






简述
随着服务越来越多,调用关系错综复杂,对于一些失败或者延迟的请求,全链路的追踪就越来越重要,这样可以帮助我们定位错误和分析性能瓶颈。
Spring Cloud Sleuth
1.快速实践
依赖引入
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.0.0.M2</version>
</dependency>
日志解读
用户调用service-1 ,service-1再调用service-2这样在服务调用以后会出现如下日志
[service-1,hjjhj212jh1,j21h212344,false]
[service-2,hjjhj212jh1,66yy21ss23,false]- 第一个值:应用名称
- 第二个值:Trace ID代表链路ID,一个Trace ID对应多个Span ID。(通过trace id来跟踪整个请求链路)
- 第三个值:Span ID一个基本工作单元,比如发送一个HTTP请求。(通过Span ID来标识某次请求的延时)
- 第四个值:代表是否输出到zipkin等服务中
2.记录对象
- RabbitMQ或者kafka传递的请求
- 通过zuul代理传递的请求
- 通过RestTemplate发起的请求
3.采集策略
收集的信息越多,对数据的分析就越精准,但是由于在高并发系统中会产生海量的信息,所以会使用一些策略来进行日志采集。sleuth的策略实现接口是Sampler ,默认实现是PercentageBasedSampler,百分比的方式进行日志采集,概率配置参数spring.sleuth.sampler.percentage=0.2 这代表20%的采集比例。当然也可以实现自己的采集策略。
4.整合logstash
我们需要一个系统来收集,存储和搜索这些日志信息。ELK平台由elasticsearch(存储,搜索),logstash(接收,处理和转发)和kibana(为前两者提供web界面)
快速实践
1.引入依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.11</version>
</dependency>
2.创建配置logback-spring.xml
5.整合ZIPKIN
由于ELK平台缺少各阶段时间延迟的关注,对性能瓶颈的研究又需要这个,zipkin能解决这个问题。
1.图解
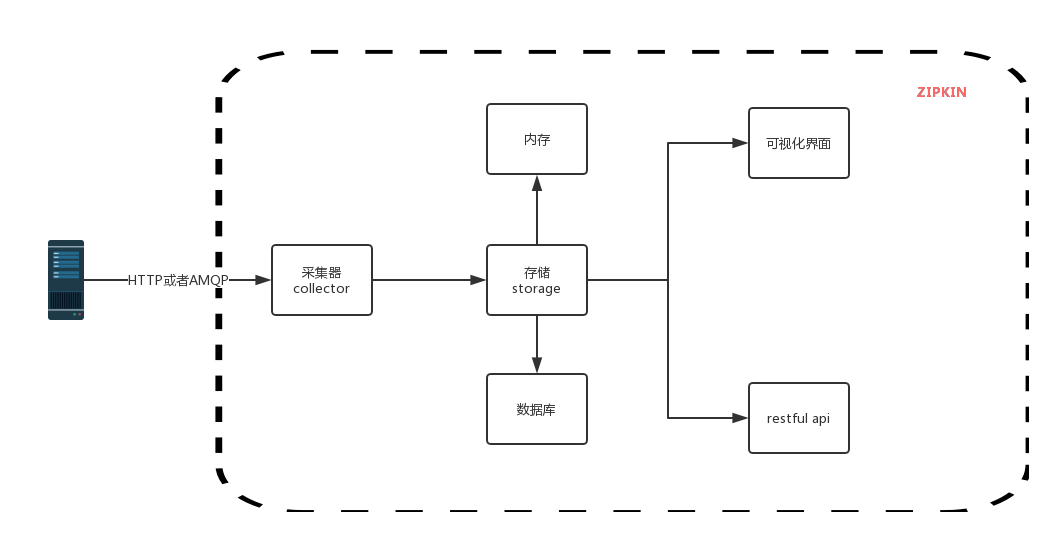
2.快速实践【HTTP收集】
1.搭建server
创建一个springboot应用,引入
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.2.1</version>
</dependency>
在启动类上加上注解
@EnableZipkinServer
添加配置
spring.application.name=zipkin-server
server.port=9000
访问
http://ip:9000 就能看到zipkin的ui界面
2.客户端使用
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
<version>2.0.0.M2</version>
</dependency>
加上配置
spring.zipkin.base-url=http://ip:9000
3.快速实践【消息中间介收集】
1.搭建zokin-server
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
<version>2.0.0.M2</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
<version>2.0.0.M1</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.2.1</version>
</dependency>
加上配置
spring.rabbit.host=
spring.rabbit.port=
spring.rabbit.username=
spring.rabbit.password=2.客户端使用
引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
<version>2.0.0.M2</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
<version>2.0.0.M1</version>
</dependency>加上配置
spring.rabbit.host=
spring.rabbit.port=
spring.rabbit.username=
spring.rabbit.password=4.数据存储
默认情况下数据会在内存中,重启就丢了,肯定不行。所以我们存在数据库里面吧。
1.快速实践
加入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<version>2.0.0.M4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.6</version>
</dependency>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq</artifactId>
<version>3.10.1</version>
</dependency>
初始化脚本
在zipkin-storage-mysqljar包里面有脚本
加入配置
数据库的链接账号密码配置zipkin.storage.type=mysql















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









