







一、DDL 管理库和表
1. 创建数据库
# 创建和管理数据库
#方式1:
CREATE DATABASE mytest1; # 创建的此数据库使用的是默认的字符集
#查看创建数据库的结构
SHOW CREATE DATABASE mytest1;
#方式2:显式了指名了要创建的数据库的字符集
CREATE DATABASE mytest2 CHARACTER SET 'gbk';
#方式3(推荐):如果要创建的数据库已经存在,则创建不成功,但不会报错。
CREATE DATABASE IF NOT EXISTS mytest2 CHARACTER SET 'utf8';
#如果要创建的数据库不存在,则创建成功
CREATE DATABASE IF NOT EXISTS mytest3 CHARACTER SET 'utf8';
#查看所有数据库
SHOW DATABASES;
2. 管理数据库
#查看当前连接中的数据库都有哪些
SHOW DATABASES;
#切换数据库
USE mytest2;
#查看当前数据库中保存的数据表
SHOW TABLES;
#查看当前使用的数据库
SELECT DATABASE() FROM DUAL;
#查看指定数据库下保存的数据表
SHOW TABLES FROM mysql;
#更改数据库字符集
ALTER DATABASE mytest2 CHARACTER SET 'utf8';
#删除数据库
#方式1:如果要删除的数据库存在,则删除成功。如果不存在,则报错
DROP DATABASE mytest1;
SHOW DATABASES;
#方式2:推荐。 如果要删除的数据库存在,则删除成功。如果不存在,则默默结束,不会报错。
DROP DATABASE IF EXISTS mytest1;
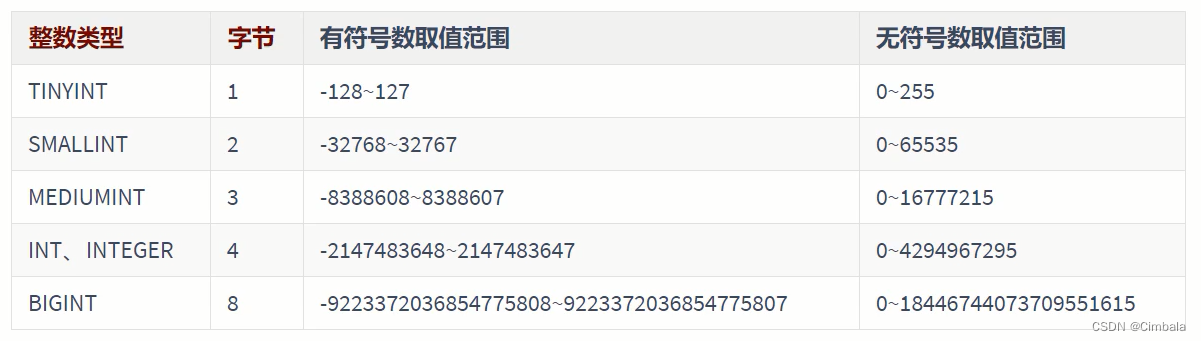
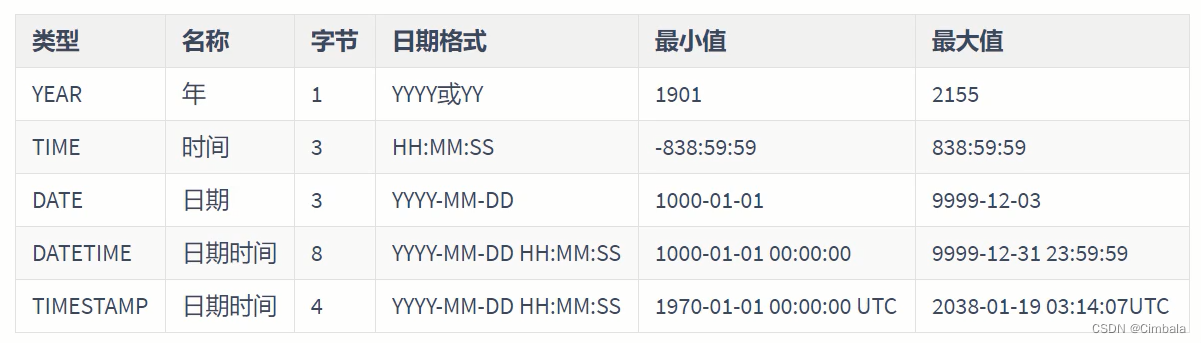
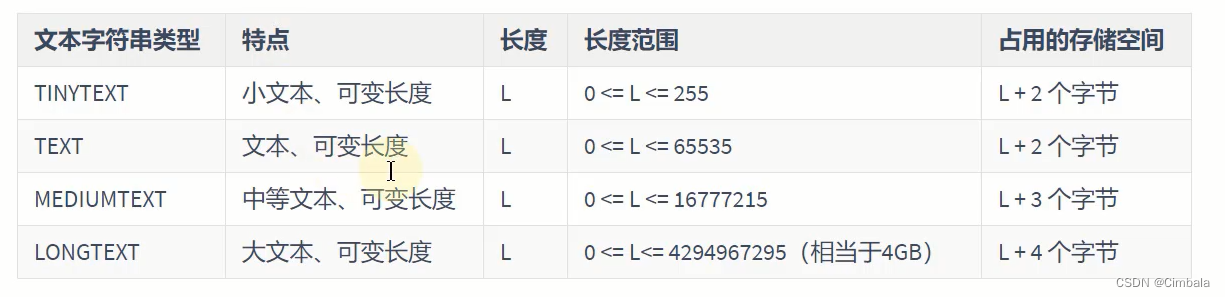
3. 数据类型
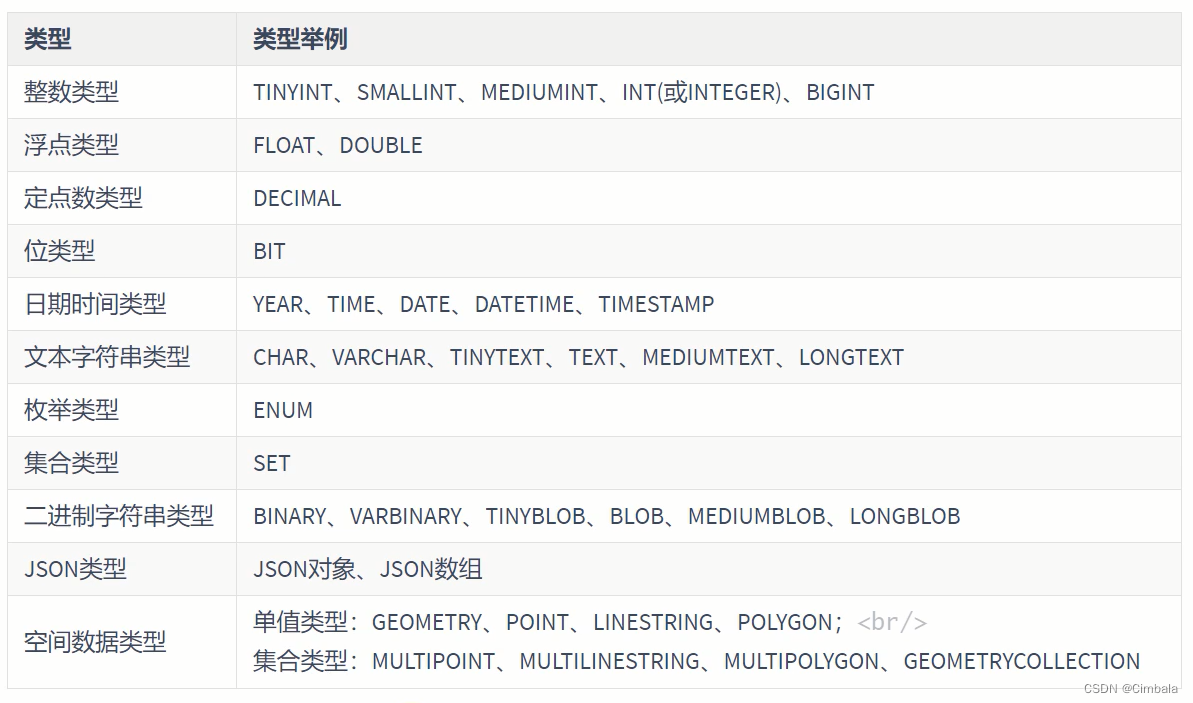
整数
浮点数


日期时间
Text类型
4. 创建表
-- 创建表
# 方式1
create table if not exists myemp1(
id int,
emp_name varchar(15),#使用VARCHAR来定义字符串,必须在使用VARCHAR时指明其长度。
hire_date date
);
# 查看表结构
DESC myemp1;
#查看创建表的语句结构
SHOW CREATE TABLE myemp1; #如果创建表时没有指明使用的字符集,则默认使用表所在的数据库的字符集。
# 方式2 基于现有的表创建,同时导入数据
create table myemp2 as
select employee_is,last_name,salary from employess;
#说明1:查询语句中字段的别名,可以作为新创建的表的字段的名称。
#说明2:查询语句结构比较丰富,可以使用各种SELECT
CREATE TABLE myemp3 AS
SELECT e.employee_id emp_id,e.last_name lname,d.department_name
FROM employees e JOIN departments d ON e.department_id = d.department_id;
5. 管理表
-- 修改表 ALTER TABLE
#添加一个字段
ALTER TABLE myemp1 ADD salary DOUBLE(10,2); #默认添加到表中的最后一个字段的位置
ALTER TABLE myemp1 ADD phone_number VARCHAR(20) FIRST;
ALTER TABLE myemp1 ADD email VARCHAR(45) AFTER emp_name;
ALTER TABLE myemp1 ADD salary DOUBLE(10,2); #默认添加到表中的最后一个字段的位置
#修改一个字段:数据类型、长度、默认值(略)
ALTER TABLE myemp1 MODIFY emp_name VARCHAR(25) ;
ALTER TABLE myemp1 MODIFY emp_name VARCHAR(35) DEFAULT 'aaa';
# 重命名一个字段
ALTER TABLE myemp1 CHANGE salary monthly_salary DOUBLE(10,2);
ALTER TABLE myemp1 CHANGE email my_email VARCHAR(50);
# 删除一个字段
alter table myemp1 drop column my_email
-- 重命名表
#方式1:
RENAME TABLE myemp1 TO myemp11;
#方式2:
ALTER TABLE myemp2 RENAME TO myemp12;
-- 删除表
#不光将表结构删除掉,同时表中的数据也删除掉,释放表空间
drop table if exists myemp2;
--清空表
#清空表,表示清空表中的所有数据,但是表结构保留。
TRUNCATE TABLE employees_copy;
6. 对比 TRUNCATE TABLE 和 DELETE FROM
相同点: 都可以实现对表中所有数据的删除,同时保留表结构。
不同点:
TRUNCATE TABLE:一旦执行此操作,表数据全部清除。同时,数据是不可以回滚的。
DELETE FROM:一旦执行此操作,表数据可以全部清除(不带WHERE)。同时,数据是可以实现回滚的。
DDL 和 DML 的说明
① DDL的操作一旦执行,就不可回滚。指令SET autocommit = FALSE对DDL操作失效。(因为在执行完DDL
操作之后,一定会执行一次COMMIT。而此COMMIT操作不受SET autocommit = FALSE影响的。)
② DML的操作默认情况,一旦执行,也是不可回滚的。但是,如果在执行DML之前,执行了
SET autocommit = FALSE,则执行的DML操作就可以实现回滚。
二、DQL 查询
1. 语法顺序
select – distinct – from – join – on – where – group by – having – union – order by – limit
2. 执行顺序
- from
- on
- join
- where
- group by
- sum、count、max、avg
- having
- select
- distinct
- union
- orderby
- limit
3. 执行过程解析
第一步:
所有查询语句都是从from开始执行,在执行的过程中,每个步骤都会为下一个步骤生成一张虚拟表,这张虚拟表将作为下一个执行步骤的输入。
首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表vt1。from子句执行顺序为从后往前、从右到左,from子句中写在最后的表(基础表 driving table)将被最先处理,即最后的表为驱动表,当from子句中包含多个表的情况下,我们需要选择数据最少的表作为基础表。
第二步:
应用on筛选器,on中的逻辑表达式将应用到vt1中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表vt2。
第三步:
应用join筛选器,如果指定了outer join保留表中未找到匹配的行将作为外部行添加到虚拟表 vt2,生成虚拟表 vt3。【left outer join把左表记为保留表,right outer join右表记为保留表,full outer join把左右表都作为保留表】
在虚拟表vt2表的基础上添加保留表中被过滤条件过滤掉的数据,非保留表中的数据被赋予NULL值,最后生成虚拟表 vt3。如果from子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1~3,直到处理完所有的表为止。
第四步:
如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:
应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4。由于数据还没有分组,因此现在还不能在where过滤器中使用聚合函数对分组统计的过滤。同时,由于还没有进行列的选取操作,因此在select中使用列的别名也是不被允许的。
对于包含outer join子句的查询,到底在on筛选器还是用where筛选器指定逻辑表达式呢?
on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。
举个简单的例子:有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果,我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x’的话,left outer join会把x班级的所有学生记录找回,所以只能在where筛选器中应用学生.班级=‘x’ 因为它的过滤是最终的。
第六步:
应用group by筛选器,group by 子句将虚拟表 vt4 中的行的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。
从这一步开始,后面的语句中都可以使用SELECT中的别名。
第七步:
对虚拟表vt5应用cube或者rollup选项,会为vt5生成超组,生成vt6.
第八步:
应用having筛选器,生成vt7。
having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:
处理select子句,将vt7在select中出现的列筛选出来,生成vt8。
第十步:
应用distinct子句,vt8中移除相同的行,生成vt9。
事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:
应用order by子句,按照order_by_condition排序vt9, 此时返回的一个游标vc10 ,而不是虚拟表。
sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用 order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十一步:
应用limit offset子句,从vc10的开始处选择指定数量行,生成虚拟表 vt11。
limit y 分句表示: 读取 y 条数据
limit x, y 分句表示: 跳过 x 条数据,读取 y 条数据
limit y offset x 分句表示: 跳过 x 条数据,读取 y 条数据
第十一步:
应用top选项,此时才返回结果给请求者即用户。
4. 语句记录
4.1 查询两个时间不在某段时间范围内
select l.*, r.start_time,r.end_time
from stu_leader_info l,stu_order_receive r
where l.id = '1574246139373342722'
and l.id = r.receiver_id
and r.start_time not between '2022-09-20 00:00:00.0' and '2022-09-26 00:00:00.0'
and r.end_time not between '2022-09-20 00:00:00.0' and '2022-09-26 00:00:00.0'
4.2 查询领队接单时间不在某段时间范围内,且如果领队没有接单时间也查出来
select l.*,r.start_time,r.end_time
from stu_leader_info as l
left join
(select *
from stu_order_receive
where stu_order_receive.start_time not between '2022-09-20 00:00:00.0' and '2022-09-26 00:00:00.0'
and stu_order_receive.end_time not between '2022-09-20 00:00:00.0' and '2022-09-26 00:00:00.0'
) as r
on l.id = r.receiver_id
4.3 SQL left join 左表合并去重 并 合并重复列值
4.4 SQL 多表查询
三、DML 更新
# UPDATE .... SET .... WHERE ...
UPDATE emp1 SET hire_date = CURDATE() WHERE id = 5;
#同时修改一条数据的多个字段
UPDATE emp1 SET hire_date = CURDATE(),salary = 6000 WHERE id = 4;
四、DML 删除
# DELETE FROM .... WHERE....
DELETE FROM emp1 WHERE id = 1;
DELETE m,u FROM my_employees m
JOIN users u ON m.userid = u.userid
WHERE m.userid = 'Bbiri';
五、DML 新增
#方式1
① 没有指明添加的字段
#注意:一定要按照声明的字段的先后顺序添加
INSERT INTO emp1 VALUES (1,'Tom','2000-12-21',3400);
② 指明要添加的字段 (推荐)
# 说明:没有进行赋值的hire_date 的值为 null
INSERT INTO emp1(id,hire_date,salary,`name`) VALUES(2,'1999-09-09',4000,'Jerry');
③ 同时插入多条记录 (推荐)
INSERT INTO emp1(id,NAME,salary) VALUES (4,'Jim',5000), (5,'张俊杰',5500);
#方式2 将查询结果插入到表中
# 查询的字段一定要与添加到的表的字段一一对应
INSERT INTO emp1(id,NAME,salary,hire_date)
SELECT employee_id,last_name,salary,hire_date FROM employees WHERE department_id IN (70,60);
#说明:emp1表中要添加数据的字段的长度不能低于employees表中查询的字段的长度。如果emp1表中要添加数据的字段的长度低于employees表中查询的字段的长度的话,就有添加不成功的风险。
六、MySql 8 新特性:计算列
指的是某一列的值是通过别的列计算得来的。例如:a列值为1、b列值为2,c列不需要手动插入,定义a+b的结果为c的值,那么c就是计算列,是通过别的列计算得来的。CREATE TABLE 和 ALTER TABLE 中都支持增加计算列。
CREATE TABLE test1(
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL #字段c即为计算列
);
INSERT INTO test1(a,b) VALUES(10,20);
SELECT * FROM test1;
七、约束
约束是表级的强制规定。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。

如何添加 / 删除约束?
CREATE TABLE时添加约束
ALTER TABLE 时增加约束、删除约束
查看表中的约束
SELECT * FROM information_schema.table_constraints
WHERE table_name = '表名';
not null (非空约束)
限定某个字段 / 某列的值不允许为空

# 在 CREATE添加非空约束
CREATE TABLE test1(
id INT NOT NULL,
last_name VARCHAR(15) NOT NULL,
email VARCHAR(25),
salary DECIMAL(10,2)
);
# 在ALTER TABLE时添加约束
ALTER TABLE test1 MODIFY email VARCHAR(25) NOT NULL;
# 在ALTER TABLE时删除约束
ALTER TABLE test1 MODIFY email VARCHAR(25) NULL;
unique (唯一性约束)

# 在CREATE TABLE时添加约束
# CONSTRAINT 约束名 UNIQUE(被约束字段)
#在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
CREATE TABLE test2(
id INT UNIQUE, #列级约束
last_name VARCHAR(15) ,
email VARCHAR(25),
salary DECIMAL(10,2),
CONSTRAINT uk_test2_email UNIQUE(email) #表级约束
);
# 在ALTER TABLE时添加约束
#方式1:
ALTER TABLE test2 ADD CONSTRAINT uk_test2_sal UNIQUE(salary);
#方式2:
ALTER TABLE test2 MODIFY last_name VARCHAR(15) UNIQUE;
复合的唯一性约束
CREATE TABLE USER(
id INT,
`name` VARCHAR(15),
`password` VARCHAR(25),
#表级约束
CONSTRAINT uk_user_name_pwd UNIQUE(`name`,`password`)
);
删除唯一性约束
- 添加唯一性约束的列上也会自动创建唯一索引。
- 删除唯一约束只能通过删除唯一索引的方式删除。
- 删除时需要指定唯一索引名,唯一索引名就和唯一约束名一样。
- 如果创建唯一约束时未指定名称,如果是单列,就默认和列名相同;如果是组合列,那么默认和()中排在第一个的列名相同。也可以自定义唯一性约束名。
# 删除唯一性约束
ALTER TABLE 表名 DROP INDEX 索引名;
primary key (主键约束)


# 在CREATE TABLE时添加约束(一个表中最多只能有一个主键约束。)
CREATE TABLE test4(
id INT PRIMARY KEY, #列级约束
last_name VARCHAR(15),
salary DECIMAL(10,2),
email VARCHAR(25)
);
# 在ALTER TABLE时添加约束
ALTER TABLE test6 ADD PRIMARY KEY (id);
# 如何删除主键约束 (在实际开发中,不会去删除表中的主键约束!)
ALTER TABLE test6 DROP PRIMARY KEY;
复合主键约束
CREATE TABLE user1(
id INT,
NAME VARCHAR(15),
PASSWORD VARCHAR(25),
PRIMARY KEY (NAME,PASSWORD)
);
自增长列:AUTO_INCREMENT
某个字段的值自增

# 在CREATE TABLE时添加
CREATE TABLE test7(
id INT PRIMARY KEY AUTO_INCREMENT,
last_name VARCHAR(15)
);
# 在ALTER TABLE 时添加
ALTER TABLE test8 MODIFY id INT AUTO_INCREMENT;
# 在ALTER TABLE 时删除
ALTER TABLE test8 MODIFY id INT ;
#在MySQL 5.7中,删除连续值4,再新增,id会是5,再删除5,重启mysql服务器后,再新增,id会是4。
#在MySQL 5.7系统中,对于自增主键的分配规则,是由InnoDB数据字典内部一个计数器 来决定的,而该计数器只在内存中维护 ,并不会持久化到磁盘中。当数据库重启时,该计数器会被初始化。
#在MySQL 8.0中,删除连续值4,再新增,id会是5,再删除5,重启mysql服务器后,再新增,id会是6。
#MySQL 8.0 将自增主键的计数器持久化到重做日志中,每次计数器发生改变,都会将其写入重做日志中。如果数据库重启,InnoDB会根据重做日志中的信息来初始化计数器的内存值。
foreign key (外键约束)
限定某个表的某个字段的引用完整性。

# 在CREATE TABLE 时添加
# 先创建主表
CREATE TABLE dept1(
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(15)
);
# 再创建从表
CREATE TABLE emp1(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
emp_name VARCHAR(15),
department_id INT,
#表级约束
CONSTRAINT fk_emp1_dept_id FOREIGN KEY (department_id) REFERENCES dept1(dept_id)
);
# 在ALTER TABLE时添加外键约束
ALTER TABLE emp2 ADD CONSTRAINT fk_emp2_dept_id FOREIGN KEY(department_id) REFERENCES dept2(dept_id);
#在 MySQL 里,外键约束是有成本的,需要消耗系统资源。对于大并发的 SOL操作,有可能会不适合。比如大型网站的中央数据库,
#可能会`因为外键约束的系统开销而变得非常慢`。所以, MVSQL 允许你不使用系统自带的外键约束,在 应用层面 完成检査数据一致性的逻辑。
#也就是说,即使你不用外键约束,也要想办法通过应用层面的附加逻辑,来实现外键约束的功能,确保数据的一致性。
约束等级
-
Cascade方式:在父表上update/delete记录时,同步update/delete掉子表的匹配记录 -
Set null方式:在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not null -
No action方式:如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作 -
Restrict方式:同no action, 都是立即检查外键约束 -
Set default方式(在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别
# on update cascade on delete set null
CREATE TABLE dept(
did INT PRIMARY KEY, #部门编号
dname VARCHAR(50) #部门名称
);
CREATE TABLE emp(
eid INT PRIMARY KEY, #员工编号
ename VARCHAR(5), #员工姓名
deptid INT, #员工所在的部门
FOREIGN KEY (deptid) REFERENCES dept(did) ON UPDATE CASCADE ON DELETE SET NULL
#把修改操作设置为级联修改等级,把删除操作设置为set null等级
);
INSERT INTO dept VALUES(1001,'教学部');
INSERT INTO dept VALUES(1002, '财务部');
INSERT INTO dept VALUES(1003, '咨询部');
INSERT INTO emp VALUES(1,'张三',1001); #在添加这条记录时,要求部门表有1001部门
INSERT INTO emp VALUES(2,'李四',1001);
INSERT INTO emp VALUES(3,'王五',1002);
# emp有引用dept的1002都会同步update
UPDATE dept SET did = 1004 WHERE did = 1002;
# dept的1004会删掉,但是emp引用过1004的会置为NULL
DELETE FROM dept WHERE did = 1004;
删除外键约束
#删除外键约束
ALTER TABLE emp1 DROP FOREIGN KEY fk_emp1_dept_id;
#再手动的删除外键约束对应的普通索引
SHOW INDEX FROM emp1;
ALTER TABLE emp1 DROP INDEX fk_emp1_dept_id;
check (检查约束)
检查某个字段的值是否符合XXX要求,一般指的是值的范围。MySQL5.7 不支持CHECK约束,MySQL8.0支持CHECK约束。
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) CHECK(salary > 2000)
);
default (默认值约束)
给某个字段某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。
# 在CREATE TABLE添加约束
CREATE TABLE test11(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) DEFAULT 2000
);
# 在ALTER TABLE添加约束
ALTER TABLE test12 MODIFY salary DECIMAL(8,2) DEFAULT 2500;
# 在ALTER TABLE删除约束
ALTER TABLE test12 MODIFY salary DECIMAL(8,2);
八、命名规则
MySQL在Linux下数据库名、表名、列名、别名大小写规则:
1.数据库名、表名、表名的别名、变量名是严格区分大小写的
2.关键字、函数名称在SQL中不区分大小写
3.列名、列名的别名在所有情况下均是忽略大小写的
MySQL在Windows下全部不区分大小写
九、目录结构
















 3104
3104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









