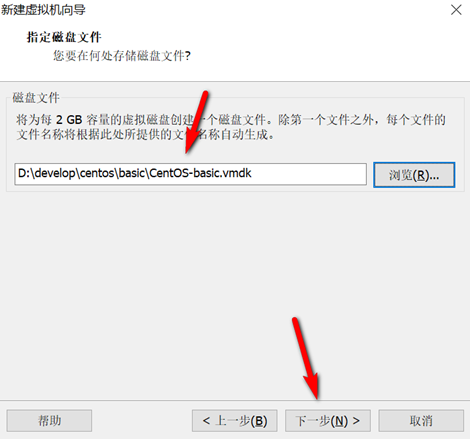

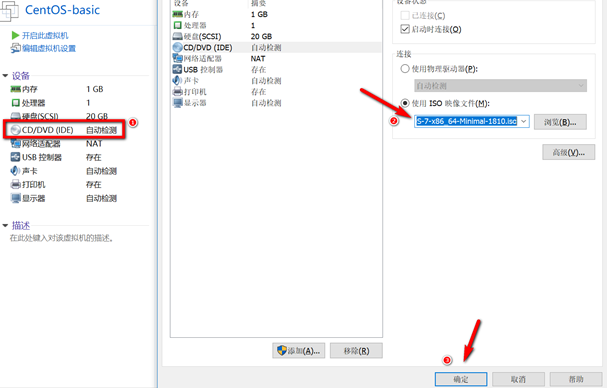
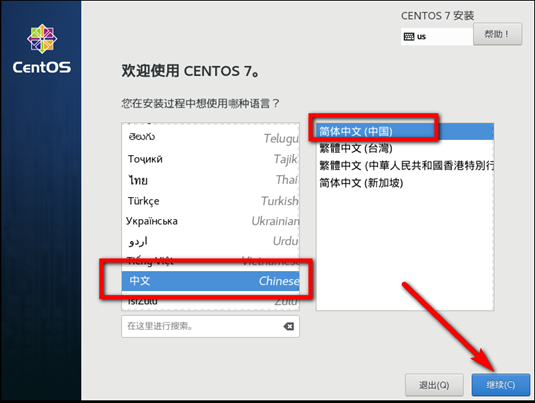
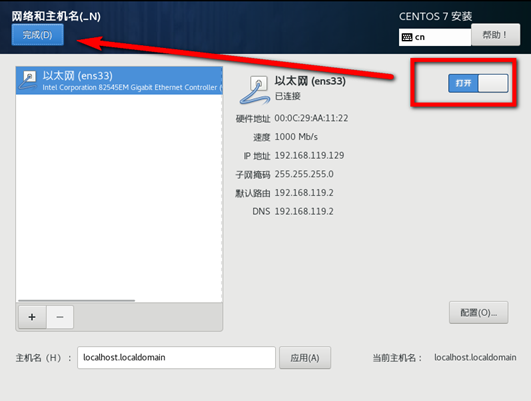
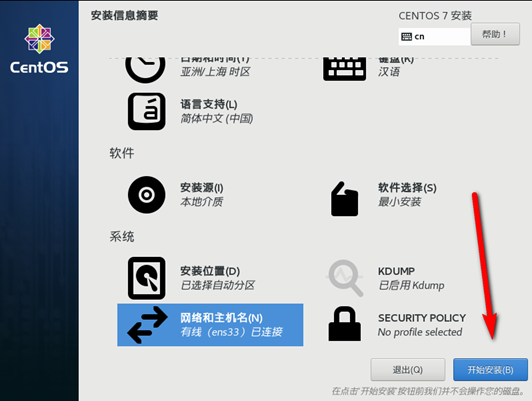
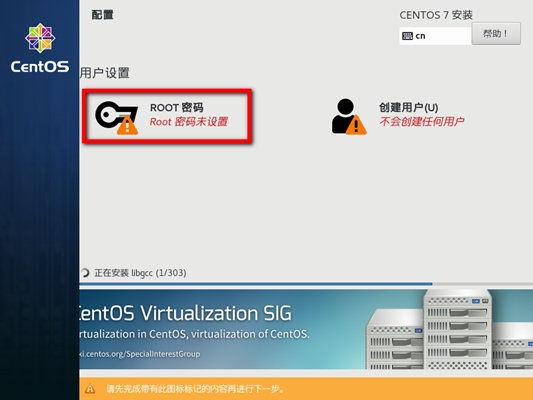
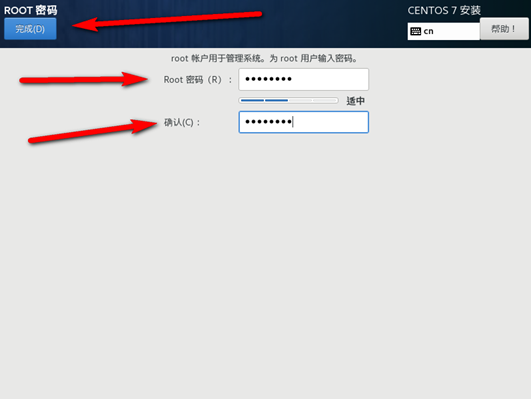
网络设置
VMware和Windows网络设置

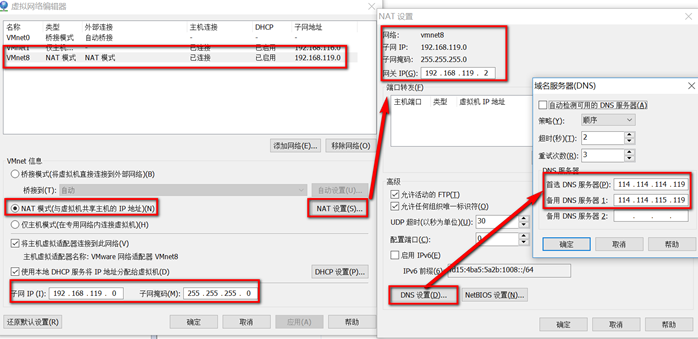
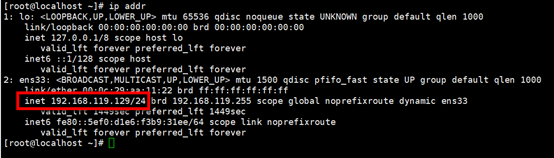
设置IP 网关 DNS
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改前
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="dafc2038-f4fc-4a6d-b704-30e3c32f52e9"
DEVICE="ens33"
ONBOOT="yes"
修改后
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="dafc2038-f4fc-4a6d-b704-30e3c32f52e9"
DEVICE="ens33"
ONBOOT="yes"
#实时生效
NM_CONTROLLED="yes"
#ip
IPADDR=192.168.119.130
#网关
GATEWAY=192.168.119.2
#子网掩码
NETMASK=255.255.255.0
#使用主的DNS
DNS1=114.114.114.119
#备用的DNS
DNS2=114.114.115.119
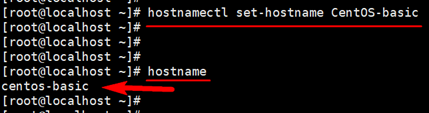
修改主机名
hostnamectl set-hostname centos-basic
查看主机名 hostname
关闭防火墙
//临时关闭
systemctl stop firewalld
//禁止开机启动
systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.

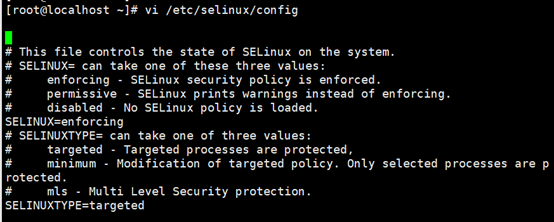
关闭SELinxu命令(永久)
将SELINUX=enforcing改为SELINUX=disabled ,设置后需要重启才能生效。
vi /etc/selinux/config
修改前:
查看 /usr/sbin/sestatus/
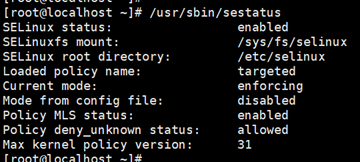
修改后:

reboot重启后查看

创建用户并设置文件权限
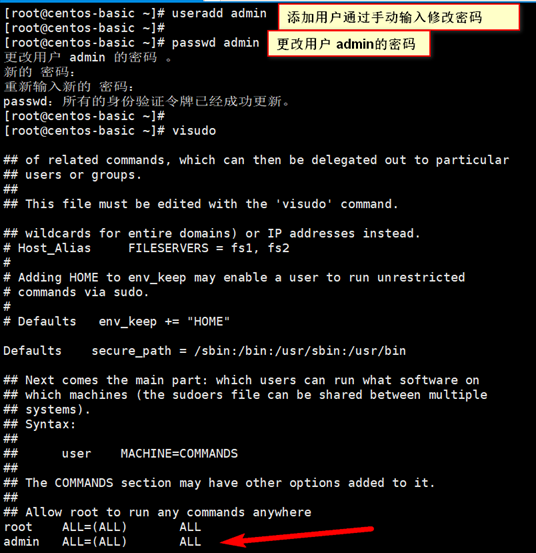
visudo操作时:vi编辑器一般模式下,
/root 定位到root所在行
yy 复制
p 粘贴
然后将root 改成admin即可
:x 保存退出,切换至admin用户 su - admin

创建文件夹并修改权限 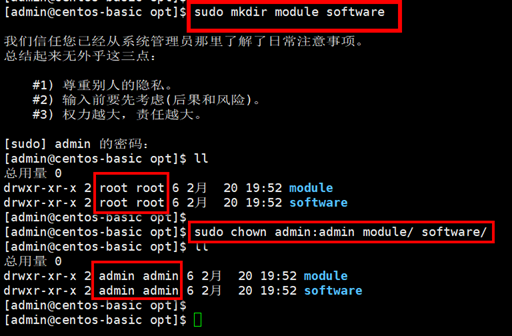
关机快照克隆
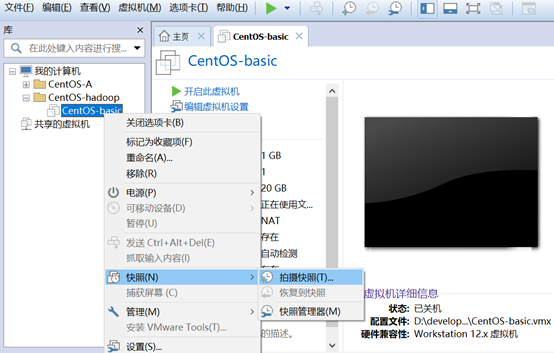
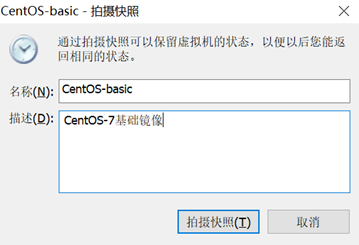
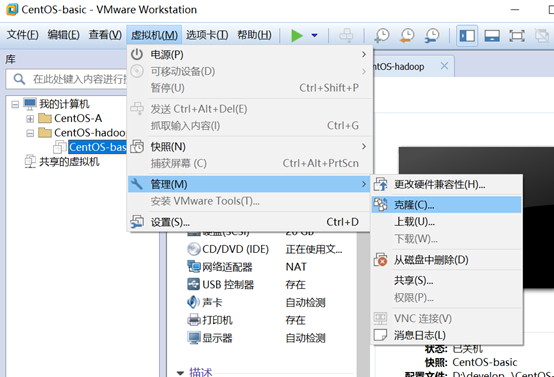
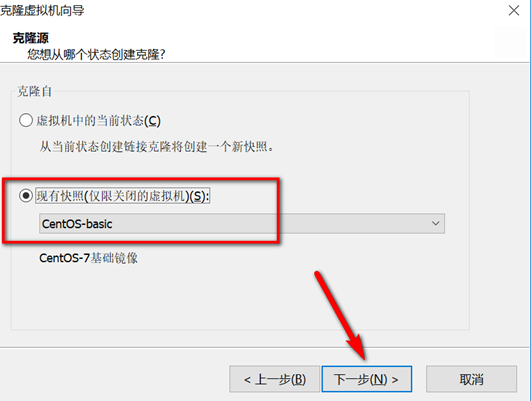
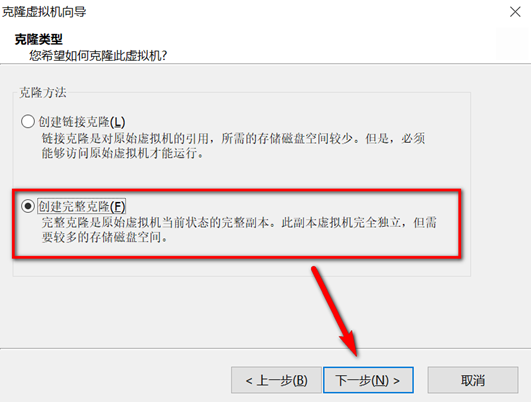
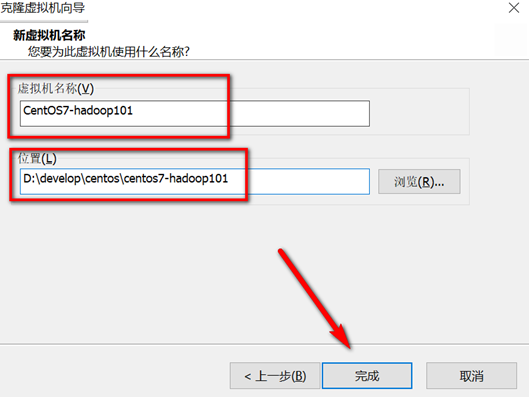
克隆完成后,打开新克隆的虚拟机进行如下操作:
修改静态Ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.119.101
修改主机名
hostnamectl set-hostname hadoop101
添加主机名与ip映射关系
vi /etc/hosts
192.168.119.101 hadoop101
192.168.119.102 hadoop102
192.168.119.103 hadoop103
重启生效
reboot
本地映射配置(宿主机)
C:\Windows\System32\drivers\etc\hosts
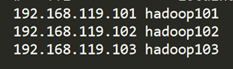
同hadoop101操作再克隆hadoop102、hadoop103。
四、安装JDK
登陆hadoop101 虚拟机 用xftp6将jdk和hadoop安装包上传至/opt/software文件夹下

解压jdk至/opt/module/文件夹下
tar -zxvf /opt/software/jdk-8u181-linux-x64.tar.gz -C /opt/module/
配置jdk环境变量
先获取jdk路径
[root@hadoop101 jdk1.8.0_181]# pwd
/opt/module/jdk1.8.0_181
打开/etc/profile文件,在profie文件末尾添加jdk路径
[root@hadoop101 jdk1.8.0_181]# vi /etc/profile
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_181
export PATH=$PATH:$JAVA_HOME/bin
保存后退出 :wq
让修改后的文件生效
[root@hadoop101 jdk1.8.0_181]# source /etc/profile
测试jdk安装成功
[root@hadoop101 jdk1.8.0_181]# java -version
五、安装hadoop
解压 tar -zxvf /opt/software/hadoop-2.9.2.tar.gz -C /opt/module/
配置hadoop中的hadoop-env.sh
- 获取jdk的安装路径:
[root@hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_181
- 修改/opt/module/hadoop-2.9.2/etc/hadoop/hadoop-env.sh文件中JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_181
将hadoop添加到环境变量
- 获取hadoop安装路径:
[root@hadoop101 hadoop-2.9.2]# pwd
/opt/module/hadoop-2.9.2
- 打开/etc/profile文件,在profie文件末尾添加jdk路径:(shitf+g)【依次按G到最后一行,o光标下一行插入,vi 一般模式yy复制当前行,p粘贴】
root@ hadoop101 hadoop-2.9.2]# vi /etc/profile
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 保存后退出:
:wq
- 让修改后的文件生效:
root@ hadoop101 hadoop-2.9.2]# source /etc/profile
- 验证环境变量
root@ hadoop101 hadoop-2.9.2]# hadoop version
六、完全分布式运行模式搭建
跨服务器数据拷贝scp
将hadoop101中/opt/module文件拷贝到hadoop102、hadoop103上。
scp -r /opt/module/ root@hadoop102:/opt
scp -r /opt/module/ root@hadoop103:/opt
进入module文件夹修改hadoop102和hadoop103 /opt/module 下的用户组权限
sudo chown admin:admin /opt/module/ -R
SSH免密钥设置
Hadoop101
[admin@hadoop101 ~]# ssh-keygen -t rsa
[admin@hadoop101 ~]# ssh-copy-id hadoop101
[admin@hadoop101 ~]# ssh-copy-id hadoop102
[admin@hadoop101 ~]# ssh-copy-id hadoop103
Hadoop102
[admin@hadoop102 ~]# ssh-keygen -t rsa
[admin@hadoop102 ~]# ssh-copy-id hadoop102
[admin@hadoop102 ~]# ssh-copy-id hadoop101
[admin@hadoop102 ~]# ssh-copy-id hadoop103
Hadoop103
[admin@hadoop103 ~]# ssh-keygen -t rsa
[admin@hadoop103 ~]# ssh-copy-id hadoop103
[admin@hadoop103 ~]# ssh-copy-id hadoop101
[admin@hadoop103 ~]# ssh-copy-id hadoop102
集群分发脚本xsync
在/usr/local/bin目录下创建xsync文件
[admin@hadoop101 bin]$ sudo touch xsync
文件内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<104; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
修改脚本 xsync 具有执行权限
[admin@hadoop101 bin]$ sudo chmod 777 xsync
xsync 调用脚本形式:xsync 文件名称
[admin@hadoop101 ~]$ xsync /usr/local/bin/xsync
fname=xsync
pdir=/usr/local/bin
--------------- hadoop102 ----------------
/usr/local/bin/xsync:行25: rsync: 未找到命令
--------------- hadoop103 ----------------
/usr/local/bin/xsync:行25: rsync: 未找到命令
发现未安装,将三台虚拟机分别安装
[admin@hadoop101 ~]$ sudo yum install rsync -y
[admin@hadoop102 ~]$ sudo yum install rsync -y
[admin@hadoop103 ~]$ sudo yum install rsync -y
安装完成后,执行该脚本
[root@hadoop101 ~]# xsync /usr/local/bin/xsync
fname=xsync
pdir=/usr/local/bin
--------------- hadoop102 ----------------
root@hadoop102's password:
sending incremental file list
xsync
sent 638 bytes received 35 bytes 149.56 bytes/sec
total size is 549 speedup is 0.82
--------------- hadoop103 ----------------
root@hadoop103's password:
sending incremental file list
xsync
sent 638 bytes received 35 bytes 192.29 bytes/sec
total size is 549 speedup is 0.82
完成后hadoop102和hadoop103就同步过来了xsync脚本文件
配置集群
集群部署规划

修改配置文件
[admin@hadoop101 ~]$ vi /opt/module/hadoop-2.9.2/etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.9.2/data/tmp</value>
</property>
HDFS
vi /opt/module/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
vi /opt/module/hadoop-2.9.2/etc/hadoop/ hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
</configuration>
slaves
vi /opt/module/hadoop-2.9.2/etc/hadoop/slaves
hadoop101
hadoop102
hadoop103
yarn
vi /opt/module/hadoop-2.9.2/etc/hadoop/yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
vi /opt/module/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
</configuration>
mapreduce
vi /opt/module/hadoop-2.9.2/etc/hadoop/mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
cp mapred-site.xml.template mapred-site.xml
vi /opt/module/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发以上所有配置文件
xsync /opt/module/hadoop-2.9.2/etc/hadoop/
七、集群启动及测试
集群群起
- 如果集群是第一次启动,需要格式化namenode 【三台hadoop-2.9.2下将data和logs文件夹删除】
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs namenode -format
- 启动HDFS
[admin@hadoop101 hadoop-2.9.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop101]
hadoop101: starting namenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-namenode-hadoop101.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop102.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop103.out
hadoop101: starting datanode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-datanode-hadoop101.out
Starting secondary namenodes [hadoop103]
hadoop103: starting secondarynamenode, logging to /opt/module/hadoop-2.9.2/logs/hadoop-admin-secondarynamenode-hadoop103.out
分别查看三台虚拟机进程
[admin@hadoop101 hadoop-2.9.2]$ jps
8146 NameNode
8483 Jps
8277 DataNode
[admin@hadoop102 hadoop-2.9.2]$ jps
7923 Jps
7807 DataNode
[admin@hadoop103 hadoop-2.9.2]$ jps
7411 DataNode
7512 SecondaryNameNode
7594 Jps
- 启动yarn (在ResouceManager所在的机器上启动yarn,即hadoop102上执行)
[admin@hadoop102 hadoop-2.9.2]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-resourcemanager-hadoop102.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop103.out
hadoop101: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop101.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.9.2/logs/yarn-admin-nodemanager-hadoop102.out
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
查看三台进程,与集群部署规划对比无误
[admin@hadoop101 ~]$ jps
8146 NameNode
8579 NodeManager
8277 DataNode
8699 Jps
[admin@hadoop102 hadoop-2.9.2]$ jps
7970 ResourceManager
8083 NodeManager
8378 Jps
7807 DataNode
[admin@hadoop103 hadoop-2.9.2]$ jps
7411 DataNode
7636 NodeManager
7512 SecondaryNameNode
7755 Jps
打开浏览器访问 http://hadoop101:50070/
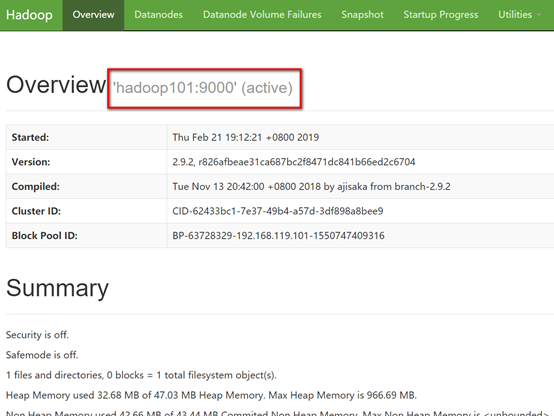
集群基本测试
查看根目录下
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
递归创建文件夹
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs dfs -mkdir -p /user/admin/temp/conf
查看
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp/conf
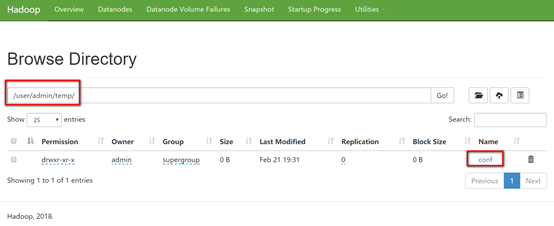
上传小文件,将hadoop满足*-site.xml的配置文件存放到刚创建的conf文件夹中
[admin@hadoop101 hadoop-2.9.2]$ bin/hdfs dfs -put etc/hadoop/*-site.xml /user/admin/temp/conf
查看
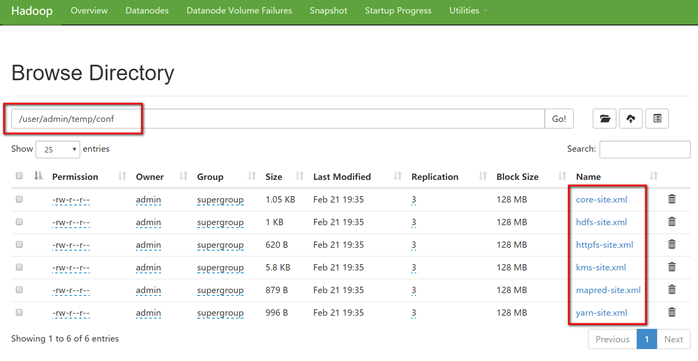
[admin@hadoop101 hadoop-2.9.2]$ hadoop fs -ls -R /
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin
drwxr-xr-x - admin supergroup 0 2019-02-21 19:31 /user/admin/temp
drwxr-xr-x - admin supergroup 0 2019-02-21 19:35 /user/admin/temp/conf
-rw-r--r-- 3 admin supergroup 1078 2019-02-21 19:35 /user/admin/temp/conf/core-site.xml
-rw-r--r-- 3 admin supergroup 1029 2019-02-21 19:35 /user/admin/temp/conf/hdfs-site.xml
-rw-r--r-- 3 admin supergroup 620 2019-02-21 19:35 /user/admin/temp/conf/httpfs-site.xml
-rw-r--r-- 3 admin supergroup 5939 2019-02-21 19:35 /user/admin/temp/conf/kms-site.xml
-rw-r--r-- 3 admin supergroup 879 2019-02-21 19:35 /user/admin/temp/conf/mapred-site.xml
-rw-r--r-- 3 admin supergroup 996 2019-02-21 19:35 /user/admin/temp/conf/yarn-site.xml
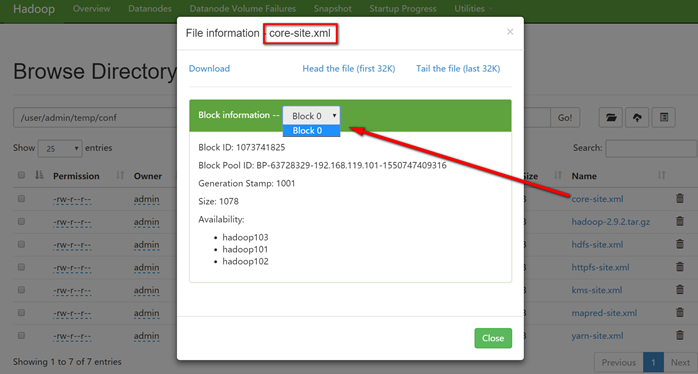
上传大文件
[admin@hadoop101 hadoop-2.9.2]$ bin/hadoop fs -put /opt/software/hadoop-2.9.2.tar.gz /user/admin/temp/conf
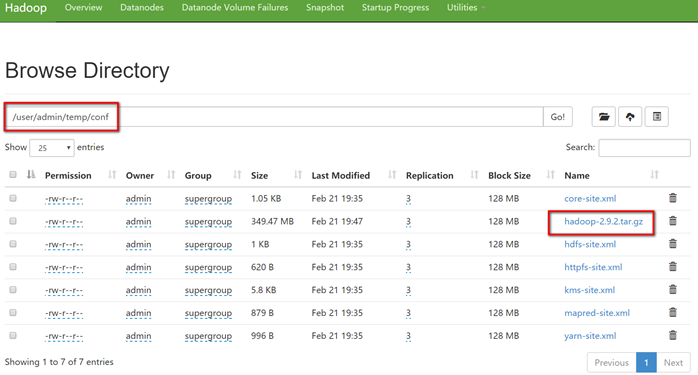
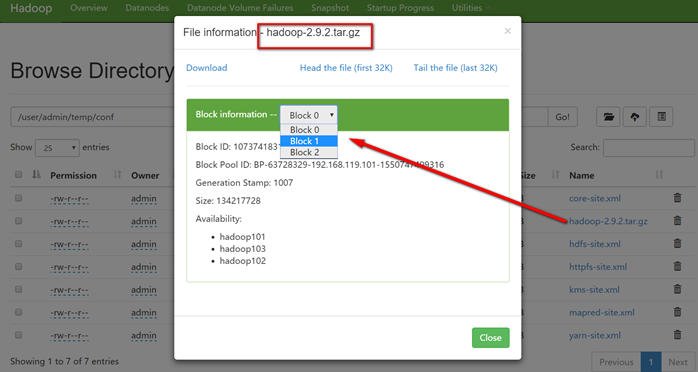
上传文件后查看文件存放在什么位置
文件存储路径
[admin@hadoop101 subdir0]$ pwd
/opt/module/hadoop-2.9.2/data/tmp/dfs/data/current/BP-63728329-192.168.119.101-1550747409316/current/finalized/subdir0/subdir0
[admin@hadoop101 subdir0]$
[admin@hadoop101 subdir0]$ ll
总用量 360716
-rw-rw-r-- 1 admin admin 1078 2月 21 19:35 blk_1073741825
-rw-rw-r-- 1 admin admin 19 2月 21 19:35 blk_1073741825_1001.meta
-rw-rw-r-- 1 admin admin 1029 2月 21 19:35 blk_1073741826
-rw-rw-r-- 1 admin admin 19 2月 21 19:35 blk_1073741826_1002.meta
-rw-rw-r-- 1 admin admin 620 2月 21 19:35 blk_1073741827
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741827_1003.meta
-rw-rw-r-- 1 admin admin 5939 2月 21 19:35 blk_1073741828
-rw-rw-r-- 1 admin admin 55 2月 21 19:35 blk_1073741828_1004.meta
-rw-rw-r-- 1 admin admin 879 2月 21 19:35 blk_1073741829
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741829_1005.meta
-rw-rw-r-- 1 admin admin 996 2月 21 19:35 blk_1073741830
-rw-rw-r-- 1 admin admin 15 2月 21 19:35 blk_1073741830_1006.meta
-rw-rw-r-- 1 admin admin 134217728 2月 21 19:47 blk_1073741831
-rw-rw-r-- 1 admin admin 1048583 2月 21 19:47 blk_1073741831_1007.meta
-rw-rw-r-- 1 admin admin 134217728 2月 21 19:47 blk_1073741832
-rw-rw-r-- 1 admin admin 1048583 2月 21 19:47 blk_1073741832_1008.meta
-rw-rw-r-- 1 admin admin 98011993 2月 21 19:47 blk_1073741833
-rw-rw-r-- 1 admin admin 765727 2月 21 19:47 blk_1073741833_1009.meta
八、Hadoop启动停止方式
- 各个服务组件逐一启动
1)分别启动hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
2)启动yarn
yarn-daemon.sh start|stop resourcemanager|nodemanager
- 各个模块分开启动(配置ssh是前提)常用 1)整体启动/停止hdfs
start-dfs.sh
stop-dfs.sh
2)整体启动/停止yarn
start-yarn.sh
stop-yarn.sh
- 全部启动(不建议使用)
start-all.sh
stop-all.sh
九、集群时间同步
时间同步的方式:找一台机器作为时间服务器,所有的机器与这台集群时间进行定时的同步。
时间服务器配置
- 检查ntp是否安装(因为CentOS选用的是Minimal版本,所以并没有安装)
[root@hadoop101 /]# rpm -qa|grep ntp
- 安装ntp
[root@hadoop101 /]# yum install ntp
再次检查发现安装成功
[root@hadoop101 /]# rpm -qa|grep ntp
ntpdate-4.2.6p5-28.el7.centos.x86_64
ntp-4.2.6p5-28.el7.centos.x86_64
- 修改ntp配置文件
[root@hadoop101 /]# vi /etc/ntp.conf

①:授权192.168.119.0-255.255.255.0网段上的所有机器可以从这台机器上查询和同步时间
②:集群在局域网中,不是用其他互联网上的时间(注掉)
③:当该节点网络连接丢失,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
- 修改/etc/sysconfig/ntpd 文件
[root@hadoop101 /]# vi /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
- 重启ntpd
[root@hadoop101 /]# service ntpd start
- 设置ntpd开机启动
chkconfig ntpd on
其他机器配置(必须root用户)
- 安装ntp
[root@hadoop102 sbin]# yum install ntp
- 在其他机器配置10分钟与时间服务器同步一次
[root@hadoop102 admin]# crontab -e
*/10 * * * * /usr/sbin/ntpdate hadoop101
- 修改任意机器时间
date -s "2019-10-10"
- 十分钟后查看机器是否与时间服务器同步
date
十、结尾
搭建过程还算顺利,期间参考了许多优秀博主的博客,受益良多,以下是涉及到的博客及地址,在此一一致谢!
Linux之CentOS7.5安装及克隆 https://www.cnblogs.com/frankdeng/p/9027037.html
Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群 http://www.cnblogs.com/frankdeng/p/9047698.html
Vmware虚拟机网络配置(固定IP) https://www.jianshu.com/p/6fdbba039d79
centos修改主机名的正确方法 https://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_043_hostname.html















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









