









NEURAL READING COMPREHENSION AND BEYOND
https://cs.stanford.edu/~danqi/papers/thesis.pdf
NEURAL READING COMPREHENSION AND BEYOND
总算是把陈丹琦学姐的毕业论文看完了,这篇长达156页的论文不得不服啊。这篇笔记会总结一下各个部分的中心思想,帮助大家理解论文所讲的内容和模型。
在其他笔记当中提到过的模型就不会再详细讲解了,链接都会在文章相应的位置给出来,希望大家都能有所收获。
1. 论文简介
论文的第一章首先借助MCtest数据集中的一个儿童故事的例子,介绍了机器阅读理解所包含的内容(需要完成的任务)并提出阅读理解是用来评估机器对于人类自然语言的理解程度的有效工具。

阅读理解的任务:
- part of speech tagging 词性标注
- named entity recognition 命名实体识别
- syntactic parsing 句法分析
- coreference resolution 指代消除
机器阅读理解的研究已经有了很长的历史,而近期得到较好发展归因于:
(1)大规模的监督数据集的产生
(2)神经阅读理解模型的发展
相关贡献:
- 首次对神经阅读理解进行研究,提出Stanford attentive reader
- 分析深层次神经阅读理解学到的内容,理解神经模型和现有基于特征模型的差异
- 提出基于开放域问答的DrQA
- 提出基于对话的问答系统CoQA
(第一章涉及的其他内容在之后的章节都会详细讲解,此处不再赘述)
(一)神经阅读理解:基础
2. 阅读理解回顾
2.1 机器阅读理解历史
先对早期机器阅读理解的发展进行介绍,当时由于数据集以及模型两方面的原因,阅读理解被视为一项太难的任务,没能得到突破性的进展。
到2013年,机器学习的方法得到了快速的发展,更多的监督数据集产生了,如MCtest和Processbank,进而带来了一大波机器学习模型的产生(主要产生于2015年)但是,这些改进依旧存在一定的问题,如高度依赖已有的语言工具,难以构造有效的特征,数据集规模不够大。
突破性的进展发生在2015年,Hermann提出了一个廉价的用于创建大规模监督学习阅读理解数据集的方法,构建了CNN/daily mail数据集,并提出了一个包含注意力机制的LSTM模型,attentive reader,而陈丹琦等人在2016年提出了另外一个基于简单的神经网络的阅读理解模型,达到了这一数据的最佳效果。但是,由于数据集的构建存在噪音,且有共指错误的现象,限制了阅读理解的进一步发展。
于是,2016年新数据集SQuAD的出现带动了一大波阅读理解模型的产生,这些模型都是端到端的深度学习/神经阅读理解模型,具有以下优点:自动学习特征;词嵌入缓解变量稀疏的问题;概念简单,将任务转换为构建神经网络结构的问题。
2.2 任务定义
阅读理解任务可以被看做一个监督学习问题,给定 { ( p i , q i , a i ) } i = 1 n \{(p_i,q_i,a_i)\}_{i=1}^n {(pi,qi,ai)}i=1n,学习一个预测函数来完成基于文章和问题的答案生成任务 f : ( p , q ) → a f:(p,q) \rightarrow a f:(p,q)→a
根据答案的不同,现有的阅读理解任务可以分为以下几类:
- 完形填空(使用正确率评估模型好坏)
- 单项选择(正确率);
- 范围预测(与ground truth比较,用exact match或F1 score);
- 开放式回答(BLEU,Meteor,ROUGE等评估方法)
2.3 阅读理解 vs. 问答
阅读理解可以视为问答的一个例子,两者存在关系也有一定的区别。
问答的最终目标是回答人们各种类型的问题,需要有足够多的资源才能回答。这就涉及到如何找到并识别出相关资源,如何从不同的资源中整合出答案,人们经常问哪些问题。
而阅读理解只要求对某一段特定文字有足够的理解,不要求给定文字外的资源。
2.4 数据集和模型
正如前文所述,模型和数据集是推动机器阅读理解的动力。下图给出了近年来各数据集和模型的发展情况:

3. 神经阅读理解模型
3.1 以往的方法:基于特征的模型
以往对于阅读理解任务的研究方法大多基于特征建模,以陈丹琦(2016)的在CNN/daily mail上使用的方法为例。
它的主要思想是构建一个传统的基于特征提取的分类器,以检测哪些特征对于该任务而言比较重要。
为每一个候选实体设计一个特征向量 f p , q ( e ) f_{p,q}(e) fp,q(e),学习一个权重向量 W T W^T WT 使得正确答案的ranking比其他候选实体高(即转换成候选实体的ranking问题,将ranking得分最高的实体作为答案) W T f p , q ( a ) > W T f p , q ( e ) , ∀ e ∈ E ∩ p ∖ { a } W^Tf_{p,q}(a) > W^Tf_{p,q}(e), \forall e \in E\cap p \setminus \{a\} WTfp,q(a)>WTfp,q(e),∀e∈E∩p∖{a}
模型的具体实现可以参考对该论文的解析:斯坦福机器阅读理解模型Stanford Attentive Reader
正如前文所述,特征提取相关的模型具有需要选取特征,且不具备较大的泛化能力的缺点,因此引入神经网络方法。
3.2 神经网络方法:Stanford Attentive Reader
相关思想:
在正式介绍Stanford Attentive Reader之前,对需要了解的一些模型相关的知识点进行了简短的概括,包括word embedding,RNN,注意力机制等基础知识,此处不再赘述,直接从模型部分开始整理。
模型:
在介绍模型细节之前先把模型的整体框架图拿出来以便理解。
该图是陈丹琦(2017)的论文中Stanford attentive reader模型在阅读理解范围预测类问题上的使用。总的来说,模型分成两个部分,对问题进行encoding(即下图左),以及对文章进行encoding(即下图右)

先对简单一点的左边部分,即问题encoding部分进行介绍。
- 将问题中的每一个单词 q i q_i qi 进行word embedding得到 E ( q i ) ∈ R d \mathbf{E}(q_i) \in \mathbb{R}^d E(qi)∈Rd
- 对embedding得到的词向量使用一个双向的LSTM,得到隐藏层信息: q 1 , q 2 , . . . . . . , q l q = B i L S T M ( E ( q 1 ) , E ( q 2 ) , . . . . . . , E ( q l q ) ; Θ ( q ) ) ∈ R h \mathbf{q}_1,\mathbf{q}_2,......,\mathbf{q}_{l_q}=BiLSTM(\mathbf{E}(q_1),\mathbf{E}(q_2),......,\mathbf{E}(q_{l_q});\Theta^{(q)})\in \mathbb{R}^h q1,q2,......,qlq=BiLSTM(E(q1),E(q2),......,E(qlq);Θ(q))∈Rh
- 通过一层注意力将这些BiLSTM的隐藏单元加和得到单个向量表示,其中 b j b_j bj衡量问题中每个单词的重要性, w q ∈ R h \mathbf{w}^q\in \mathbb{R}^h wq∈Rh是需要学习的权重参数,得到问题最终的向量表示 q ∈ R h \mathbf{q}\in \mathbb{R}^h q∈Rh: b j = e x p ( w q T q j ) ∑ j ′ e x p ( w q T q j ′ ) q = ∑ j b j q j b_j=\frac{exp(\mathbf{w}^{qT}\mathbf{q}_j)}{\sum _{j'}exp(\mathbf{w}^{qT}\mathbf{q}_j')} \\ \mathbf{q} = \sum_j b_j\mathbf{q}_j bj=∑j′exp(wqTqj′)exp(wqTqj)q=j∑bjqj(tip: 在以往的实验中,有学者会直接将双向LSTM中两个方向的隐藏单元的向量concate,但是作者发现添加注意力机制能让模型更加关注有关联的单词,对结果更加有效)
上述过程用图形表示如下:

然后是复杂一点的文章encoding的部分。
总体来说也是需要用一个向量来表示文章中的每一个单词,然后feed到一个BiLSTM当中,得到每个词对应的表示,即: p 1 , p 2 , . . . . . . , p l p = B i L S T M ( p ~ 1 , p ~ 2 , . . . . . . , p ~ l p ; Θ ( p ) ) ∈ R h \mathbf{p}_1,\mathbf{p}_2,......,\mathbf{p}_{l_p}=BiLSTM(\tilde{\mathbf{p}}_1,\tilde{\mathbf{p}}_2,......,\tilde{\mathbf{p}}_{l_p};\Theta^{(p)})\in \mathbb{R}^h p1,p2,......,plp=BiLSTM(p~1,p~2,......,p~lp;Θ(p))∈Rh注意,这里biLSTM的输入不再是简单的embedding,而是由多个部分组成。
文章每个词的词表示 p ~ i \tilde{\mathbf{p}}_i p~i 可以被分为两部分,第一部分是单词自身的属性,第二部分是文章单词和问题的相关性,分别用以下内容表示:
- 对于第一个部分,即单词自身性质的表示,作者将其分为四个小部分,第一是单词的embedding,即 f e m b ( p i ) = E ( p i ) ∈ R d f_{emb}(p_i)=\mathbf{E}(p_i) \in \mathbb{R}^d femb(pi)=E(pi)∈Rd,第二是单词的词性Part of speech,即 P O S ( p i ) POS(p_i) POS(pi),第三是单词的命名实体识别named entity recognition,即 N E R ( p i ) NER(p_i) NER(pi),第四是单词的词频term frequency,即 T F ( p i ) TF(p_i) TF(pi),作者将后三者视为单词的token,表示为 f t o k e n ( p i ) = ( P O S ( p i ) , N E R ( p i ) , T F ( p i ) ) f_{token}(p_i)=(POS(p_i),NER(p_i),TF(p_i)) ftoken(pi)=(POS(pi),NER(pi),TF(pi)),其中,POS和NER都用独热码表示,因为所包含的类别并不多。
- 对于第二个部分,作者考虑了两种类型的词表示,分别为exact match和aligned question embedding
Exact match: f e x a c t _ m a t c h ( p i ) = I ( p i ∈ q ) ∈ R f_{exact\_match}(p_i) = \mathbb{I}(p_i\in q)\in \mathbb{R} fexact_match(pi)=I(pi∈q)∈R,这个部分是用来判断文章的单词与问题的单词是否完全匹配的。
Aligned question embeddings:这里是用来判断文章单词与问题单词的相似度的(在作者的DrQA中有类似的处理,其中exact match被视为hard attention,而此处则视为soft attention) f a l i g n ( p i ) = ∑ j a i , j E ( q j ) f_{align}(p_i) = \sum _{j} a_{i,j}\mathbf{E}(q_j) falign(pi)=j∑ai,jE(qj)其中, E ( q j ) \mathbf{E}(q_j) E(qj) 是每个问题单词的embedding, a i j a_{ij} aij 是注意力权重,表示文章中单词 p i p_i pi 与问题中单词 q j q_j qj 的相似度,其计算方法为
a i , j = e x p ( M L P ( E ( p i ) ) T M L P ( E ( q j ) ) ) ∑ j ′ e x p ( M L P ( E ( p i ) ) T M L P ( E ( q j ′ ) ) ) a_{i,j} = \frac{exp(MLP(\mathbf{E}(p_i))^TMLP(\mathbf{E}(q_j)))}{\sum_{j'}exp(MLP(\mathbf{E}(p_i))^T MLP(\mathbf{E}(q_{j'})))} ai,j=∑j′exp(MLP(E(pi))TMLP(E(qj′)))exp(MLP(E(pi))TMLP(E(qj)))其中, M L P ( x ) = m a x ( 0 , W M L P x + b M L P ) MLP(\mathbf{x})=max(0,\mathbf{W_{MLP}}\mathbf{x}+\mathbf{b_{MLP}}) MLP(x)=max(0,WMLPx+bMLP) 是经过ReLU激活的一个全连接层。
最后,我们可以得到文章单词的四个部分的表示:
p
i
~
=
(
f
e
m
b
(
p
i
)
,
f
t
o
k
e
n
(
p
i
)
,
f
e
x
a
c
t
_
m
a
t
c
h
(
p
i
)
,
f
a
l
i
g
n
(
p
i
)
)
\tilde{\mathbf{p}_i}=(f_{emb}(p_i), f_{token}(p_i),f_{exact\_match}(p_i),f_{align}(p_i))
pi~=(femb(pi),ftoken(pi),fexact_match(pi),falign(pi))同样的,将这个部分的模型思想在图中表示出来。

得到两个部分(问题和文章)的encoding之后,就需要进行答案预测了,即检测答案所在的范围,为此再次使用注意力机制的思想,并训练了两个单独的分类器,分别用来判断单词作为开始和作为结尾的可能性。
使用一个双线性乘积(被证实有效的工具)来获取文章和问题之间的相似性:
P
(
s
t
a
r
t
)
(
i
)
=
e
x
p
(
p
i
W
(
s
t
a
r
t
)
q
)
∑
i
′
e
x
p
(
p
i
′
W
(
s
t
a
r
t
)
q
)
P
(
e
n
d
)
(
i
)
=
e
x
p
(
p
i
W
(
e
n
d
)
q
)
∑
i
′
e
x
p
(
p
i
′
W
(
e
n
d
)
q
)
P^{(start)}(i) = \frac{exp(\mathbf{p}_i\mathbf{W}^{(start)}\mathbf{q})}{\sum_{i'}exp(\mathbf{p}_{i'}\mathbf{W}^{(start)}\mathbf{q})} \\ P^{(end)}(i) = \frac{exp(\mathbf{p}_i\mathbf{W}^{(end)}\mathbf{q})}{\sum_{i'}exp(\mathbf{p}_{i'}\mathbf{W}^{(end)}\mathbf{q})}
P(start)(i)=∑i′exp(pi′W(start)q)exp(piW(start)q)P(end)(i)=∑i′exp(pi′W(end)q)exp(piW(end)q) 其中,
W
(
s
t
a
r
t
)
,
W
(
e
n
d
)
∈
R
h
∗
h
\mathbf{W}^{(start)},\mathbf{W}^{(end)}\in \mathbb{R}^{h*h}
W(start),W(end)∈Rh∗h是需要学习的参数。其实,这里和注意力机制有一定的差别,注意力机制是先求出注意力权重,再用权重对词向量进行加权求和,而这里直接用归一化的权重来进行预测。
训练的过程中使用交叉熵损失函数:
L
=
−
∑
l
o
g
P
(
s
t
a
r
t
)
(
a
s
t
a
r
t
)
−
∑
l
o
g
P
(
e
n
d
)
(
a
e
n
d
)
L = -\sum logP^{(start)}(a_{start})-\sum logP^{(end)}(a_{end})
L=−∑logP(start)(astart)−∑logP(end)(aend)参数更新过程中使用SGD进行更新。
模型扩展
上文讲述的是模型在范围预测类阅读理解方面的运用,现在将模型扩展到其他类型的阅读理解问题上:
- 完形填空类:该部分作者在2016年发布的论文中详细介绍过,大意是用问题和文章构建attention,加权得到文章的向量表示,然后用这个向量来预测空缺的单词或实体。 α i = e x p ( p i W q ) ∑ i ′ e x p ( p i ′ W q ) o = ∑ i α i p i P ( Y = e ∣ p , q ) = e x p ( W e ( a ) o ) ∑ e ′ ∈ ϵ e x p ( W e ′ ( a ) o ) \alpha_i = \frac{exp(\mathbf{p}_i\mathbf{Wq})}{\sum_{i'}exp(\mathbf{p}_{i'}\mathbf{W}\mathbf{q})}\\\mathbf{o} = \sum _i\alpha_i\mathbf{p}_i\\P(Y=e|p,q)=\frac{exp(\mathbf{W}_e^{(a)} \mathbf{o})}{\sum_{e'\in \epsilon}exp(\mathbf{W}_{e'}^{(a)}\mathbf{o})} αi=∑i′exp(pi′Wq)exp(piWq)o=i∑αipiP(Y=e∣p,q)=∑e′∈ϵexp(We′(a)o)exp(We(a)o)这里附上相关笔记的链接,模型细节不再赘述【笔记1-3】斯坦福机器阅读理解模型Stanford Attentive Reader
- 单选题:有k个备选的答案 A = { a 1 . a 2 , . . . . . . , a k } A=\{a_1.a_2,......,a_k\} A={a1.a2,......,ak},可以再添加一biLSTM将每个备选答案都encode成一个向量,类似于问题encoding的步骤。然后计算出完形填空中类似的向量 o \mathbf{o} o,和每一个备选答案向量进行比较预测答案,并使用交叉熵损失函数用于训练: P ( Y = i ∣ p , q ) = e x p ( a i W ( a ) o ) ∑ i ′ = 1 , 2 , . . . . . , k e x p ( a i ′ W ( a ) o ) P(Y=i|p,q)=\frac{exp(\mathbf{a}_i\mathbf{W}^{(a)} \mathbf{o})}{\sum_{i'=1,2,.....,k}exp(\mathbf{a}_{i'}\mathbf{W}^{(a)}\mathbf{o})} P(Y=i∣p,q)=∑i′=1,2,.....,kexp(ai′W(a)o)exp(aiW(a)o)
- 自由问答:在现有的网络中添加一个LSTM序列decoder,假设答案为 a = ( a 1 , a 2 , . . . . . . , a l a ) a=(a_1,a_2,......,a_{l_a}) a=(a1,a2,......,ala),decoder每次生成一个单词,对应的条件概率和目标函数为: P ( a ∣ p , q ) = P ( a ∣ o ) = ∏ j = 1 l a P ( a j ∣ a < j , o ) L = − l o g P ( a ∣ p , q ) = − l o g ∑ j = 1 L P ( a j ∣ a < j , o ) P(a|p,q)=P(a|\mathbf{o})=\prod_{j=1}^{l_a}P(a_j|a_{<j},\mathbf{o}) \\ L=-logP(a|p,q)=-log \sum_{j=1}^LP(a_j|a_{<j},\mathbf{o}) P(a∣p,q)=P(a∣o)=j=1∏laP(aj∣a<j,o)L=−logP(a∣p,q)=−logj=1∑LP(aj∣a<j,o) 预测时,每次预测一个单词,并将预测出来的单词作为下一次预测的输入。此外,提出带有复制机制的总结型阅读理解任务将对阅读理解十分有用。
Tips:对比以上几种类型的阅读理解任务,可以发现后面三种都对整个passage进行了encoding,而范围预测类问题是对文章的每一个单词进行encoding,这是因为进行范围预测时,需要对每一个词作为开头和结尾的概率进行预测,而其他类型的阅读理解中只需要根据文章整体与问题之间的关系来找到答案,因此可以用一个向量来表示整篇文章。
3.3 实验
数据集:
CNN/daily mail,SQuAD

实现细节:
- stacked BiLSTMs:三层BiLSTM。
- dropout:在word embedding和LSTM的输入单元,隐藏单元上dropout,且每个time step内被dropout的单元相同。
- word embedding:使用预训练的word embedding,固定某些词,fine-tune一些重要的词。
- 模型:Stanford CoreNLP + batch size32
CNN/daily mail:100维词向量(使用预训练好的100维GloVe词向量)+ attention参数初始化[-0.01, 0.01]均匀分布 + 单层BiLSTM权重初始化高斯分布N(0, 0.1) + 隐藏层h CNN(128),Dailymail(256) + 优化函数SGD + 学习率0.1 + dropout 0.2
SQuAD:3层BiLSTM h=128 + 优化函数Adamax + dropout 0.3 + 300维词向量(fine-tune 1000个频率最高的词)
(以上模型在陈丹琦2016和2017的论文中进行了详细描述,两者存在细微差别,读者可自行查看)
实验结果:
在CNN/Daily Mail上的实验结果:

在SQuAD上的实验结果:

由于向量是作者自己构造的,因此通过切除分析来说明各个构造的向量的重要性,可知align和exact match两个特征的组合对于模型而言最为重要。
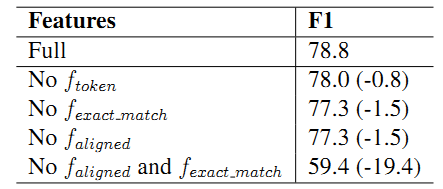
Tips:由切除分析的结果可知,token向量,也就是和文章自身相关属性的向量对于模型效果影响不大,直观的说,给定一篇文章的自身性质对于回答问题没有太大帮助,跟问题联系起来的部分特征才具有真正的价值。
另外,exact match和aligned向量单独的影响不大,这个可以解释为两者之间存在一定的overlap,当去掉其中一个时,其包含的信息可以用另外一个向量部分表示,因此两者都去掉对模型的影响更大。
另外,在文章中还对模型学到的内容进行了分析,具体的内容作者已经在2016年的论文中详细介绍,这里不再赘述。
【笔记1-3】斯坦福机器阅读理解模型Stanford Attentive Reader
3.4 进一步研究
- 单词表示:
(1)Character embedding:用字符级别的嵌入方式来表征单词,可以让模型在很少见的单词以及词库以外的单词上有提升。现在常用的是将每个单词用一串字符向量表示,然后用卷积神经网络对字符向量做卷积: f i = t a n h ( w T c i : i + w − 1 + b ) f_i=tanh(\mathbf{w}^T\mathbf{c}_{i:i+w-1}+b) fi=tanh(wTci:i+w−1+b)最后对 f i f_i fi做max pooling: f = m a x i { f i } f = max_i \{f_i\} f=maxi{fi}通过使用不同的filter最后得到单词的字符级的embedding
(2)Contextualized word embeddings:与传统的词嵌入方式不同,传统方法中一个单词对应一个词向量,但是这个方法将单词的词向量表示为整个句子的函数,这样词向量能够反映更为复杂的特征,并且单词的向量还能根据上下文意思进行改变(比如单词run在不同的句子当中可能有不同含义,就需要不同的词向量)
以ELMo为例,给定一系列单词 ( x 1 , x 2 , . . . . . , x n ) (x_1,x_2,.....,x_n) (x1,x2,.....,xn),使用一个L层的前向LSTM来计算序列的概率: P ( x 1 , x 2 , . . . . . , x n ) = ∏ k = 1 n P ( x k ∣ x 1 , x 2 , . . . . . , x k − 1 ) P(x_1,x_2,.....,x_n)=\prod_{k=1}^{n}P(x_k|x_1,x_2,.....,x_{k-1}) P(x1,x2,.....,xn)=k=1∏nP(xk∣x1,x2,.....,xk−1)在预测的过程中只用到LSTM → h k ( L ) \underset{h}{\rightarrow}_k^{(L)} h→k(L)的顶层。
同样的,使用一个后向的LSTM来预测 x k − 1 x_{k-1} xk−1的概率,于是模型的目标就是最大化两个方向的似然概率: ∑ k = 1 n ( l o g P ( x k ∣ x 1 , . . . . . , x k − 1 ; Θ x , → Θ L S T M , Θ s ) + l o g P ( x k ∣ x k + 1 , . . . . . , x n ; Θ x , ← Θ L S T M , Θ s ) \sum_{k=1}^n(logP(x_k|x_1,.....,x_{k-1};\Theta_x,\underset{\Theta_{LSTM}}{\rightarrow},\Theta_s)+logP(x_k|x_{k+1},.....,x_n;\Theta_x,\underset{\Theta_{LSTM}}{\leftarrow},\Theta_s) k=1∑n(logP(xk∣x1,.....,xk−1;Θx,ΘLSTM→,Θs)+logP(xk∣xk+1,.....,xn;Θx,ΘLSTM←,Θs)其中 Θ x , Θ s \Theta_x,\Theta_s Θx,Θs是word embedding和softmax的参数,最后上下文词向量由所有的BiLSTM层以及输入的word embedding线性组合,并乘上一个 γ \gamma γ得到: E L M o ( x k ) = γ ( s 0 x k + ∑ j = 1 L → s j → h k ( j ) + ∑ j = 1 L ← s j ← h k ( j ) ) ELMo(x_k)=\gamma(s_0\mathbf{x}_k+\sum_{j=1}^L\underset{s}{\rightarrow}_j\underset{\mathbf{h}}{\rightarrow}_k^{(j)}+\sum_{j=1}^L\underset{s}{\leftarrow}_j\underset{\mathbf{h}}{\leftarrow}_k^{(j)}) ELMo(xk)=γ(s0xk+j=1∑Ls→jh→k(j)+j=1∑Ls←jh←k(j))此外为了解决双向LSTM中存在的自己看自己的问题,还有研究提出了对其中部分单词加mask再学习的思路,避免了自己看自己问题的出现,而且方法确实有效,此处不再赘述。 - 注意力机制:
有过很多注意力机制及其变体的研究,目的是捕捉问题与答案之间的相关性


(1)Bidirectional attention:这里的模型与前面介绍过的作者在17年文章中使用的注意力机制提取特征方法类似,但作者的是passage-to-question attention,而这里计算的是question-to-passage attention: f q _ a l i g n ( q i ) = ∑ j b i , j E ( p j ) f_{q\_align}(q_i)=\sum_jb_{i,j}\mathbf{E}(p_j) fq_align(qi)=j∑bi,jE(pj)之后就只需要将 f q _ a l i g n ( q i ) f_{q\_align}(q_i) fq_align(qi)作为question encoding的输入。但是作者指出这种方法并不如他们的简便有效,并且由于问题比较简短,没必要对问题的encoding做过于复杂的操作。
(2)Self-attention over passage:这个方法提出的想法是对文章中词与词之间的关系进行研究,可以用来解决共指问题以及汇总文章信息。 α i , j = e x p ( g M L P ( p i , p j ) ) ∑ j ′ e x p ( g M L P ( p i , p j ′ ) ) c i = ∑ j α i , j p j \alpha_{i,j} = \frac{exp(g_{MLP}(\mathbf{p}_i,\mathbf{p}_j))}{\sum_{j'}exp(g_{MLP}(\mathbf{p}_i,\mathbf{p}_{j'}))}\\\mathbf{c_i} = \sum _j\alpha_{i,j}\mathbf{p}_j αi,j=∑j′exp(gMLP(pi,pj′))exp(gMLP(pi,pj))ci=j∑αi,jpj最后将 c i , p i \mathbf{c}_i,\mathbf{p}_i ci,pi concatenate 之后feed到一个BiLSTM中,作文章最后的向量表示。 - Alternatives to LSTMs:
LSTM的提出解决了RNN的长时间记忆问题,但LSTM因为存在的梯度消失问题很难优化,且可扩展性差,训练慢,无法进行深层次训练。
于是出现了很多LSTM的替代模型,如谷歌的transformer模型,运用残差网络和注意力机制加速训练;QANET采用多层卷积,自注意力机制和全连接层取得较好的性能;改进的simple recurrent unit(SRU),简化循环的同时保持模型能力。 - others:
针对阅读理解问题类型,使用更好的目标函数;使用数据增强的方法(如backtranslation)来实现模型性能的提升,下图即为数据增强之后模型效果的提升。

4. 阅读理解的未来发展
尽管前文所述的神经阅读理解在阅读理解领域已经有了很大的进步,但是与人工表现相比依旧存在很大的进步空间。
4.1 Is SQuAD Solved Yet?
尽管在SQuAD数据集上,机器已经实现了超越人类的表现,但是通过分析可以发现,模型依旧存在一些问题。从一些错误的例子可以看出,即便是在该数据集上表现最佳的bert模型,仍然缺乏对文本主体和事件之间内在结构的理解。
还有学者发现在文末添加一些分散注意力或存在语法问题的句子,会让模型表现大幅下降。这说明目前的模型严重依赖于文章和问题之间的词汇线索,且模型对于对抗性样本存在鲁棒性差等缺点。
总之,尽管模型在SQuAD上有了很高的正确率,但这些模型依旧停留在对文本浅层次结构信息的理解上,对于深层次结构的理解还是会犯很多简单的错误。因此,需要建立更为全面的数据集以及更有效的模型。
4.2 未来的工作:数据集
到目前为之提到的数据集CNN/Daily Mail以及SQuAD虽然都已经实现了机器阅读理解的超常表现,但这些数据集依旧属于比较简单的数据集,以SQuAD为例,它存在以下缺点:
- 问答的问题是根据一段文章提出的,两者存在很多重叠的单词
- 问答的问题是文本短距离的跨度预测
- 大部分的问答问题都是通过单个句子来预测,基本不需要多段文字推理
为了处理这些问题,产生了很多新的数据集,比如:
TriviaQA(先收集问题/答案对,然后构建相应的段落)RACE(用人类的标准化测试评估机器阅读理解能力,专家设定问题和答案)NarrativeQA(根据书或电影的情节摘要进行提问回答,由于答案缺乏一致性,很难评估)SQuAD 2.0(增加负样本例子)HotpotQA(问答问题需要分析多个支持文档)

4.3 未来的工作:模型
- Desiderata:除了准确率之外,未来的模型还需要考虑以下因素:
(1)速度和扩展性(Speed and Scalability)
解决思路:用非循环模型如transformer或SRU来替代LSTM;训练模型来跳过文章中不重要的部分;优化算法,multi-GPU及硬件;
(2)鲁棒性(Robustness)
需要考虑:如何在训练过程添加更多的对抗样本;在多数据集上做迁移学习和多任务学习以实现跨数据集的较好表现;打破标准的监督学习方法,创造更好的模型评估方法
(3)可解释性(Interpretability)
解决思路:要模型从文档中提取片段作为回答依据;模型生成理论依据
需要考虑:用什么样的训练集来达到这种级别的可解释性 - Structures and Modules:如果需要解决更为复杂的问题,现有模型还缺少了结构化和模块化。结构化被证实可以帮助模型找到很多相关信息,有助于回答问题;模块化任务可以将任务从复杂任务分解成简单任务,有助于模型在复杂问题上的扩展。
4.4 研究问题
- 如何衡量模型在这一领域取得的进步:用人类的标准化测试来评价机器阅读理解系统性能;将多个数据集集成为一个测试集进行评估,而不是仅仅对单个数据集进行测试
- 模型表征和结构哪个更重要:有时候简单模型也能达到较好的性能,但是模型捕捉到的文章特征就会少很多,两者的结合可能是未来的趋势(下图左右分别为复杂模型和简单模型)。

- 需要多少训练样本:一方面,数据集越大对模型表现能力越有帮助,另一方面,预训练模型可以帮助我们减少对于大规模数据集的依赖性,两者之间形成了一种权衡。未来可能需要在无监督学习和迁移学习上进行更多的研究。
(二)神经阅读理解:应用
5. 开放领域的问答
5.1 开放领域问答的历史
开放领域的问答于1999年开始时兴,TREC的比赛将QA track作为一个部分,要求提取出回答某一开放领域问题的文本。当时的模型普遍包含两个部分:信息提取系统IR(information retrieval)和基于窗口的单词评分系统。近来,KBs(knowledge bases)的出现,让这个领域得到了较大的发展,基于此产生的模型大多以语义分析和信息提取为主,但KBs依旧存在不完整,模式固定的缺点。
后来发展出了发展较为完善的问答系统,比如微软的AskMSR(基于数据冗余的搜索引擎问答系统)IBM的DeepQA(最具代表性的现代问答系统,依靠非结构化的信息和结构化的数据生成答案)和YodaQA(开源问答系统),为模型DrQA的表现评估提供了一个参考上界。
5.2 DrQA
这一部分主要基于陈丹琦2017年的论文展开,附上论文的详细解读【笔记1-2】基于维基百科的开放域问题问答系统DrQA
模型概述:目标是从维基百科中提取相关信息来回答问题,包含两个部分,document retriever用于提取与问题相关的文章,document reader用于从提取的文章中找到对应问题的答案。

(1)document retriever
对于相关文章提取部分,作者采用了经典的信息检索(非机器学习)思想来缩小搜索范围:分别计算问题和文章的bigram的TF-IDF向量,然后结合两个TF-IDF得到与问题最相关的五篇文章。
(2)document reader
对于问答部分,刚好符合前文所述的检测答案范围(span-based QA)的模型,Stanford attentive reader可以直接在这里使用。为了保证各个备选答案分数之间的可比性,使用未归一化的exp并对所有的文章范围取argmax作为最终的预测结果
(3)Distant supervision(DS)
如果将前文所述的在SQuAD上训练的模型放在开放领域问答上,会存在几个问题:首先,SQuAD的问题是基于文章内容产生的,这与开放域问答中的,先提出问题再从开放资源中找到答案不同;其次,问题对文章的依赖性太大;最后,SQuAD的数据集对于开放域问答而言太小了。因此引入一个可以自动生成训练样本的模型,distant supervision。
DS的基本思想是根据问题答案对,利用前面训练出来的document retriever提取最可能包含答案的文章,用找的文章和原本的问题答案对组成新的训练样本,即
f
(
q
,
a
)
⇒
f
(
p
,
q
,
a
)
i
f
p
∈
d
o
c
u
m
e
n
t
r
e
t
r
i
e
v
e
r
(
q
)
a
n
d
a
a
p
p
e
a
r
s
i
n
p
f(q,a)\Rightarrow f(p,q,a)\\ if \ p \in document \ retriever \ (q) \ and \ a \ appears \ in \ p
f(q,a)⇒f(p,q,a)if p∈document retriever (q) and a appears in p
5.3 模型评估
- QA数据集:基于开放领域问答的任务选择评估数据集(TREC,WebQuestions,WikiMovies)


- 实现细节:
处理wikipedia,保留5075182篇文章,包含9008962个不同的标记;
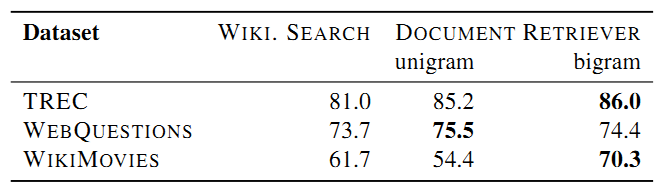
在DS实现过程中,基于问题使用document retriever提取相关性最高的5篇文章,去除不包含与已知答案完全匹配(no exact match)的段落,小于25个字大于1500个字的段落,若有的段落中包含命名实体,去除不包含命名实体的段落,从剩下的段落中根据答案区间找到备选小段落 - document retriever 的表现:结果表明使用bigram hashing的document retriever效果比维基搜索的效果好。
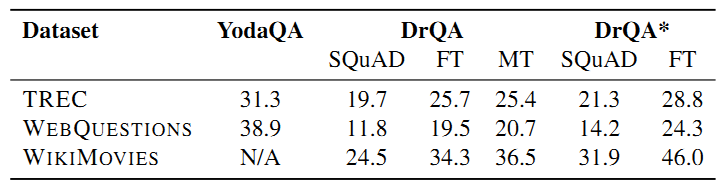
- 最终结果:用所有数据集来检测DrQA的性能,先在SQuAD上训练一个简单地document reader,然后基于SQuAD预训练一个document reader并使用每个数据集的远距离监督(DS)训练集对模型进行fine-tune,最后在SQuAD以及其他DS训练集上集合训练一个document reader。
结果表明引入DS和多任务学习对模型的提升效果不明显,表明其中存在任务迁移,而DS的单独引入对模型的提升可能是由于额外数据的引入,最终最好的模型是multitask (DS)
5.4 未来工作
基于DrQA已经达到的成果,提出未来在开放域问答上改进的方向:
- 从多个段落中汇总信息:现在的系统需要确保提取的段落中包含有一个正确的答案,但实际应用中并不是这样;无法保证不同段落分值之间的可比性;
- 使用更多的训练数据:如果有更大的训练集,模型的效果应该能够得到进一步的提升;可以使用前文所述的DS方法,但是需要考虑其中的降噪问题;加入负样本对于模型的提升也会有一定的帮助;
- 可训练的document retriever:前面提到过,document retriever使用信息检索的非机器学习方法得到的,希望有一个可训练的机器学习方法相关的document retriever;对document retriever 和document reader进行联合训练;
- 更好的document reader:可以用更好的阅读理解模型来替代这个部分,使整体效果得到提升;
- 更多的分析:需要进一步分析模型能够达到的效果,解决哪些问题。
6. 基于对话的问答
本部分内容取自 CoQA: A Conversational Question Answering Challenge (Siva Reddy, Danqi Chen, Christopher D. Manning) 详细解读请参考【笔记1-1】基于对话的问答系统CoQA (Conversational Question Answering)
6.1 相关研究
基于对话的问答系统和对话直接相关,常见的有两种类型:任务导向型和聊天机器人。前者是为了完成某个任务(如餐厅点餐)任务完成率和完成时间来衡量效果,后者只是以无目的的日常聊天为主,用聊天时长评估模型好坏。
本文提到的CoQA与基于图表进行对话的系统(Visual Dialog,Complex Sequential Question Answering)类似,与sequential question answering(将问题分解成简单问题)相关。
6.2 COQA:A Conversational QA Challenge
CoQA (Conversational Question Answering)对应的中文发音为“扣卡”,是一个用来衡量机器进行对话式问答能力的数据集,包含来自8000个对话的127000对问题+答案。设计这一数据集是为了还原人类对话的性质;保证答案的自然性;实现QA系统在不同领域的稳健性。
(1)目标任务: 给定一篇文章和一段对话,回答对话中的下一个问题。对话中的每一轮由问题(Q),答案(A),依据( R)组成,答案往往比依据简洁很多。回答问题时,需要考虑对话中的历史信息,比如回答 Q 2 Q_2 Q2时,要基于对话历史 Q 1 Q_1 Q1, A 1 A_1 A1以及回答依据 R 2 R_2 R2,可以简单表示为: A 2 = f ( Q 2 , Q 1 , A 1 , R 2 ) A n = f ( Q n , Q 1 , A 1 , . . . Q n − 1 , A n − 1 , R n ) A_2 = f(Q_2, Q_1, A_1, R_2) \\ A_n = f(Q_n, Q_1, A_1,...Q_{n-1},A_{n-1},R_n) A2=f(Q2,Q1,A1,R2)An=f(Qn,Q1,A1,...Qn−1,An−1,Rn)对于无法回答的问题,给出“unknown”的回答,不标注任何依据(R)
(2)数据收集过程:CoQA数据收集过程中,每个对话都包含一个提问者和回答者:
相对于单方面的回答系统,对话更加自然;
当一方给出模棱两可的问题或者错误的答案时,另一方可以据此进行标记;
当两者意见不统一时,可以在一个独立的聊天窗中进行讨论;
- 数据收集界面:


- 文章选取:
CoQA选取了七个领域的文章:MCTest (儿童故事); Project Gutenberg(literature);RACE(中学英语考试) ;CNN (新闻); wikipedia; AI2 Science Questions(科学文章); Writing Prompts(Reddit )
前五个领域的数据: 开发集100篇文章+测试集100篇文章+其余文章作为训练集
后两个领域的数据: 测试集100篇文章+其余文章作为训练集

- 收集多个答案:
由于问题的答案可能存在不同表述方式,即存在变体,因此在开发集和测试集中额外选取了三个答案。但是由于CoQA中的问题和答案以对话的形式展开,因此问题会影响答案,答案反过来又会影响到问题。为了保证对话的连贯性,采取了让回答者预测原始答案,尽量让回答者的答案向原始答案的方向上靠,这样能够让F1提升5.4%
(3)数据集分析:
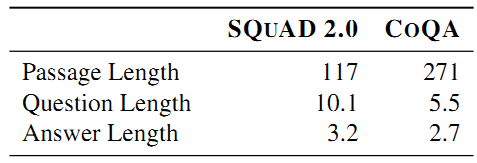
- CoQA与SQuAD 2.0对比:


CoQA与SQuAD区别:
SQuAD中不存在指代词,但CoQA几乎每个部分都包含指代词,体现了CoQA的对话性;CoQA答案形式更自由,问题也相应的更丰富;SQuAD大部分是关于what的问题,而CoQA的问题类型分布更广泛(如上图所示);did, was, is, does and这些词经常在CoQA中见到,但SQuAD中却很少见;CoQA的问题和答案更短(如上表所示,平均:5.5<10.1);SQuAD中包含更多无法回答的问题,CoQA中有更多抽象而无法直接进行提取的问题
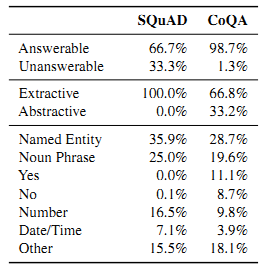
- 对话流程:
作者认为数据库中文章的结构会影响到对话的流程,因此对文章结构进行了统一。参考rationale将文章划分为十块,然后记录对话进行过程中,对十个大块的关注程度的变化情况,如下图所示:

图中,横轴表示对话的轮数(即第几轮问答)纵轴表示对话块的分布。从上往下(红色到深绿)依次为文章的第一块到最后一块,文中的灰色频率带宽度表示块与块之间转换的频繁程度,越频繁的转换,带宽越宽。
由图可知,最开始对话总是集中在前面几块,随着对话轮数的进行,关注点逐渐偏向后面的块(表现为红色部分逐渐减小,下方其他部分逐渐增大)块与块之间的转移表明相邻块之间的转移更加频繁。 - 语言现象
问题与文章和对话历史的关系:
词汇匹配:问题包含至少一个出现在文章中的内容词(9.8 %)
释义:基本原理的释义,同义、反义词、上下义和否定(43.0 %)
语用学:常识和预设(27.2 %)
不依赖于与会话历史的共指,可以自己回答(30.5 %)
包含明确的共指(49.7 % )
没有明确的共指(19.8 %)

6.3 模型
模型任务: 对话反馈问题 + 阅读理解问题(分别针对两个部分及其组合提出baseline)
给定文章
p
p
p,对话历史
{
q
1
,
a
1
,
.
.
.
,
q
i
−
1
,
a
i
−
1
}
\{q_1,a_1,...,q_{i-1},a_{i-1}\}
{q1,a1,...,qi−1,ai−1}
输入:问题
q
i
q_i
qi
输出:答案
a
i
a_i
ai
- 对话模型:PGNet
PGNet:以传统的seq2seq模型为基础,使用包含注意力模型的seq2seq生成答案
将文章,对话历史,当前问题输入双向LSTM的encoder中,在decoder中引入允许从文章中复制词语的复制机制。 - 阅读理解模型:修改版Stanford attentive reader用来预测答案的范围
- 混合模型:
由于Stanford attentive reader无法生成与文章不相重合的答案,因此将上述两个模型进行组合。Stanford attentive reader用于找到文章当中对应问题的依据所在,然后使用PGNet对找到的依据进行自然化,生成形式自由的答案。引用之前的标注,即:
对于问题 Q Q Q,Stanford attentive reader在文章中找到依据 R R R,再由此利用PGNet生成答案 A A A
根据模型实际的表现,基于原模型作出以下调整(简化):
Stanford attentive reader仅输出文章中对应的出处(R)作为问题的答案;
仅将当前问题以及由Stanford attentive reader得到的范围预测作为PGNet encoder的输入
6.4 实验
- 在开发集上调试超参数:使用的历史对话的问答轮数,隐藏层个数,各层隐藏单元的个数,dropout值;
- 对于对话模型,使用GloVw构建词映射矩阵(word embedding)在训练过程中会对矩阵进行更新;
- 对于阅读理解模型,使用fastText进行文本分类
实验结果表明:
各模型中,seq2seq表现最差;Hybrid效果最好;最好的模型比人类表现差23.7%;模型在域外数据集上效果更差,尤其是reddit

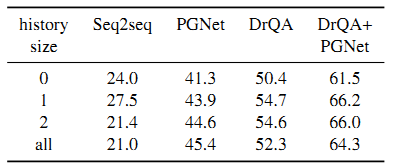
历史对话轮数分析:
模型表现会随着历史对话轮数的增加而降低,PGNet除外。大部分模型在有一轮历史对话的时候模型效果会有一定的提升,但之后会随着历史对话轮数上升而下降。
6.5 讨论
CoQA baseline模型在数据集上的表现为65.1%,与人类表现相比依旧有很大的改进空间,因此作者提出了以下几个改进方向:
- baseline模型对于对话历史的应用只是简单地对历史信息的concatenate,如FlowQA (Huang et al., 2018a)提出了用于处理单论对话的解决方法。
- hybrid模型是范围预测类阅读理解模型和pointer-generator的结合,后者的效果受到前者效果的影响,如果能设计成端到端的模型直接对rationale进行改写,效果可能会更好。
- 可能有更好的将rationale引入到模型训练当中的方式
另外,对数据集CoQA进行改进是另外一个可以考虑的发展方向。
7. 结论
本文对神经读理解的基础(第一部分)和应用(第二部分)以及作者在这方面的贡献进行了较为详细的介绍。
第二章:阅读理解的历史;从兴起到视为监督学习再到神经阅读理解的出现;数据集的完善以及模型的涌现成为该领域快速发展的两大动力;阅读理解的任务;四种主要类型及对应的评估方法。
第三章:神经阅读理解;Stanford attentive reader在CNN/Daily mail完形填空类问题上的应用;Stanford attentive reader在SQuAD上的应用;详细分析数据和结果,了解模型学到的内容;提出在该领域进行改善的思路和方法。
第四章:当前模型在了解文章内部结构上依旧欠缺;在模型上除了准确率之外还有其他需要关注的指标(速度和规模,稳健性,可解释性);SQuAD之后的数据集引入了更多复杂的问题。
第五章:将信息提取和阅读理解结合,构建开放域问答系统DrQA;在多个数据集上对模型进行评估;引入远距离监督(DS)生成样本提高模型表现。
第六章:基于对话的问答系统;构建数据集CoQA;构建模型确认数据集的baseline
【完结撒花,再次膜拜丹琦学姐 *·*】















 4577
4577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









