






评分算法公式:计算查询词和文档的关联度(评分),评分越高相关度越高
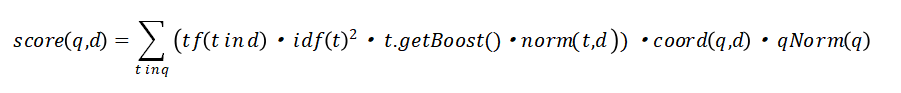
变量含义解释:
q : 查询词
d:一个文档,这里指文章标题+作者+摘要
t:查询词,分词后的每个词
函数含义解析:
tf 函数,词频
idf函数 ,反转文档频率,文档总数/含有这个词的文档数,降低在所有文档中的高频词对搜索词含义的影响,举例:我、的、这类词出现的在所有文档都出现所以要降低它们在搜索查询词中的权重
getBoost函数, 获取查询对词指定的权重(暂时无特殊处理)
norm函数,由先三个函数相乘获得
Document boost - 文档加权,在索引之前使用 doc.setBoost()
Field boost - 字段加权,也在索引之前调用 field.setBoost()
lengthNorm(field) - 由字段内的 Token 的个数来计算此值,字段越短,评分越高(注意:lucene 相似度默认实现:计算文档长度时没有调用lengthNorm方法文档长度,而是通过TFIDFSimilarity读取,实际是在创建索引的时候,通过DefaultSimilarity加入的,如果要修改需要重写该方法 )
存储:
public float lengthNorm(FieldInvertState state) {
final int numTerms;
if (discountOverlaps)
numTerms = state.getLength() - state.getNumOverlap();
else
numTerms = state.getLength();
return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms)));
}
读取:
public final SimScorer simScorer(SimWeight stats, LeafReaderContext context) throws IOException {
IDFStats idfstats = (IDFStats) stats;
return new TFIDFSimScorer(idfstats, context.reader().getNormValues(idfstats.field));
}
coord(q,d),评分因子,是基于文档中出现查询词的个数。越多的查询词在一个文档中,说明些文档的匹配程序越高。默认是出现查询项的百分比,比如查询词被分词3个词,命中n个(n<=3),就是n/3
qNorm(q) 函数,查询因子,标准化评分,不影响评分排序
开启debug模式,观察每个的分值
7.909076 = product of:
10.545435 = sum of:
3.661258 = weight(title:西游记 in 79475) [DefaultSimilarity], result of:
3.661258 = score(doc=79475,freq=1.0), product of:
0.5220341 = queryWeight, product of:
11.221514 = idf(docFreq=3, maxDocs=109953)
0.046520825 = queryNorm
7.013446 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
11.221514 = idf(docFreq=3, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
3.661258 = weight(title:西游 in 79475) [DefaultSimilarity], result of:
3.661258 = score(doc=79475,freq=1.0), product of:
0.5220341 = queryWeight, product of:
11.221514 = idf(docFreq=3, maxDocs=109953)
0.046520825 = queryNorm
7.013446 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
11.221514 = idf(docFreq=3, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
3.2229195 = weight(title:游记 in 79475) [DefaultSimilarity], result of:
3.2229195 = score(doc=79475,freq=1.0), product of:
0.48978832 = queryWeight, product of:
10.528367 = idf(docFreq=7, maxDocs=109953)
0.046520825 = queryNorm
6.5802293 = fieldWeight in 79475, product of:
1.0 = tf(freq=1.0), with freq of:
1.0 = termFreq=1.0
10.528367 = idf(docFreq=7, maxDocs=109953)
0.625 = fieldNorm(doc=79475)
0.75 = coord(3/4)













 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









